- +1
谷歌继续开源新AI框架,可实现手机高效实时3D目标检测
如何从2D图像中做3D目标检测,对于计算机视觉研究来说,一直是个挑战。
3月12日,谷歌AI在其官方博客上发布了一款名为MediaPipe Objectron的算法框架,利用这个算法框架,只要一部手机,就能实时从2D视频里识别3D物品的位置、大小和方向。这一技术可以帮助机器人,自动驾驶汽车,图像检索和增强现实等领域实现一系列的应用。
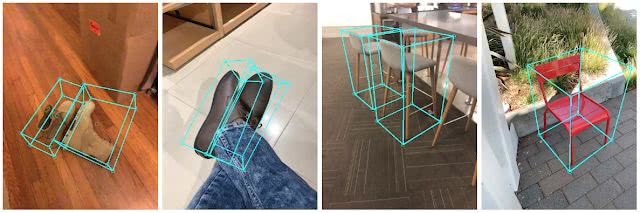
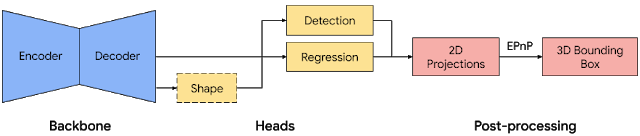
分开来解释,MediaPipe是一个开源代码跨平台框架,主要用于构建处理不同形式的感知数据,而 Objectron在MediaPipe中实现,并能够在移动设备中实时计算面向对象的3D边界框。
在计算机视觉领域里,跟踪3D目标是一个棘手的问题,尤其是在有限的计算资源上,例如,智能手机上。由于缺乏数据,以及需要解决物体多样的外观和形状时,而又仅有可2D图像可用时,情况就会变得更加困难。

为了解决这个问题,谷歌Objectron团队开发了一套工具,可以用来在2D视频里为对象标注3D边界框,而有了3D边界框,就可以很容易地计算出物体的姿态和大小。注释器可以在3D视图中绘制3D边界框,并通过查看2D视频帧中的投影来验证其位置。对于静态对象,他们只需在单个帧中注释目标对象即可。
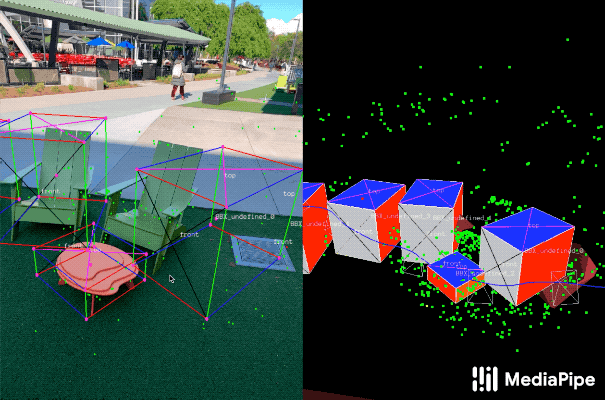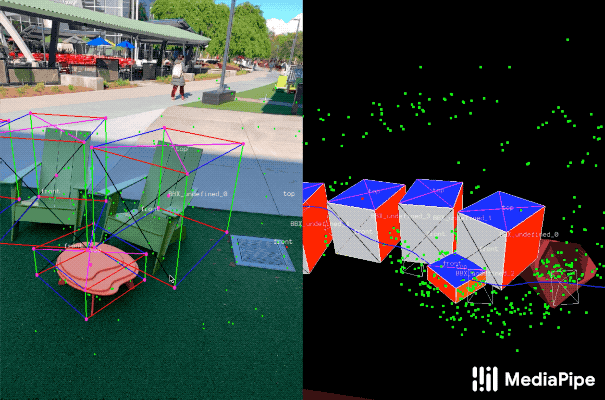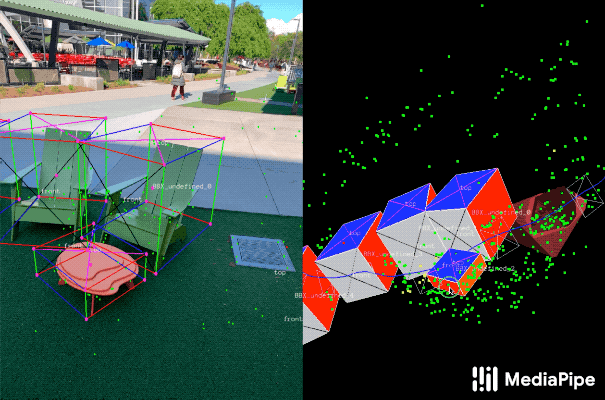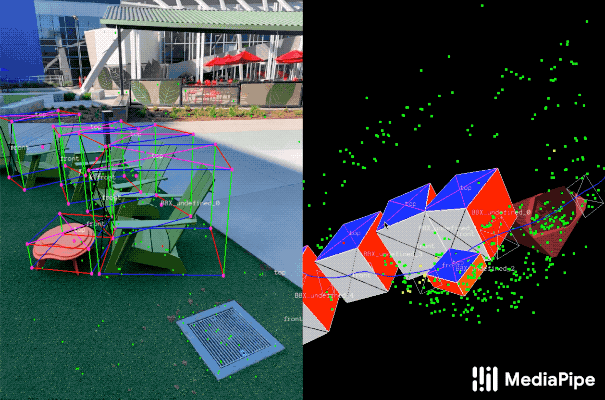
为了补充现实世界的训练数据以提高AI模型预测的准确性,该团队还开发了一种名为AR Synthetic Data Generation(增强现实合成数据生成)的新颖方法。它可以将虚拟对象放置到具有AR会话数据的场景中,允许你利用照相机,检测平面和估计照明,来生成目标对象的可能的位置,以及生产具有与场景匹配的照明。这种方法可生成高质量的合成数据,其包含的渲染对象能够尊重场景的几何形状并无缝地适配实际背景。

通过上述两个方法,谷歌结合了现实世界数据和增强现实合成数据,将检测准确度度提高了10%。

准确度的提升是一方面,谷歌表示,当前版本的Objectron模型还足够“轻巧”,可以在移动设备上实时运行。借助LG V60 ThinQ,三星Galaxy S20 +和Sony Xperia 1 II等手机中的Adreno 650移动图形芯片,它能够每秒处理约26帧图像,基本做到了实时检测。
接下去,谷歌团队表示:" 我们希望通过与更多的研究员和开发者共享我们的解决方案,这将激发新的应用案例和新的研究工作。我们计划在未来将模型扩展到更多类别,并进一步提高设备性能。"



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

