- +1
12家国产大模型做了一份考公模拟题,一半上不了岸
倒计时10天,300万人的命运的齿轮即将转动。
下周,也就是11月26日,国考笔试正式开考。在一系列社会和经济背景交织下,这次国考人数逼近300万,创历史新高。其中,31万人在审核环节被刷下,能够走进考场的261万人,最终也只有3.96万人有机会可以成功上岸,超过98%的考生沦为炮灰。
围绕大模型考公话题,Yuri用一套国考行测模拟题对12家国产大模型做了测试,其中6家总体正确率65%以下,按照以往国考笔试分数,一般行测题65分以上有进入面试可能。这就是说,一半国产大模型参加考公失败。这其中包括被视为中国最像OpenAI的大模型创业团队智谱AI、腾讯混元大模型以及高调宣布将在2024年上半年全面对标GPT-4的讯飞星火大模型。
最大跌眼镜的是腾讯推出混元大模型,总体正确率34%,排名倒是第一。这样的结果和大厂的身份着实不符,估计鹅厂不擅长小镇做题家吧。
大超预期的是文心一言,在上个月发布的文心一言4.0能力相比此前有明显提升,在这次国考模拟行测题中连对18道!虽然很多人觉得百度不行了,但是百度在AI这块确实在下功夫做事的。
政治意识较强的是360智脑,为了安全,不少问题主动放弃了作答。
宇宙厂字节跳动的豆包大模型,在这次模拟测试中拿下数学分类第一。总体正确率70%以上,基本上可以顺利通过笔试。
以下是大模型考公详细评测内容,AI新智界经作者Yuri授权整理发布。Yuri现任某科技企业AI市场战略,主要关注AI相关的技术进展、行业动态和商业化的情况。
01、测试缘由
上周在群里看到有朋友问国内哪个大模型可以做公考、行测题,于是心血来潮求了一份题目,花了一周左右的时间完成测试,主打图一乐。
提前说明:本测试结果没有任何地缘和公司立场,单从一个用户体验角度评论,仅表示模型在所测题目及同类题目的任务表现,并不能完全代表模型在其他任务上的能力和表现,大家做的是AI大模型、不是做题家,也许这次测试正确的题再测一次也会错误,一次测试结果并不能说明什么,水淹七军了最后也会走麦城,端平入洛收复两京最后还是崖山殉国,省模考了前三最后高考也可能只能去财大。OpenAI在灯塔尖,我们在长城内,大家都有光明的前途呐。
20231115更新:感谢Will在第二张sheet最后一列新增了GPT-4 Turbo(未联网)的测试结果,总体正确率为73.7%。
02、测试题目及方法
使用的题集是群友提供的四海教育《2023下半年笔试套题冲刺班·一期 行政职业能力测验(三)》,从前面的110道题中刨除了需要识图判断的71-80题和83题,总共99道题。
测试采用首次生成的答案,人工不参与干预、没有重新生成的机会(实际测试的时候在第69题因为天工生成卡顿了两次但又实在想看它的结果是什么所以人工点了两次“继续生成”)。
测试提问方式基本上以“下面这道题选什么?”开头,在类比推理部分为了降低模型理解难度改为“下面这道类比推理题选什么?”开头。
03、测试结果
