- +1
全球首个“大脑级”AI解决方案:整块芯片有iPad那么大
大部分芯片企业通过更小的制程工艺,在同样面积下容纳下更多晶体管,以实现更强性能、更低能耗。不过,有这么一家初创企业,他们追求“大”:在更小的制程工艺的情况下,把面积做大,把功率做大,让单块AI芯片达到前所未有的性能。
北京时间8月25日,人工智能芯片设计明星初创公司Cerebras Systems(下称Cerebras)推出人工智能算力解决方案——CS-2,其内置了一块面积差不多有iPad这么大的芯片,他们将此称为“世界上第一个大脑级解决方案”。
之所以说是“大脑级”的,是因为Cerebras将单台CS-2人工智能计算机可支持的神经网络参数规模扩大至现有最大模型的100倍——达到120万亿参数,而人类大脑有100万亿个突触(突触类似于人工神经网络中的参数)。CS-2配备了世界最大芯片WSE-2(Wafer-Scale Engine,尺寸为20cmx22cm)。


Cerebras WSE-2 和当前最大的GPU
除增加单个人工智能计算机的参数容量之外,Cerebras还宣布可构建由192个CS-2人工智能计算机组成的集群,即构建包含1.63亿个核心的计算集群。
“过去几年向我们表明,对于自然语言处理(NLP,Natural Language Processing)模型,洞察力与参数成正比——参数越多,结果越好” ,他们的合作伙伴、美国阿贡国家实验室(Argonne National Laboratory,ANL)副主任里克·史蒂文斯(Rick Stevens)表示,“Cerebras的发明将使参数容量提高100倍,可能具有改变行业的潜力。我们将首次能够探索大脑大小的模型,为研究和洞察开辟广阔的新途径。”
阿贡国家实验室成立于1946年,是美国能源部下属的17个国家实验室之一,由芝加哥大学运营。可查资料显示,美国首个“E级”新一代超算“极光”号的科研便由阿贡国家实验室承担。
 对算力、单块AI芯片性能的无尽追求,归根结底在于人工智能时代对计算量的指数级增长。
对算力、单块AI芯片性能的无尽追求,归根结底在于人工智能时代对计算量的指数级增长。OpenAI对实际数据拟合后的报告显示,人工智能计算量每年增长10倍。从人工智能模型AlexNet到AlphaGo Zero,最先进AI模型对计算量的需求已经增长了30万倍。随着近年业界超大规模AI模型突破1万亿参数,小型AI算力集群难以支撑单个模型的高速训练。Cerebras所发布的AI解决方案在模型大小、计算集群能力和大规模编程的简单性方面跃上了新台阶。
AI计算机CS-2如此强劲,正在于其有着一颗“超强大脑”——专为深度学习设计的WSE-2芯片。WSE-2采用7nm工艺,面积达46225平方毫米,包含2.6万亿个晶体管,这些晶体管被集中到85万个处理单元(或称“核心”)中。
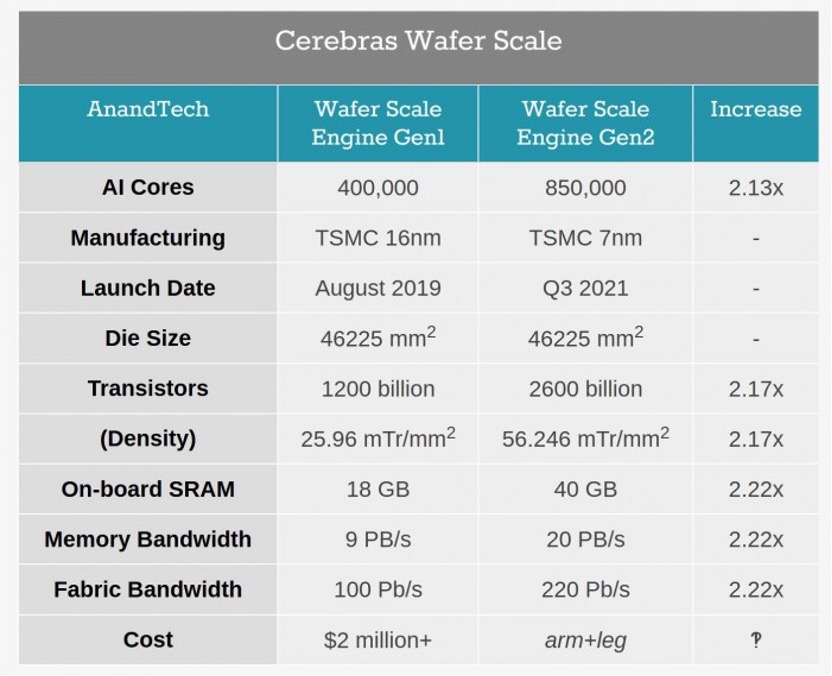 WSE-2的面积是英伟达目前面积最大GPU特斯拉A100的近56倍,核心数(cores)是A100的近123倍,内存容量是A100的1000倍,内存带宽是A100的约1万3千倍,矩阵带宽(fabric Bandwidth)是A100的约4万6千倍。无论是核心数还是片上内存容量均远高于迄今性能最强的GPU,且通信速度更快,计算能力更好。
