- +1
光影背景随心换,虚拟视频还能这样拍?上科大本科生论文被ICCV2021接收
原创 Synced 机器之心
机器之心专栏
作者:上海科技大学MARS实验室
只需要在模型中输入单张图片(RGB)和一个含有高动态范围(HDR)信息的照明环境,就能实现更换背景、重打光的效果。
设想你是一个视频创作者,借着绿幕拍了视频,后期换背景时却发现不自然,怎么办?
设想你是一个摄影师,好不容易捕捉到一个难能可贵的时机,却发现还需要补光,如何挽救?
上海科技大学的团队提出了一种全新的解决方法——人像视频重照明(Video Portrait Relighting)方法:使用者只需要在模型中输入单张图片(RGB)和一个含有高动态范围(HDR)信息的照明环境,就能实现更换背景、重打光的效果。模型输出的结果足够逼真,在光影变化时前后依旧连贯;模型运作的性能足够强劲,还能够在移动端实时生成结果。这篇论文目前已被 ICCV 2021 接收。

论文链接:https://arxiv.org/pdf/2104.00484v1.pdf
项目主页:https://zhang-dragon.com/projects/nvpr/nvpr.html

图 1 模型更换背景的输出结果。可以看到,在背景光线变化时,前后的光线变化依旧连贯

图 2 模型更换光影后的输出结果
这个研究主要有以下亮点:
研究者提出了一种基于神经网络的新型实时人像视频重打光方法,使模型的输出在光影变化时足够连贯,效果显著优于现存的最佳模型;
研究者将人像结构信息与光影信息分离,通过自有的时序建模方法和光影采样策略,使得使用者可实时编辑光影;
研究者构建了动态的单帧单一光照的影像数据集(One Light at A Time,OLAT)单帧单一光照。这个数据集包含了 36 位实验参与者共计 603,288 张动态 OLAT 影像,可支持后续的人像与光照研究。

动态、单一光照(OLAT):新的数据集是怎么炼成的?
从监督学习的角度对单张图片应用重打光的难点是数据集的丰富程度,我们需要同一人像在大量不同光照下的对应数据,而实拍几乎是不可能的。
这个问题在 MARS 实验室的支持下得到了解决。上海科技大学多学科人工现实(Multidisciplinary Artificial Reality Studio, MARS)实验室自主研发的穹顶光场(Light Field Stage)由包含 114 个 LED 光源和一台 1000 fps 的 4K 超高速摄像机组成。穹顶光场以多灯光与高速相机的配合,帮助研究者成功采集出动态单帧单一光照(OLAT)的影像数据,解决了人像重打光面临的数据瓶颈。

图 3 穹顶光场(Light Field Stage) 采集数据、应用数据的过程
为了实现高效率的数据采集与处理,研究者也制定了一套数据采集流程、开发了一套数据处理工具链,并最终采集处理了 36 位实验参与者共 603,288 张影像数据,建立了第一个动态单帧单一光照(OLAT)的数据集。

图 4 模型更换光影的工具使用过程
框架方法
人像结构信息与光影信息分离
这篇论文提出的框架以 U-Net 结构作为基础,可以看作是含有跳跃连接的编码器 - 解码器组合。编码器对输入人脸编码出光照信息 L 和结构信息 e ,解码器通过光照信息和结构信息生成对应的人脸。

论文提出了针对人脸结构信息的自监督学习,让同一人脸在不同光照条件下编码出相同的结构信息e ,以便和人脸携带的光照信息 L 解耦。编码器同时对源图像和目标图像(在不同光照下的生成结果)编码出两个隐向量,并优化两个隐向量的距离。
这篇论文提出的框架同时监督网络输出对于人脸的分割 P ,让网络学习人脸的语义结构,以期在未知的人脸上获得更好的表现。
同时,这篇论文还使用对抗生成训练,使用辨别器
加强网络输出的细节。

时间连续性约束 ——动态单帧单一光照的诀窍
通过采集的时间连续的单帧单一光照(OLAT)数据,研究者可以计算出前后帧之间的的光流信息 t,t+1,以此在网络训练的过程中提供额外的时序信息。
这篇论文提出的框架在训练时将多个前后相邻的 OLAT 数据输入给网络,将输出的图像经光流变换后计算损失函数,同时在多次前向传播过程中进行优化。这样的方式使得网络可以让变化光照条件下的人脸序列,经过重打光后在时间上连贯。

这篇论文提出的框架在应用的时候仅需要单帧作为输入,而不需要额外的时间信息,即可以获得具有时间连续性的输出。

光照分布采样
这篇论⽂提出的框架采⽤了 Beta 分布对光照数据集进⾏采样,将不同种类的光照组合,同时模拟光照的⼀致性递变和突变,增强了⽹络的泛化能⼒。选定特殊参数的 Beta 分布对源光照条件 X^i 和目标光照条件 X^j 进行插值,可以使插值集中分布在两种光照条件的附近。这对应了最后的实际应用场景,源光照条件附近的样本对应对了光照编辑,目标光照条件附近的样本对应了光照更换。

