- +1
算法·深析|《科学》子刊:机器人的凝视如何影响人类行为

“你瞅啥?”
“瞅你咋滴?”
在人类社会的某些情景下,“瞅”是个具有冒犯性的动作,那么人类面对机器人的“瞅”会怎么样?
来自意大利理工学院(Italian Institute of Technology)的Marwen Belkaid、Agnieszka Wykowska等研究了类人机器人的凝视(相互的或回避的)是否会对人们在社会决策环境中进行战略推理的方式产生影响。
“凝视是人与人交流和互动过程中极其强大和重要的信号。我们天生就会注意别人的眼睛,当有人看着我们或将目光投向环境中的某个事件或位置时,我们的大脑会做出非常强烈的反应,我们与他人日常交流的许多方面取决于凝视模式并受它们的影响”,Agnieszka Wykowska对澎湃新闻(www.thepaper.cn)记者阐释研究初衷时说道,“在这种情况下,有趣的问题是,机器人等人造实体的‘凝视’是否会对我们的人脑产生类似的影响。人脑是否也将机器人的目光作为社交信号处理?该信号会影响社会和认知过程吗?”
研究发现,机器人凝视对人类来说是也是一种强烈的社会信号,可以调节响应时间(response times)、决策阈值(decision threshold)、神经同步(neural synchronization)以及选择策略(choice strategies)和对结果的敏感性(sensitivity to outcomes)。
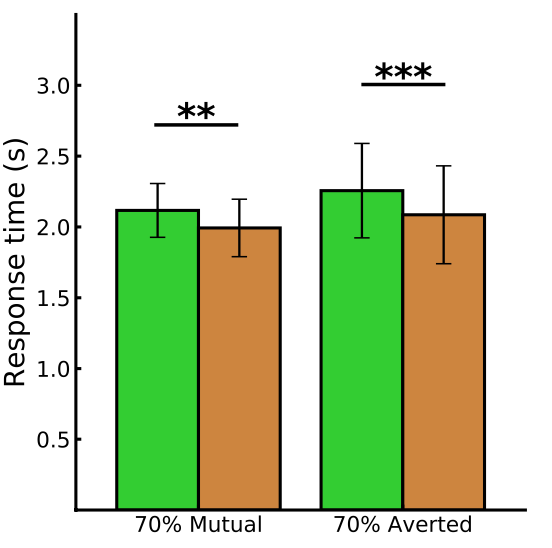
凝视类型对参与者的反应时间有显著的影响
9月2日,该研究发表在《科学机器人》(Science Robotics,《科学》杂志子刊)上,题为《与机器人相互凝视会影响人类神经活动并延迟决策过程》(Mutual gaze with a robot affects human neural activity and delays decision-making processes)。
