- +1
清华获国际首届深度元学习挑战赛冠军,准确率超第二名13%
随着机器学习解决实际问题的日益复杂化,元学习近期受到越来越多的关注,已成为人工智能领域最热门的研究方向之一。
近日,在国际人工智能顶级会议AAAI 2021上,清华大学计算机系朱文武教授团队取得AAAI 2021国际深度元学习挑战赛(MetaDL Challenge)冠军。该团队在最终阶段的隐藏测试数据集上取得了40.4%的准确率,以高于第二名13%性能的领先强势摘得桂冠。
参与该项目的清华大学计算机系助理教授王鑫对澎湃新闻(www.thepaper.cn)记者介绍,元学习是自动机器学习的一个分支,旨在利用算法在旧任务上的表现(即元数据)来学习到某种经验,以使得模型在新任务上学得更快、更好。
“元学习模仿了人类学习的过程,利用过往任务上得到的相关经验,来更快地适应和学习新任务。元学习被广泛应用于少样本监督学习、强化学习、冷启动推荐等跨任务迁移的应用场景,以应对真实场景中目标任务环境动态变化、训练数据不足所带来的挑战。”
目前,谷歌、微软、亚马逊等国际巨头已将元学习算法应用到自己的产业链之中,国内许多知名公司,如腾讯、百度、字节跳动等,也不断完善自己的元学习算法和系统。
此次MetaDL挑战赛为元学习领域举办的首届比赛,由第四范式和微软联合举办,并登陆人工智能领域顶级会议AAAI 2021。本次赛事有近一百支队伍参赛,内容为图像分类领域中的小样本学习问题。
小样本学习是目前机器学习国际前沿正在解决的问题之一,是元学习的一个重要应用场景,而基于小样本的深度元学习将更加复杂,面临巨大挑战。与以往的小样本学习不同,本次比赛同时考察元学习算法本身的泛化性和自适应性,对算法在各个场景下的有效性进行测试。
朱文武教授团队介绍,本次比赛主要有三个方面的挑战。
首先,如何使模型具有快速适应小样本新任务的能力?在这次比赛中,参赛者提交的模型拥有两次训练过程:元训练过程以及测试训练过程。在元训练过程中,模型必须提炼出该数据集的元知识以及最佳的学习方法,来确保模型在测试训练过程中能快速学习并防止过拟合。
第二是时间以及空间约束。本次比赛拥有对时间以及空间的约束条件。总时长不超过2小时,总GPU资源占用不得超过4张英伟达的8G M60 GPU。这要求参赛者提供的模型必须高效、轻量地提取元知识和学习方法。
其次是适配未知数据集的挑战。相别于传统小样本学习,本次比赛还考察了模型对于不同类型数据集的适应效果。由于事先并不知道测试阶段的隐藏元训练数据,挑战者提交的模型必须拥有足够的泛化能力,来应对在未知类型的数据集中提炼元知识的能力。这一点又被称为元-元学习。是对元学习的补充与提升。
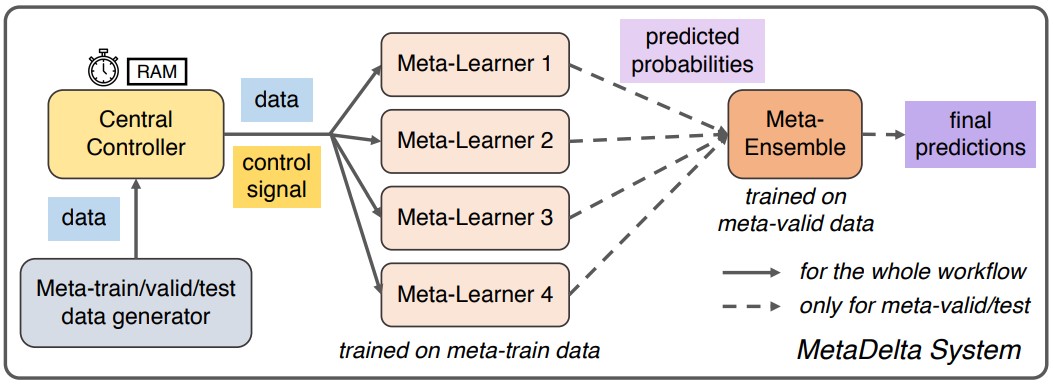
为了应对以上三个问题,朱文武教授团队提出了自适应深度元学习系统Meta-Delta来现轻量级、高效、高泛化性的元学习模型
Meta-Learner
Meta-Delta系统采用基于测量的方法来作为元学习模型的内核。这种方法将数据集映射到了一个元知识空间,并以空间中测试样本点和训练样本点的距离远近,来快速进行小样本分类。
这样的做法将元知识的提取转化为空间变换问题,是最近研究中效果最好的元学习算法之一,可以解决快速适应小样本新任务的挑战。
基于此内核,团队构造了资源控制模块,来精准管控与分配模型学习时的时间空间消耗,采用多进程与多线程相结合的方式,在不超时的前提下进行尽可能充分的元知识提取。最后,系统采用不同的预训练模型+多模型整合的方式,使得整个系统在面对未知的数据集时,仍然能够有效地提取出最佳元知识,从而使其具有更强的泛化能力。
团队成员包括计算机系在读硕士生关超宇、卫志坤、陈禹东,由关超宇担任队长,朱文武教授与王鑫助理教授担任指导教师。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