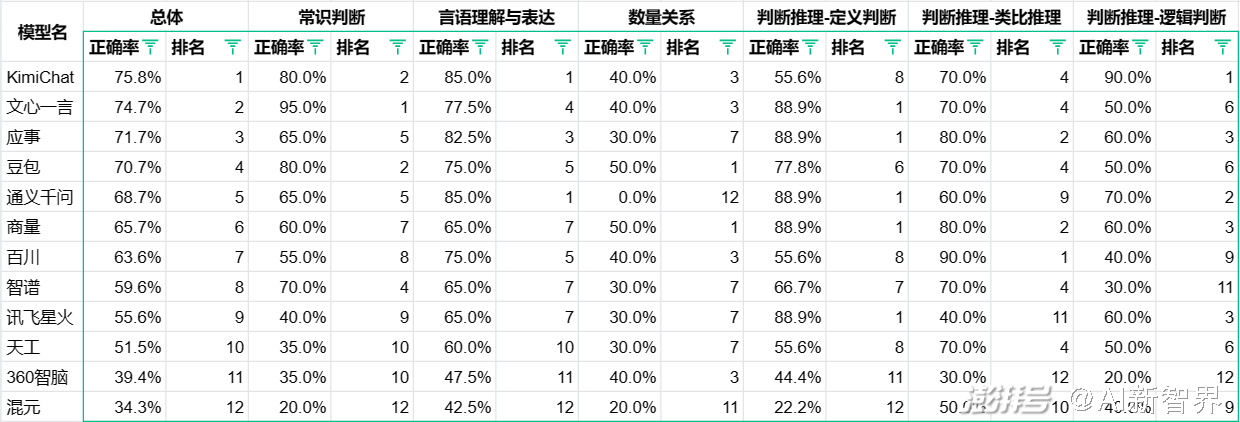
12款国产大模型国考模拟行测题正确率
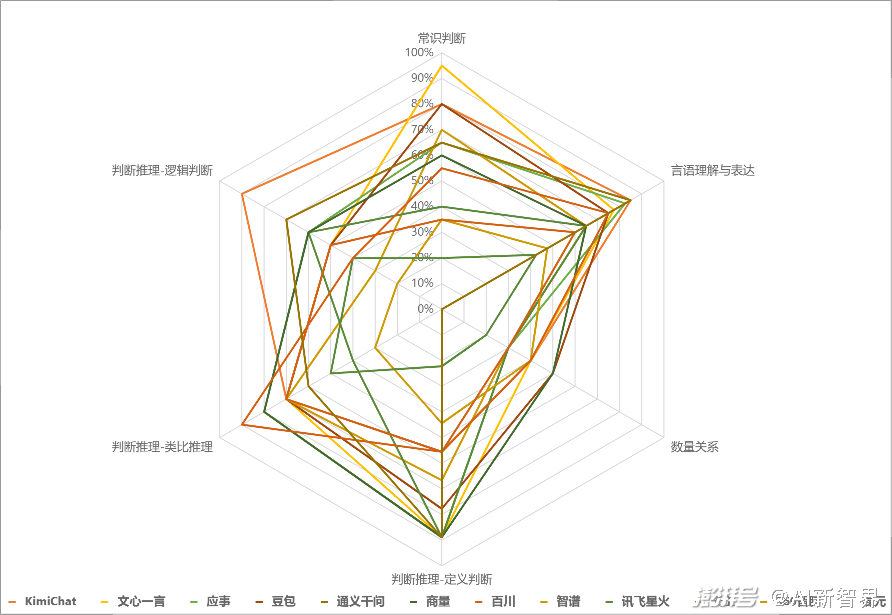
各模型测试正确率雷达图
文心一言
①文心4.0更新之后的效果确实非常超乎预期,尤其是前面18连对的时候,感叹能力确实相较文心3.5提高非常多,看来今年从3.0到3.5再到4.0确实是下了不少功夫的。
②文心也是此次测试中少有的能够不需要开启新对话全部完成作答的模型之一(另外两个是豆包和应事)。
③文心在文本类的任务上回答速度挺快的,基本上能够做到提问后1-2秒就开始作答,且不需要让页面停留在文心的网页还会继续作答,但是在数量关系和计算问题的时候反应就会变慢,其中有一道题甚至思考了20s左右才开始答题,差点以为要翻车(虽然还是答错了),到后面问更长段的文本问题文心也会出现跳转页面回来之后还在生成的情况,不知道是不是对长文本和数学题一样还需要更多的思考时间呢。
④文心总体回答下来每个问题基本上都会比较完整地说出自己的分析思路,比较有条理,但是有时候话真的有点子多。回答数学问题的时候文心和各个模型都会出现一个问题,就是算出来的结果选项中没有、会选择一个和计算出来的答案最接近的一个数,这倒是有点像真人的哈哈。其次就是各种胡诌的选择,比如69题计算出来的答案是-17,然后选择的答案是40,确实挺点点点的。
360智脑
①太安全了,尤其是前十道题,每次输入都会担心被封号,后面很多问题也选择了不回答呢,不知道是什么原因,奇怪。
②回答轮次上来说经常答不满20轮的上限,后面看截图会发现好多次都是提问几个问题之后模型就让开启新对话,这是为什么呢。
③生成速度上倒是挺快的,但是光快是不够的。
④360回答也会给出自己的分析思路,但是总体回答准确性还是不够好,尤其是第59题的“建国之本”选择上在其他模型都选“汴河”的情况下就它选了个“六百万石粮食”,一口老血吐出来,我也不知道古代是哪个朝代会靠600万石粮食建国立本哈哈哈,在测试到后面已经是唯二我会期待能跟其他模型选出不一样的答案的模型了,另一个是混元。
讯飞星火
①星火3.0的结果倒是不及我预期了,因为星火2.0发布之后我对它的印象都不差,它的文档解读功能在Kimi发布之前一直是我的首选(尤其是在Anthropic疯狂封号之后),这次排名靠后也有点意外的。
②回答轮次上星火只会在遇到无法回答的问题才会停止对话要求开启新对话,所以不知道它的理论提问轮次上限是多少,拎唔清。
③生成速度上也还可以,在提问2、3秒之后它就会开始作答,略有卡顿但是不影响,也不需要停留在网页等它生成完成。
④文本类的任务星火不会每个问题都详细阐述思路,数学计算类问题会有列式计算的过程,但是也会出现选临近答案和乱选的情况(比如66、67题),此外读图题不知道为什么反馈大明北元图有敏感信息,哪儿敏感了。看来大家都道阻且长。
豆包
①豆包的整体表现在预期内,毕竟从发布到现在我觉得能力都还挺不错的,而且交互界面也是各个模型里我最心水的,也许是因为有个姐们儿的虚拟形象在吧(见下图)。