“应用于各种领域的机器人可以为人类社会带来巨大价值,例如从客户服务到医疗保健再到制造业。但为了创造与人类互动时让人感到‘自在’的机器人,我们需要了解人类大脑如何处理这种微妙的行为信号(例如凝视模式)。只有这样,我们才能创造出与人类大脑工作相适应的机器人。对于机器人旨在帮助和协助人类的应用领域,例如老人或儿童保育,这绝对是至关重要的,”Agnieszka Wykowska表示。
机器人凝视下,人会分心
Agnieszka Wykowska、Marwen Belkaid及其同事研究了43名参与者在玩战略游戏时对一个人形iCub机器人的反应。研究人员测量了参与者的行为和神经活动脑电图(EEG),重点关注theta和alpha波段——被认为受决策、注意力和眼神交流的调节。
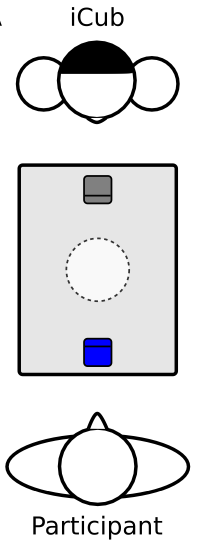
参与者与iCub机器人面对面,Chicken Game显示在他们之间的屏幕上(Chicken Game为游戏名,被称为“胆小鬼博弈”。游戏中两名车手相对驱车而行。如果两人拒绝转弯,任由两车相撞,最终两人都会死于车祸;但如果有一方转弯,而另一方没有,那么转弯的一方会被耻笑为“胆小鬼”chicken,另一方胜出)。
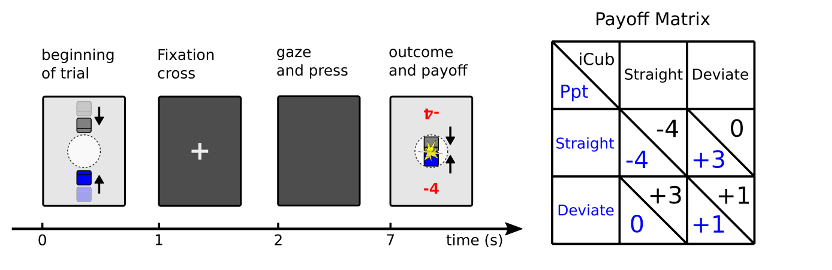
在参与者决策期间操纵机器人的凝视(标记为“凝视和按下”,在2到7秒的位置)。在查看iCub后,参与者必须决定是直行还是偏离。试验的结果和每个玩家的收益由两个玩家的选择组合决定。

从左到右分别为:人形iCub机器人处于中间状态看向屏幕;iCub与参与者对视,看向参与者;iCub避免对视,看向屏幕下方
研究人员发现,相对于回避凝视,当参与者与iCub建立相互凝视时,其对iCub的反应较慢。同时,这还伴随着阿尔法(alpha)脑电波活动(一种与抑制注意力有关的脑电波模式)的增加。与没有受到机器人凝视的参与者相比,在机器人凝视下的参与者表现出延迟的决定、较慢的响应时间和不同的神经波模式。
因此,作者假设,机器人凝视下更高的阿尔法同步(阿尔法同步被解释为对抑制干扰信息的需求增加的标志)可能代表参与者需要在专注于游戏的同时抑制分心,从而导致更长的反应时间。
“具有社交行为的机器人可能并不总是对人类有益”