这篇论⽂提出的采样分布提高了实际应用时的表现。
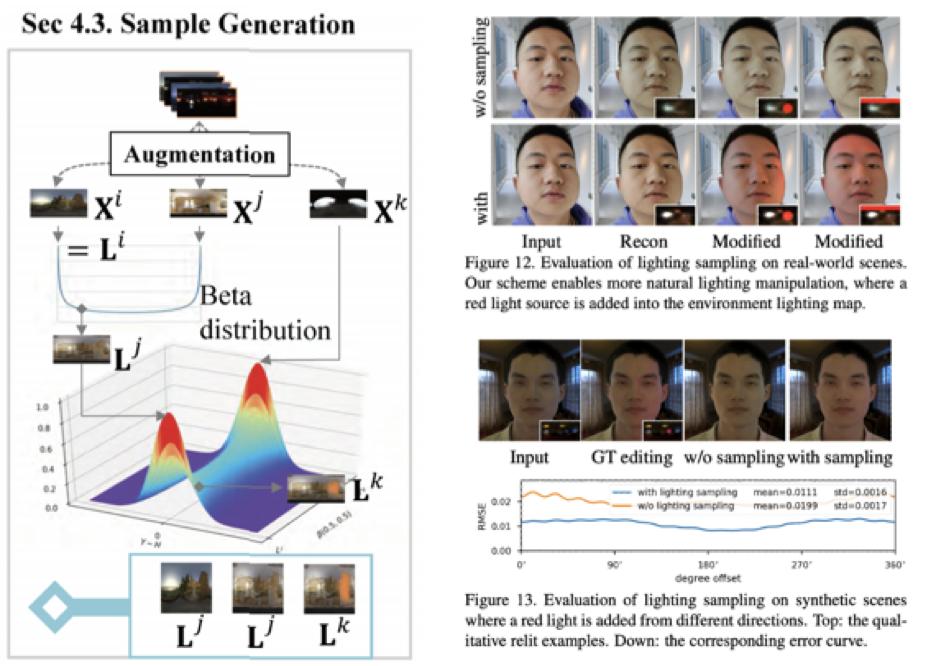
效果比较
研究在动态光照环境下与多种 SOTA 重打光方法进行了比较,均达到了更稳定的视觉效果,并且在实拍场景中也同样奏效。


研究也以输入视频光照变化剧烈程度为变量,对不同的方法进行了定量和定性分析,论文中提出的新方法也达到了显著的稳定效果。


该研究还在 FFHQ 数据集(Flickr-Faces-HQ Dataset,一个广泛使用的数据集)对网络进行了测试,效果如下:

后续工作
研究者表示,他们未来将着重提升该项目中网络对人像细节的表达,将结合穹顶光场采集的毛孔级动态人脸模型数据,进一步提升效果;重打光范围拓展为全身,以适应更广泛的应用场景。
针对以「补光」这一应用需求,研究者也以 Google Pixel 5 中 Portrait Light 功能为蓝本,开发了专门针对手机用户的实时补光网络,能够为肖像照进行不丢失细节的多色彩多光源补光,未来将与手机厂商合作以应用的形式集成入旗舰机型中。

这篇论文的一作为自上海科技大学的大三本科生张龙文与张启煊。两名同学均为上海科技大学多学科人工现实(Multidisciplinary Artificial Reality Studio, MARS)实验室成员,指导老师为许岚和虞晶怡。两位同学联合创立的初创企业——影眸科技,致力于积极推动尖端实验室科研成果的民用化、商业化。探索前沿人工智能、计算机视觉技术在影视制作、大众娱乐市场的推广应用。
NVIDIA对话式AI开发工具NeMo的应用
开源工具包 NeMo 是一个集成自动语音识别(ASR)、自然语言处理(NLP)和语音合成(TTS)的对话式 AI 工具包,便于开发者开箱即用,仅用几行代码便可以方便快速的完成对话式 AI 场景中的相关任务。
8月12日开始,英伟达专家将带来三期直播分享,通过理论解读和实战演示,展示如何使用 NeMo 快速完成文本分类任务、快速构建智能问答系统、构建智能对话机器人。
直播链接:https://jmq.h5.xeknow.com/s/how4w(点击阅读原文直达)
报名方式:进入直播间——移动端点击底部「观看直播」、PC端点击「立即学习」——填写报名表单后即可进入直播间观看。
交流答疑群:直播间详情页扫码即可加入。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《光影背景随心换,虚拟视频还能这样拍?上科大本科生论文被ICCV 2021接收》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

