- +1
剖析用于人口健康管理的算法中的种族偏见
原创 政光景 定量群学

引言
人们越来越担心,算法可能会通过算法建构者通过训练算法的数据来重现种族和性别差异。实证研究越来越支持这些担忧。例如,高薪职位的求职广告不太可能呈现给女性,搜索独特的黑人名字更有可能触发逮捕记录的广告,而首席执行官等职业的形象搜索产生的女性形象更少。
但通常对算法偏差进行实证研究是困难的,因为大规模部署的算法通常是(政府或企业等机构) 专有的,这使得研究人员很难直接了解算法,并对它们进行分析。研究人员必须“从外部”工作,通常需要他们有很大的独创性,并求助于审计研究等聪明的变通办法。因此,人们对算法机制的理解通常依赖于理论或是研究者自创算法的训练与试验。
在这项研究中,研究人员利用了一个丰富的数据集,该数据集部署在全美国范围内,每年应用于大约2亿美国人,大型卫生系统依靠这种算法将患者筛选为“高风险护理管理”(high-risk care management)项目的补助对象。大多数卫生系统将这些项目作为人口健康管理工作的基石,它们被广泛认为能够有效提高健康管理结果和满意度,同时降低成本。
卫生系统做出了一个关键的假设:那些有最大护理需求的人将从该计划中受益最多。在这种假设下,筛选项目支持对象问题变成了一个纯预测策略问题。然后,开发人员根据过去的数据构建算法,以预测未来的医疗保健需求。
数据和分析策略
通过与一家大型学术医院的合作,研究者确定了2013年至2015年间登记的所有初级保健患者。研究主要兴趣是分析白人和黑人病人之间的差异。研究者通过使用基于患者自我报告的医院记录来形成种族分类。在本研究中,任何被确定为黑人的患者都被认为是黑人。在其余的患者中,那些自我认定为非白种人(如西班牙裔)的患者也被考虑在内。其他剩余的人群则被认为是白人。
该研究的主要样本包括 6079名自认为是黑人的患者和43539名自认为是没有其他种族或民族的白人患者,并分别观察了他们11929和88080个患者年(1个患者年代表一个日历年中为单个患者收集的数据)。样本中71.2%的人参加了商业保险,28.8%的人参加了医疗保险,平均年龄为50.9岁,其中63%为女性(见表1)。
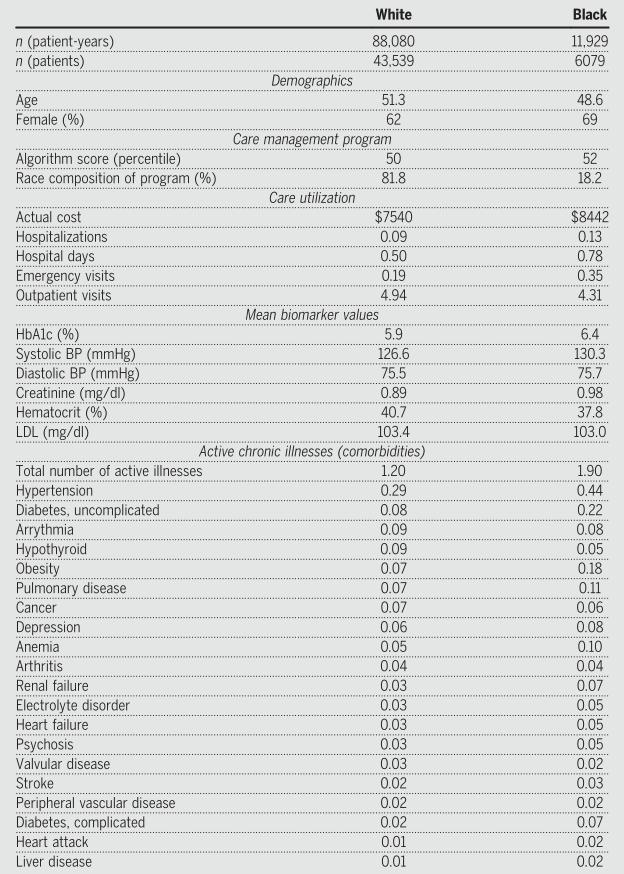
表1 样本的描述性统计(分种族)
注:BP表示 blood pressure;LDL表示 low-density lipoprotein。