WSE-2的面积是英伟达目前面积最大GPU特斯拉A100的近56倍,核心数(cores)是A100的近123倍,内存容量是A100的1000倍,内存带宽是A100的约1万3千倍,矩阵带宽(fabric Bandwidth)是A100的约4万6千倍。无论是核心数还是片上内存容量均远高于迄今性能最强的GPU,且通信速度更快,计算能力更好。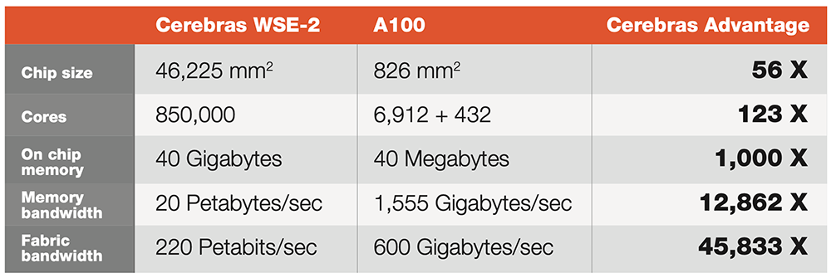 当下人工智能的重要应用如自动驾驶、视频推荐背后都是深度学习技术,大多数现代深度学习模型都基于人工神经网络。在训练大型AI模型时常常是使用连接在一起的数千台机器集群一起工作,比如由谷歌操作的数据中心。这个集群就像一个分散在多个房间里并连接在一起的“大脑”,电子能以光速移动,但即便如此,跨芯片通信还是很慢,并且消耗大量的能源。随着近年业界超大规模AI模型突破1万亿参数,当前的集群难以支撑单个模型的高速训练。
当下人工智能的重要应用如自动驾驶、视频推荐背后都是深度学习技术,大多数现代深度学习模型都基于人工神经网络。在训练大型AI模型时常常是使用连接在一起的数千台机器集群一起工作,比如由谷歌操作的数据中心。这个集群就像一个分散在多个房间里并连接在一起的“大脑”,电子能以光速移动,但即便如此,跨芯片通信还是很慢,并且消耗大量的能源。随着近年业界超大规模AI模型突破1万亿参数,当前的集群难以支撑单个模型的高速训练。Cerebras联合创始人安德鲁·费尔德曼(Andrew Feldman)表示,“更大的网络,例如GPT-3,已经改变了自然语言处理(NLP)的格局,使以前无法想象的事情成为可能。在业界,1万亿参数的模型层出不穷,我们正在将该边界扩展两个数量级,使大脑规模的神经网络具有120万亿个参数。”
 2016年,安德鲁·费尔德曼(Andrew Feldman)、加里·劳特巴赫(Gary Lauterbach)、迈克尔·詹姆斯(Michael James)、肖恩·利(SeanLie)和让·菲利普·弗里克(Jean-Philippe Fricker)在硅谷创立了Cerebras公司,制造适用于深度学习的人工智能芯片,安德鲁·费尔德曼(Andrew Feldman)任CEO。在创立Cerebras之前,五位创始人都曾在微型服务器厂商SeaMicro工作,SeaMicro在2012年被半导体公司AMD(Advanced Micro Devices)收购。
2016年,安德鲁·费尔德曼(Andrew Feldman)、加里·劳特巴赫(Gary Lauterbach)、迈克尔·詹姆斯(Michael James)、肖恩·利(SeanLie)和让·菲利普·弗里克(Jean-Philippe Fricker)在硅谷创立了Cerebras公司,制造适用于深度学习的人工智能芯片,安德鲁·费尔德曼(Andrew Feldman)任CEO。在创立Cerebras之前,五位创始人都曾在微型服务器厂商SeaMicro工作,SeaMicro在2012年被半导体公司AMD(Advanced Micro Devices)收购。当业内其他公司正在让一块晶圆能产出尽可能多的芯片时,Cerebras走向了另一个方向:使整个晶圆成为一块大芯片,这创造了芯片设计领域的一场革命。