②回答轮次也是一遍过,除了第8题识图暂时不行以外没有豆包不能答的题。
③生成速度一直都不错,在做数学题的时候反应也很快,也不需要停留在网页内才能生成。
④文本类的任务回答豆包也基本上都会给出回答思路,在多空选择的时候也会按“第一空bulabula......第二空bulabula......”来逐条分析,比较有条理,数学计算类在豆包刚发布的时候就测试过效果、尽管逊色于GPT但是在国内算不错了,这次也拿到了数学分类的第一也算意料之中,但是仍存在乱选的问题(比如68、69题)。
天工
①天工整体的表现感知比较中规中矩,没有什么特别大的亮点,但是几次回答开始前都会有一个队列加载的进度显示(见下图),不觉会让人想真的有那么多人在排队用么?还是算力问题?我也母鸡。

②多轮对话上天工除了回答不了的问题需要重新开启对话之外,在有些问题上也会重新开启对话,不知道是不是我重新加载网页的问题还是未知原因。
③天工的生成速度还OK,最开始接也基本不需要网页停留在天工页面就能自动生成完成,但是到后面的一些逻辑理解问题问完其他的模型之后回来看天工还在生成,速度变慢了。
④文本类的问答天工也会给出解释思路,但也有偷懒直接给出答案的情况,其次就是同类问题的49和50题为什么49题直接不会做、但50题就做对了呢,不知道。在数学方面因为云栖大会上方汉总专门提到天工有一个数学模型,因此还挺期待它的任务表现的,也在这次测试中唯一一次人工干预让模型继续生成完,想看看它写完最后到底算出个啥(见下图)。虽然天工做数学题确实会写很长段的列式和计算,但是正确率还是很感人,甚至在66题它想把提问的三角形画出来(尽管最后弹出一张奇怪的图),可以看出它真的很努力了。

百川
①百川在我之前几次斗蛐蛐中都表现出文理通顺、逻辑清晰、有礼貌而好用,文本类任务尤其优秀,除了还没有app端使用不太方便以外都挺好的,但这次整体表现只能说不及预期罢。
②这次测试百川总共用了三轮对话,除了前两次比较短之外,第三次就完成了所有的问题测试,单次对话至少在80轮以上应该是没问题的。
③回答速度上也比较快,也不需要停留在网页上才能继续生成,在答题上百川属于话不多型的模型,但是在输入完问题之后百川会把提问完全压缩成一段话,在视觉上看着可能不够清晰了。
④文本类的问题回答上最开始还会比较详细地回答该题目属于考察什么要点的题目,但是到测试后期更多就是直接选答案、少有介绍思路,我想它大抵是乏了吧,最让我吃惊的应该是它是几个模型里率先在单选题里做了多项选择的(天工、商量、混元:OK,学会了。),在第3、4题连续做了多选,真是一口老血吐出来。其次在做数学题的时候也没有给到计算思路,有时候不太方便了解计算过程,有待改进(也可能是我问得太简单or没有追问)。
商量
①商量自从上半年发布到现在好像除了AI斗蛐蛐也很少主动用,可能还是因为不知道到底有啥亮点以及汤厂的传播做得比较保守吧,果然还是要多做做广告公关不然都不知道你到底哪里行,这次测试拿到了上半场排名也算是预期之外。