对于这些患者,研究者获得了每个患者年生成的算法风险评分。超过第97百分位的患者将被自动识别为项目的登记对象。那些风险评分超过55%的人会被推荐给他们的初级保健医生,医生会根据病人的背景数据,考虑患者是否参选该计划。该研究重点关注算法在现实世界中最相关的指标上,这些指标与算法偏差校准紧密相关(形式上,比较黑人B和白人W,E[Y|R,W]=E[Y|R,B]表示不存在偏差)。该研究将患者i在第t年的算法风险评分(Ri,t)(根据前一年的保险索赔数据Xi,t-1计算得出)与患者的实际健康数据(Hi,t)进行比较,评估算法风险评分在健康结果评估中的校准情况。该研究还探讨了算法在成本Ci,t方面的校准情况。健康的测量是采用电子健康记录数据中的诊断数据、实验室生物测量数据和反映慢性病严重程度的生理指标。成本的测量采用的保险索赔数据,包括门诊和急诊、住院和医疗保健成本。
基于风险得分的健康差异
研究首先分种族计算出衡量健康状况的一个总体标准,即活跃慢性疾病的数量(或“共病评分”,这是一种在医学研究中广泛使用的指标),并以算法得出的风险评分为基准进行分析。图1A显示,在相同的算法预测风险水平下,黑人的疾病负担明显高于白人。
预测差异对患者意味着什么呢?算法分数是决定患者未来是否参加护理项目的关键因素。因此,正如研究者所料,健康程度较低的黑人与健康程度较高的白人的风险得分相近,这就是项目筛查中存在重大偏差的证据。
该研究进一步通过模拟一个基于风险的的但健康没有差距的反事实世界来量化地展示这一点。具体来说,在某个风险阈值下,识别出Ri > a的边缘上白人患者(i),并将该患者的健康状况与Rj < a的边缘下黑人患者(j)的健康状况进行比较。如果Hi > Hj(即根据慢性疾病的数量测量的健康状况),将(更健康但在边缘上的)白人患者替换为(病情更严重但在边缘下的)黑人患者。该模拟一直重复这个过程,直到Hi = Hj,以模拟一个黑人和白人之间没有预测偏差的算法。图1B显示了模拟的结果:在所有高于第50百分位的风险阈值下,该程序将显著增加黑人患者的比例。
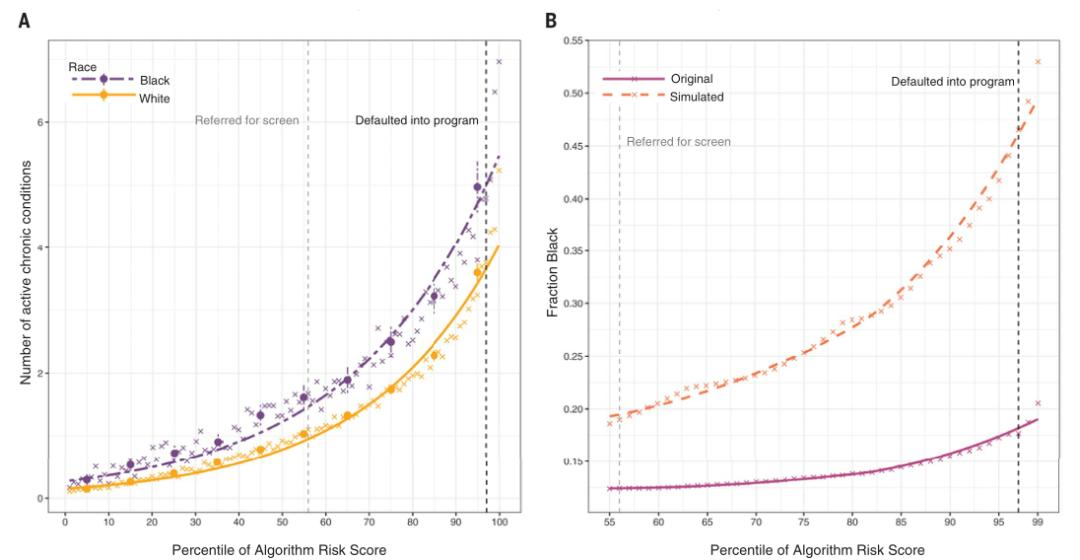
图1 按种族划分的慢性病数量与算法预测风险的对比
然后,该研究通过更多维的生物标志物来衡量患者的健康状况,这些生物标志物用来衡量最常见的慢性病的严重程度(如表1所示)。在所有这些重要的健康指标中——代表糖尿病、高血压、肾衰竭、胆固醇和贫血的严重程度——研究发现,在任何算法预测水平上,黑人都比白人更不健康(如图2所示),黑人患有更严重的高血压、糖尿病、肾衰竭、贫血和高胆固醇。
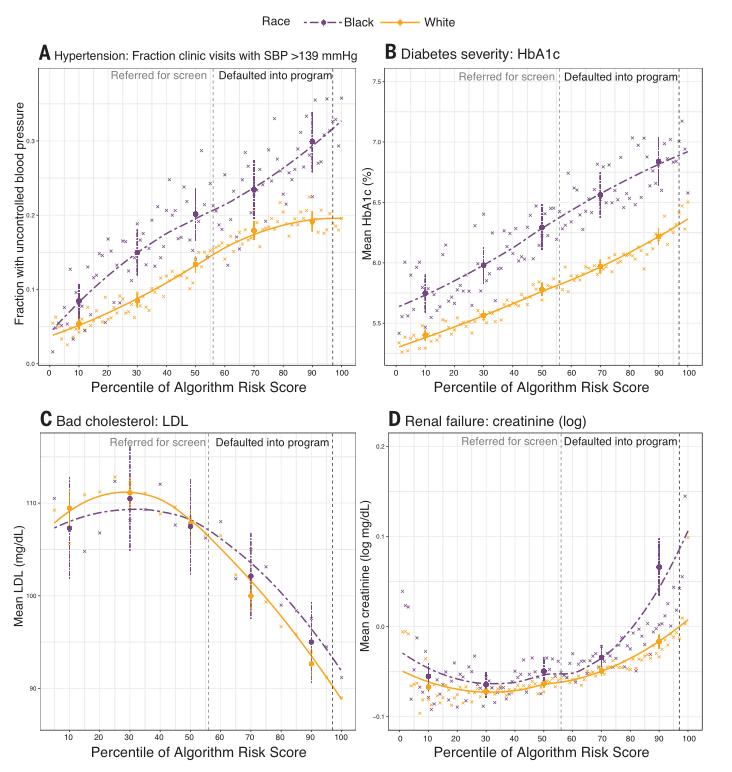
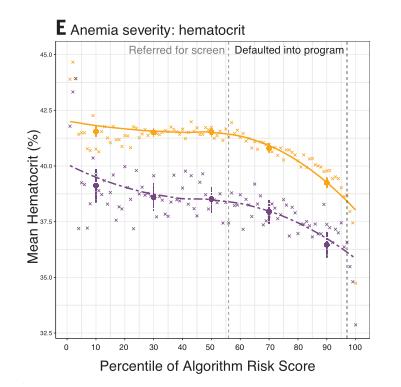