在面对更高频率回避凝视的机器人,参与者更有可能根据当前结果重复他们之前的动作——一种“自我导向”的策略,玩家只需要关注自己动作的信息并反映个人决策。相比之下,受到机器人凝视的参与者采用了“面向他人”的策略,该策略要求参与者处理机器人对手的动作和结果,即参与者从上次试验中复制对手的行为。
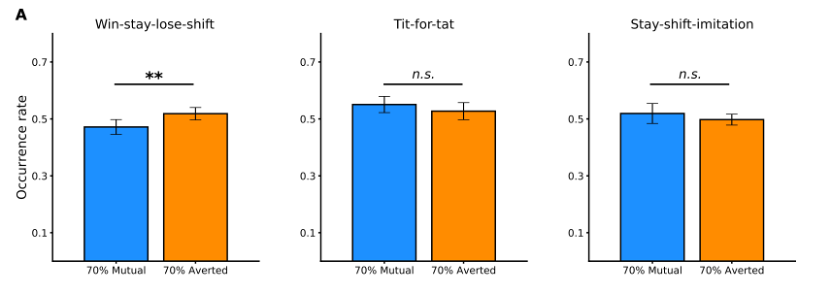
参与者选择序列中自我导向和他人导向的战略行为模式。
自我导向(Win-stay-lose-shift,简称WSLS,双赢双输策略,如果产生的收益达到其期望水平,则重复之前的举措,否则就变化策略)和两种其他导向(Tit-for-tat,简称T4T,以牙还牙策略,对手在上一轮做了什么。对手合作就合作,对手叛逃就叛逃;Stay-shift-imitation,简称SS-Imit,模仿策略)模式的发生率。
自我导向的WSLS在更多暴露于相互凝视的参与者的选择中出现明显较少,T4T和SS-Imit没有发现显着差异。

WSLS模式序列的平均长度在70%Averted条件下显著更大。T4T和SS-Imit没有发现显着差异。
整个研究表明,对人类而言,即使是来自机器人的凝视也可以成为一种强烈的社会信号,影响他们的决策行为和神经信号模式。“因此,在人们需要专注于自己的决策过程的环境中,这可能会分散注意力。在这样的背景下,具有社交行为的机器人可能并不总是对人类有益,”Agnieszka Wykowska对澎湃新闻表示。
对于接下来的研究计划,Agnieszka Wykowska表示,将来会继续研究是否以及何时需要与机器人进行社会协调。“我们认为,现在重要的是识别那些帮助机器人成为一个社会体的其他(微妙)行为,并了解这些行为是否(以及在哪些情况下)对人类有益。希望这将有助于机器人专家设计出在特定应用场景中表现最好的机器人。”
附:
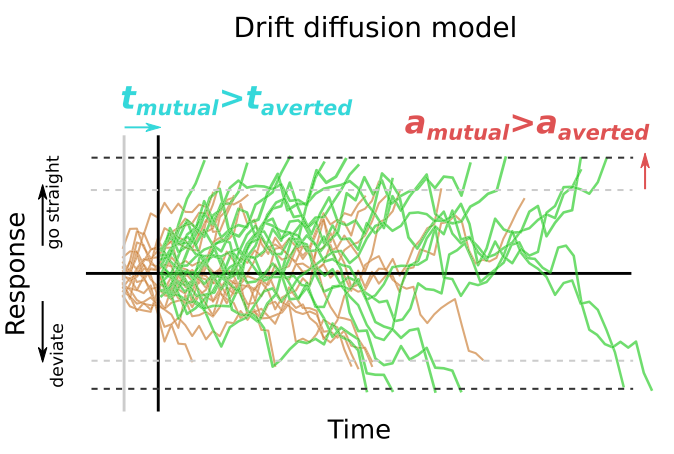
漂移扩散模型将决策描述为一个嘈杂的漂移过程,当跨越相应的边界时选择一个动作。假设机器人的凝视对模型参数的一个、两个或没有影响,测试了五个变体。根据贝叶斯参数估计,发现最佳拟合模型是将响应时间的差异对非决策时间t和决策阈值a产生影响的模型。