除了世界最大WSE-2芯片做支撑,这套AI解决方案的背后还有Cerebras最新披露的四项创新:新的软件执行架构Weight Streaming;内存扩展技术Cerebras MemoryX;高性能互连结构技术Cerebras SwarmX;动态稀疏收集技术Selectable Sparsity。
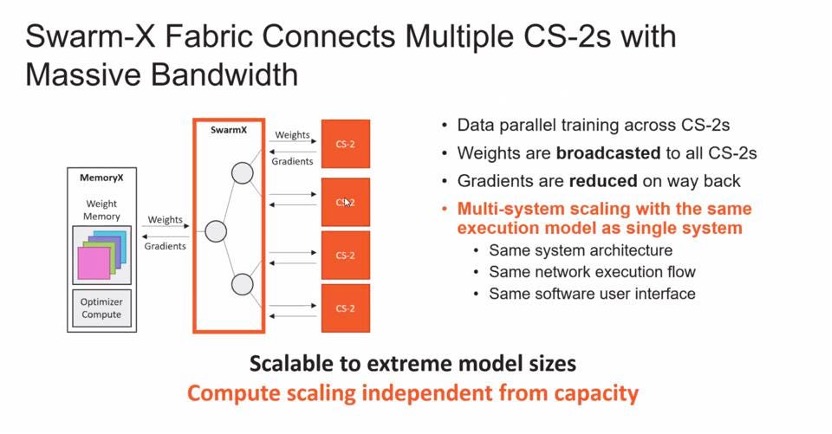 Weight Streaming技术首次实现了在芯片外存储模型参数的能力,同时提供与芯片上相同的训练和推理性能。这种新的执行模型分解了计算和参数存储,并消除了延迟和内存带宽问题。这极大地简化了工作负载分配模型,让用户可以从使用1个CS-2扩展到最多192个CS-2,而无需更改软件。
Weight Streaming技术首次实现了在芯片外存储模型参数的能力,同时提供与芯片上相同的训练和推理性能。这种新的执行模型分解了计算和参数存储,并消除了延迟和内存带宽问题。这极大地简化了工作负载分配模型,让用户可以从使用1个CS-2扩展到最多192个CS-2,而无需更改软件。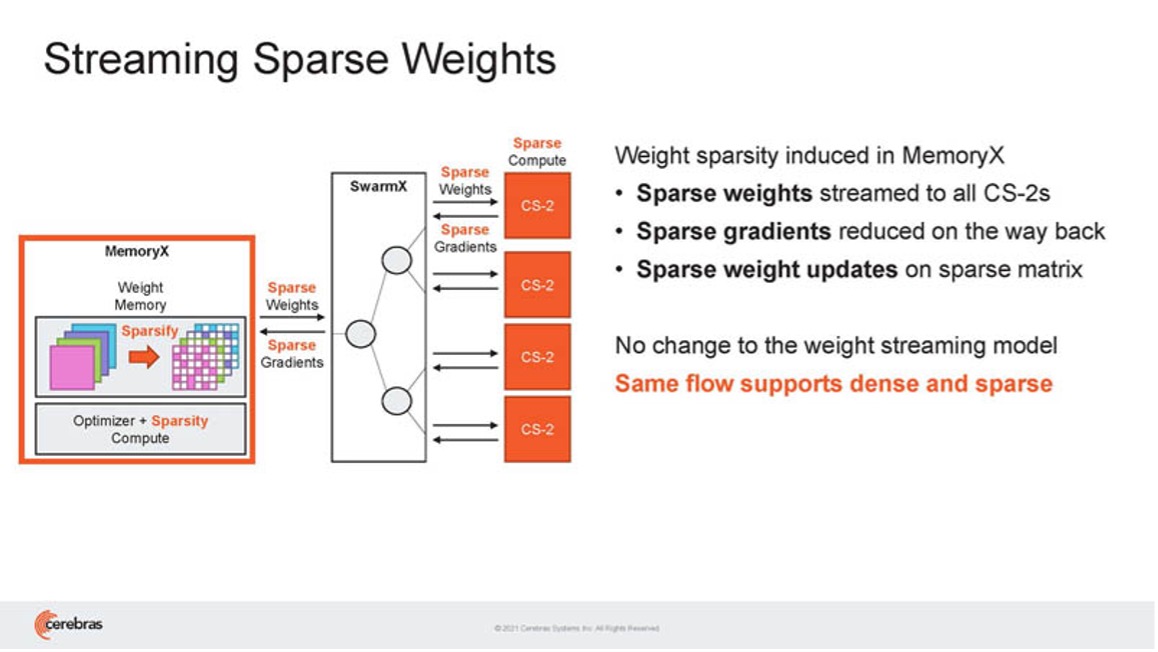 CambrianAI创始人兼首席分析师卡尔·弗洛因德(Karl Freund)表示:“使用大型集群解决AI问题的最大挑战之一是为特定神经网络设置、配置和优化它们所需的复杂性和时间。而Weight Streaming允许在CS-2集群令人难以置信的计算资源之间进行更直接的工作分配,Weight Streaming消除了我们今天在构建和有效使用巨大集群方面必须面对的所有复杂性——推动行业向前发展,我认为这将是一个转型之旅。”
CambrianAI创始人兼首席分析师卡尔·弗洛因德(Karl Freund)表示:“使用大型集群解决AI问题的最大挑战之一是为特定神经网络设置、配置和优化它们所需的复杂性和时间。而Weight Streaming允许在CS-2集群令人难以置信的计算资源之间进行更直接的工作分配,Weight Streaming消除了我们今天在构建和有效使用巨大集群方面必须面对的所有复杂性——推动行业向前发展,我认为这将是一个转型之旅。” MemoryX是一种内存扩展技术,包含高达2.4PB的动态随机存取存储(Dynamic Random Access Memory,DRAM)和闪存,以保存海量模型的权重,以及处理权重更新的内部计算能力。