图2 分种族的健康生物标志物与算法预测风险(A至E)
算法偏差的产生机制
该研究使用的数据集的一个独特点是,研究者可以知道算法的输入和输出以及它的目标函数,这为研究偏差产生的机制提供了机会。该算法采用了一大组t-1年的原始保险索赔数据Xi,t-1:基础人口变量(例如:年龄,性别),保险类型,诊断和程序代码,药物和详细的成本。值得注意的是,该算法特别排除了种族。该算法使用以上这些数据来预测Yi,t。在这种情况下,该算法将t年的医疗总支出(为简单起见,研究用“成本”Ct表示)作为标签。因此,算法对健康需求的预测实际上是对健康成本的预测。
作为对这一潜在机制的第一次检验,研究计算了已实现成本C相对于预测风险得分R的分布。在这种情况下,可以称该算法是无偏的。图3A显示,在算法预测风险的每一个级别,黑人和白人在接下来的一年中(大致)有相同的医疗成本。总之,研究发现在相同的预测风险得分的情况下,黑人和白人的医疗成本相似,但健康水平差距明显。一方面,这是令人惊讶的一个结果,因为一般情况下,医疗保健费用和健康需求是高度相关的,因为正常情况而言,病情越严重的患者需要和接受的护理越多。但另一方面,在需要医疗保健(即健康水平)和接受医疗保健(实际医疗成本)之间,白人和黑人的差距是显而易见的(如图3B所示)。在同样的健康水平下(同样以慢性病的数量来衡量),黑人产生的成本比白人更低——平均每年少1801美元。这个结果表明,算法偏见背后的驱动力是,即使我们考虑到具体的共病,在同样的健康状况下,黑人患者产生的医疗费用更少。因此,对成本的准确预测必然意味着对健康的种族偏见。
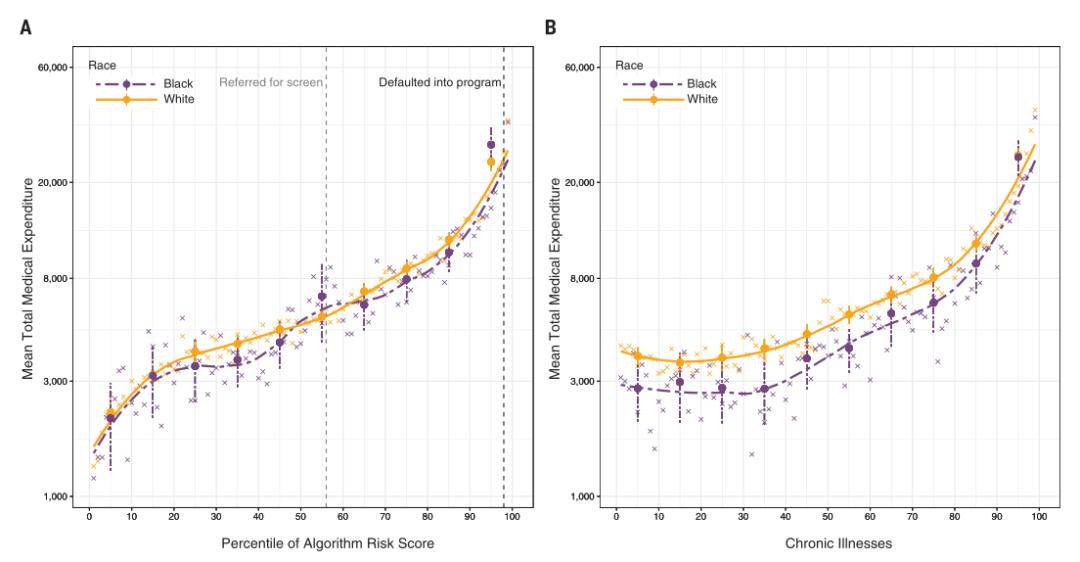
图3 分种族——医疗成本vs算法预测风险、医疗成本vs健康程度
标签选择实验
上述的研究发现强调了选择算法所基于的标签的重要性。一方面,算法制造商预测未来成本的选择是合理的:该计划的目标,至少部分是为了降低成本,并且有理由认为未来医疗成本最大的患者可以从该计划中获得最大的利益。另一方面,未来成本绝不是唯一合理的选择。例如,护理管理项目的证据表明,它们并不是为了在全球范围内降低成本。相反,这些项目主要致力于防止导致灾难性卫生保健利用的急性健康代偿失调(事实上,它们实际上致力于增加其他类别的成本,如初级保健和家庭卫生援助)。因此,可避免的未来费用,即与急诊和住院相关的费用,可能是一个有用的预测标签。或者,与其预测成本,也可以简单地预测一个健康指标,如活跃的慢性健康状况的数量。因为该项目最终旨在改善这些疾病的管理,与他们接触最多的患者也可能是一个有希望部署预防性干预措施的群体。