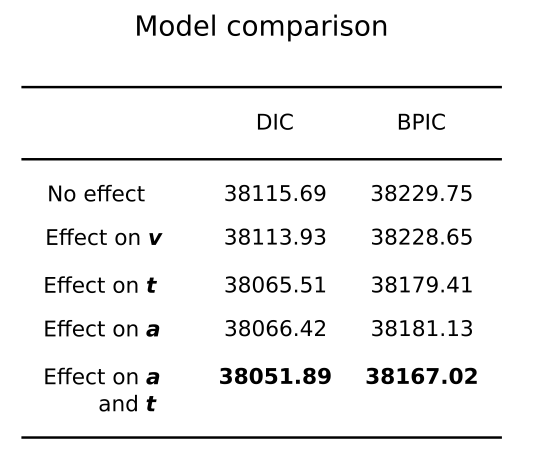
DIC,偏差信息准则;BPIC,贝叶斯预测信息准则。较低的值更好。
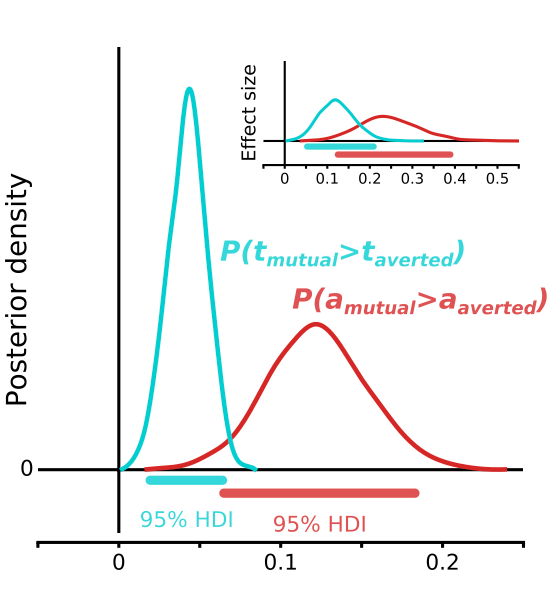
最佳拟合模型的效果分布的后密度,显示对a和t参数的显着影响。HDI,最高密度区间。误差线代表95%的置信区间。

决策期间凝视类型之间的头皮地形。 考虑到来自两个参与者组的数据,地形图显示了凝视条件(回避凝视-相互凝视)之间引发的 alpha 振荡(8 至 12 Hz)差异的 t 值图。 统计上显着的集群由x标记。 条件之间的差异是通过基于非参数聚类的排列测试发现的。t值定义为两个条件的估计平均值之间的差异与其标准误差的比值。相对于所展示的凝视的建立(每320毫秒),在t = 0.31 s到t=0.95s的时间范围内描绘了地形。
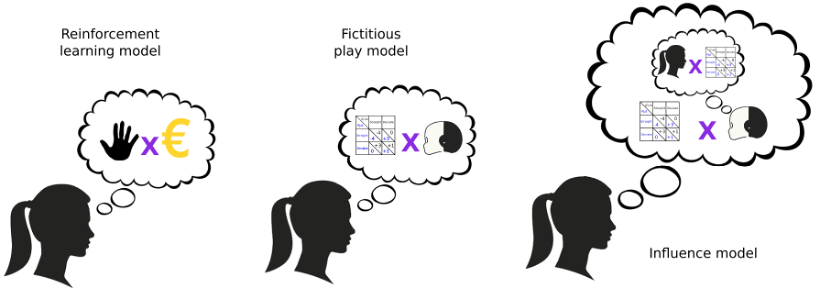
模型示意图:参与者对iCub行为的推理程度的计算模型。
强化学习模型(RL)根据最近选择的动作及其结果做出决策。虚拟游戏模型(Fic)根据游戏的收益矩阵和对手的预测动作做出决策。影响模型(Inf)做同样的事情,同时假设对手也在预测玩家的选择,并将其自身行为的影响纳入对对手决策的预测。
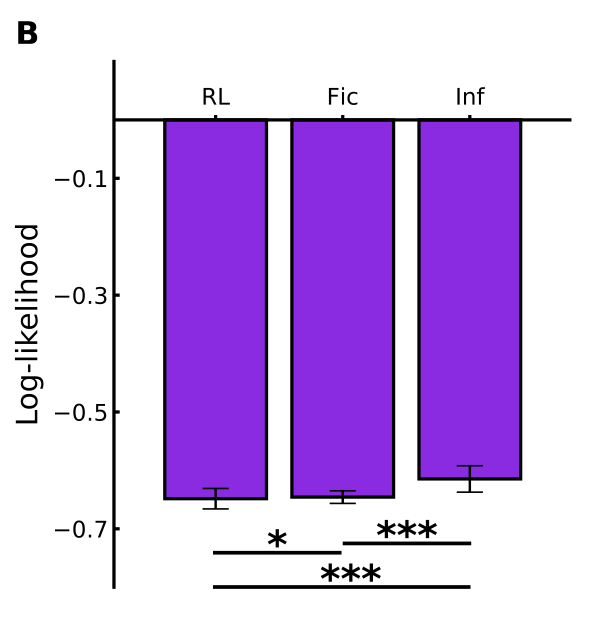
拟合参与者选择的影响模型的总体对数似然显着大于其他两个模型,表明在游戏期间对iCub 进行了高水平的推理。
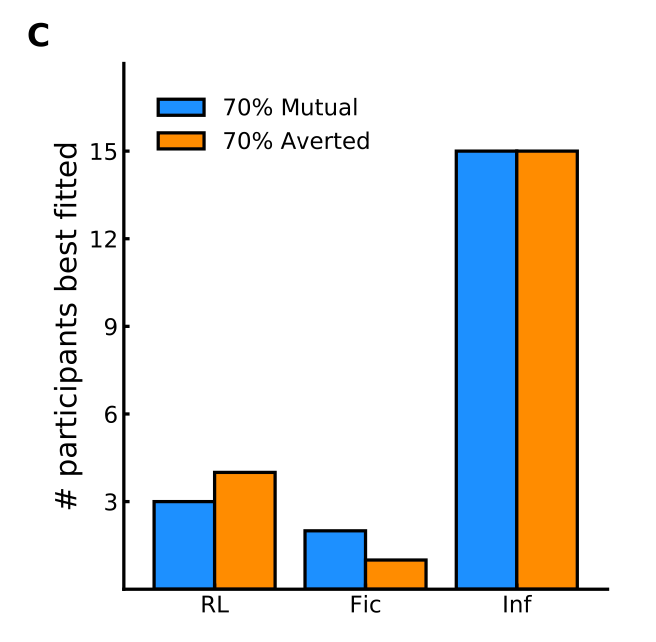
单独考虑每个参与者的最佳拟合模型并没有揭示更多暴露于一种凝视的人与另一种凝视的人之间的显着差异。
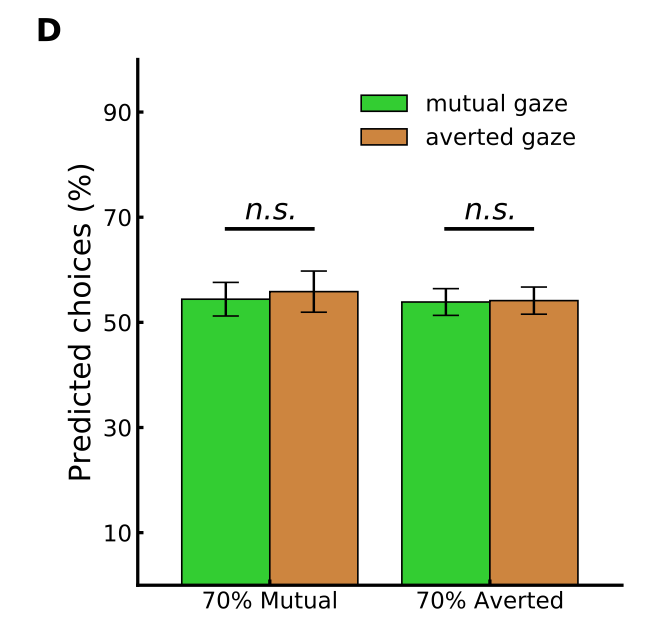
模型预测的逐个试验选择的百分比在相互或回避凝视后相似。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