SwarmX是一种高性能、人工智能优化的通信结构,可将Cerebras Swarm片上结构扩展到片外,使Cerebras能够在多达192个CS-2上连接多达1.63亿个AI优化内核,协同工作以训练单个神经网络。Selectable Sparsity使用户能够在他们的模型中选择权重稀疏程度,并直接减少浮点数(FLOPs)和解决时间。
MemoryX是一种内存扩展技术,包含高达2.4PB的动态随机存取存储(Dynamic Random Access Memory,DRAM)和闪存,以保存海量模型的权重,以及处理权重更新的内部计算能力。SwarmX是一种高性能、人工智能优化的通信结构,可将Cerebras Swarm片上结构扩展到片外,使Cerebras能够在多达192个CS-2上连接多达1.63亿个AI优化内核,协同工作以训练单个神经网络。Selectable Sparsity使用户能够在他们的模型中选择权重稀疏程度,并直接减少浮点数(FLOPs)和解决时间。
AI计算机CS-2

CS-2 的内部视图:从左到右分别是门、风扇、泵、电源、主机架、热交换器、发动机缸体、后格栅

CS-2 的前视图: 下半部分是风扇,右上方是泵用来输送水,左上方的电源和 I/O (Input/Output)提供电力和数据。

侧视图:水运动组件(顶部),空气运动基础设施和风扇和热交换器(下半部分)

CS-2的发动机缸体
启用WSE(Wafer Scale Engine)所需的创新之所以成为可能,是因为完整系统解决方案提供了灵活性。CS-2 的每个组件——从电源和数据传输到冷却再到软件,都经过协同设计和优化,以充分利用这个庞大的深度学习芯片。

WSE-2 编译过程的概述
可视化工具使研究人员可以回视编译器CGC编译过程的每个步骤

CS-2 集群可以在模型并行和数据并行模式下运行



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