②商量大概用了六次对话环节,有很多时候的开启对话都不知道是因为问题里的什么原因,很神秘。
③商量文本类问题在回答的时候有些慢,主要体现在写每段话之前都要顿个3、4秒,感觉还在思考组织语言,但是不需要停留在网页才能继续生成,且问题回答很长的时候可以收起回答,一些便捷小功能。
④文本类题目回答的时候大部分商量都不会说很多话,部分文本类题目会分步说明,数学计算部分商量虽然拿了第一名,但是也只给了答案、没有给出具体计算思路,整体的回答风格都比较简略。
应事
①体验过MMX前代的inspo和万卷,一直以来对他们家的产品体验和技术能力都充满好感(除了有一次封我的号),这次进入前三也不愧为国内大模型创业团队Tier1里最闷声发大财的选手,毫不意外。
②应事本次测试也是一轮过,主要是因为它不能回答的问题直接无法输入,只能跳过继续输入问下一个题。
③应事此次测试的回答速度确实快,原因就是它就只回答选项,一点思路一点解释也不会告诉你,真的很高冷。但就我之前使用应事的体验下来我觉得它的回复速度中规中矩吧,在回答前会思考几秒,在回答过程中也会偶尔有卡顿。此外,尽管回答简单到只给一个字母选项,但是测试里应事还是会每个答案都附上音频回答,多模态YYDS。
④应事的文本能力很强,在测试中也会发现文本类任务一直都是比较靠前的排名,数学稍显拉胯但是每个模型说实话数学都不够好,总体其实都挺靠谱的,所以在测试时会一直怀着“这道题应事该做对了吧~”的念想,但也会有“这道题应事居然会做错?”的情况,这就是大模型现在的现状罢。
智谱
①另一家明星创业公司,在清言发布后试用过一阵,总体感觉能力应该不算差,尤其是文档解读能力一度我觉得是超越了星火的,但是此次测试下来感觉应该也没发挥真实实力。
②智谱此次测试用了四五轮,因为每次遇到不能答的问题之后就会重启对话。
③生成速度部分应该是智谱最值得被批评的一点(maybe),首先是智谱的内容生成必须停留在它的网页上,一旦跳转到其他网页上它就不继续生成了,其次就是智谱应该是此次测试里话最多的模型,虽然逐个选项分析确实内容结构完整、有理有据,不过有时候也略慢。再次智谱的页面提问之后问题会折叠、可以点击展开看全问题,同时鼠标放在问题上可以直接复制文字到输入框,一些便捷的小功能。
④文本类任务智谱看上去会有很清晰的思路和逐条分析在,但实际上很多分析都不够准确,同时在识图题上不能解析出来提问的图片,看来还需要再修炼修炼内功,数学部分会列式计算,但是结果感人。
通义千问
①通义这次的表现可以说是超出我预期的,因为在今年9月专门测试的时候问的文本和数学问题都回答得很糟糕,只能说这次测试表明通义的文本能力确实有了不小的加强,但数学却并没有超出预期表现。
②通义测试用了三轮对话,但实际上前一对话结束之后还是可以继续提问滴,并且第三轮对话基本上就把测试都做完了,所以单轮应对70、80次问答应该是完全没问题的。
③通义文本类的回答速度也很快,提问后1、2秒就一开始作答,也不需要停留在页面内,不错子。