通过对数据集的一系列实验,就可以了解标签选择如何影响预测性能和种族偏见。研究开发了三种新的预测算法,它们都以相同的方式进行训练,以预测以下结果:t年的总成本(这是根据研究者自己的数据集而不是国家训练集进行的成本预测)、t年的可避免成本(由于急诊和住院产生的费用)和t年的健康状况(通过当年突发的慢性疾病数量来衡量)。研究在一个随机的⅔训练集中训练所有的模型,并且只显示来自⅓测试集的所有结果。此外,与原始算法一样,研究者将种族变量从特征集中排除。
表2显示了这些实验的结果。第一个发现是,所有的算法都表现得相当好,不仅在训练集上表现得好,在其他结果预测上也表现良好:所有算法的结果在97百分位或以上是非常相似的。各种算法表现的最大差异体现在成本预测上:从预测的总成本来看,成本预测器在第97个百分点或以上产生的成本比例为16.5%,而慢性疾病预测器为12.1%。
然后实验测试了标签选择偏差,其定义类似于上面的校准偏差:对于两种被训练来预测Y和Y'的算法,并使用t来作为高风险组的阈值,实验将测试p[B|R>τ]=p[B|R'>τ](这里p表示概率,B表示黑人患者)。实验发现,最高风险群体的种族构成在不同算法之间的差异比成本差异要大得多:处于或高于这些风险水平的黑人患者比例从基于成本预测值的14.1%到基于慢性疾病预测值的26.7%不等。

表2 用替代标签上训练的预测器的性能
算法与人类判断的关系
如上所述,该算法不能单独用于做计划的注册决策。相反,它被用作一种筛查工具,部分是为了提醒初级保健医生注意高危患者。具体来说,对于处于或高于某个预测风险水平(第55百分位)的患者,医生会收到来自患者电子健康记录和保险索赔的背景信息,并被提示考虑是否将他们纳入该计划。因此,已实现的注册决策在很大程度上反映了医生对算法预测的反应,以及与资格相关的其他因素。
表3显示了参加该计划的人员的统计数据,占观察样本的1.3%:参加计划的人员中有19.2%是黑人(而整个样本中有11.9%是黑人),占所有费用的2.9%,占整个样本中所有活动慢性病的3.3%。然后研究进行了四次反事实模拟,这些模拟仅使用可观察的因素,而不是许多未观察到的也影响注册的行政和人为的因素。首先,实验在原始算法预测的风险区间的每个百分位数内计算实际的项目注册率,并在每个风险区间中随机抽取患者进行注册。该模拟模拟了以算法分数为条件的“种族盲”注册,会产生18.3%的黑人注册人口(而观察到的比例为19.2%;P = 0.8348)。第二种方法不是进行随机抽样,而是在一个风险区间内对那些活动期慢性疾病预测数最高的患者进行抽样(使用上述的实验算法),这将产生26.9%的黑人人口。最后,实验将以上两种方案与简单地将预测成本最高或活动慢性疾病数量最高的患者分配到该计划(也使用上述算法)进行比较,这将分别产生17.2%和29.2%的黑人患者。因此,尽管医生确实纠正了算法的一小部分偏差,但他们贡献的程度远远少于因为使用不同标签训练算法而造成的偏差。