④文本类任务通义这次回答的都挺不错的,在最开始的时候很多问题都会以“根据我所掌握的知识库”开头、比较有条理,但是到后面的问题都简略到只回答选项答案了,乏了+1。然后,在图片解析的时候我也不明白为啥大明北元地图会被要求换图片,拎唔清。不过,通义数学类的表现不出意外,10道题全错,心说你能不能支棱起来啊,数学全错还能拿到综评第五,哪怕多对几道没准就能超过豆包和应事了,怒其不争。
混元
①此次测试最大跌眼镜的模型、没有之一,360的测试结果在我预期之内,但是混元的测试结果真的远超我预期之外了,是我Q币充得还不够多吗QAQ?或者混元不擅长做小镇做题家也说不定。
②混元共用了7轮对话来完成这次测试,测试下来混元单次对话的上限是30次,多了之后会出现过长提示。(见下图)

③混元的生成速度倒是挺快的,和通义差不多,同样也不需要停留在页面内。
④混元开幕雷击前十道题10连错的时候我是完全没想到的,我大概半年多前就一直在期待宇宙厂和鹅厂的模型、觉得他们也许会带来惊喜感,宇宙厂的达到了预期,但是没想到鹅厂的模型居然是酱紫。说实话我挺喜欢混元的回答风格的,有思路、有条理、话不多,可惜分析出来很多都是错的,其次数学也会列式计算,但是当看到第62题计算概率算出来一个“-95”的答案真是一言难尽、心凉半截,在最后测试的时候也是抱着“看看这道题混元能不能做对呢”的心态去测试,混元也确实不失所望在有些其他模型都能做对的题做错。就在我写总结的时候又想给它个机会测了下图的问题,结果大家自己看吧(宋理宗的棺材板都盖不住了),希望混元未来能够支棱起来吧。

KimiChat
①在Anthropic疯狂封号的时候Kimi终于出来了,拯救了我的长文本和文档解读,之前还专门拿国内能够做文档解读的几个模型文心、星火、智谱、通义跟Kimi一起斗蛐蛐,Kimi也一直都是我心目中的第一名(无奖竞猜最后一名是谁)。从开始使用到现在Kimi一直都好评不断,同时遇到很多问题也会直接给团队反馈,这次测试拿到第一也让我对Kimi的未来有了更多的期待了。
②因为主打长文本,所以我其实还挺期待Kimi可以一轮对话回答全部的,但是32题Kimi无法回答导致对话结束,于是只能新起一个对话,算是此次的遗憾。
③Kimi的生成速度并不算最快的,中规中矩,在答题的时候前摇大约4、5秒然后开始答题,期间还会用搜索寻找参考资料(比如15、29题等),确实会拉长生成时间,但是有趣的是Kimi的搜索都是相对有效的,甚至有几次还找出了真题,算是有利有弊。
④Kimi关于文本类问题的回答都比较简单,没有过多的解释过程,如果对于只需要答案的人来说也许没问题,但是如果是对需要思考过程的人是不够的,对于数学类问题会列式计算写出详细过程,但是准确率依然和大家一样感人,也会出现像70题那样计算出的答案是5/32但是选了16/21这个结果的情况。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