表3 医生的决策VS算法预测
讨论
无论是在卫生部门还是在其他地方,归因于标签选择的偏差是一个理解算法中偏差的有用的框架,这是因为标签通常反映了结构不平等。这种偏差产生机制尤其有害,因为它可能来自合理的选择:在考虑整体预测质量的传统指标中,成本似乎是健康的有效代理指标,但仍然产生很大的偏差。
完成上述分析后,研究者联系了算法制造商,对研究的结果进行了初步讨论。作为回应,制造商独立复制了研究人员对其3695943名商业保险患者的数据集的分析。这项工作进一步证实了研究的结果——通过在他们的数据集中计算的预测偏差的一项测量,在同样的风险评分条件下,黑人患者比白人患者多患有48772种活跃的慢性疾病——这说明了偏差是如何在无意中产生的。
为了解决这个问题,研究者和算法制造商开始一起试验解决方案。第一步,研究人员建议使用现有的模型基础设施(样本、预测器、训练过程等),但改变标签:新创建一个将健康预测与成本预测相结合的指数变量,而不单是未来成本。根据风险评分,这种方法将黑人过度活跃的慢性疾病的数量减少到7758例,偏差减少了84%。在这些结果的基础上,研究人员与算法制造商正在建立一个持续的合作关系,将表3的结果转化为一个更好的基于多维度健康指标的预测器,目标是在未来一轮算法开发中应用这些改进。这些结果表明标签偏差是可以修复的,而不需要改变拟合算法的程序。相反,人们必须改变为算法提供的数据——特别是给它的标签。生成新的标签需要对相关领域的深入理解,识别和提取相关数据元素的能力,以及迭代和实验的能力。
推荐文献
Obermeyer, Z., Powers, B., Vogeli, C., & Mullainathan, S. (2019). Dissecting racial bias in an algorithm used to manage the health of populations. 366(6464), 447-453. doi:10.1126/science.aax2342 %J Science
推荐人
政光景,中山大学社会学专业在读博士。研究方向:计算社会学(文本分析方向)、死亡社会学、道德社会学。

原标题:《剖析用于人口健康管理的算法中的种族偏见》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

