- +1
抹去记忆,竟如此简单?报答或报复,观猴如观人 | Paper Alert
抹去记忆,竟如此简单?报答或报复,观猴如观人;人类保持控制指南:总是预想,偶尔幻想 | Paper Alert # 35 原创 NR 神经前研 收录于话题 #Paper Alert 33个内容
认知与行为
人类保持控制指南:
总是预想,偶尔幻想
Na,Chung et al., eLife
@Orange Soda
生活缺乏可控性很大程度上影响着人们的精神健康,包括不可控的压力、疼痛以及习得性无助。故而,很多人会在旅行前做行程计划,在周一做一周的工作计划,在人生的重要时刻(比如婚礼)进行更多的筹备——预先的计划能帮助人们获得更多的控制感。但在社交情境下,人们也会利用“超前思维”(forward thinking,FT)来获得社交可控性吗?
Na和Chung等人基于最后通牒博弈框架设计了一项社会交换的任务,任务分为可控和不可控两种不同情境。48名被试被告知和另一组玩家进行20美元的分摊,决定是否接受对方的提议,在60%的试次中被试会在完成选择后给自己的情绪打分,在完成某种情境的全部实验后,被试会对自己在实验过程中的可控程度进行主观打分(Fig.1a)。在两种情境下的第一轮的提议总是5美元,在可控的情境下,如果在某一轮中被试选择接受某个提议,那么下一轮对方的提议会减少d(d=0/1/2,各1/3概率);反之如果拒绝某个提议,下一轮对方的提议则会增加d(Fig.1b)。在不可控条件下则不存在这样的规律,每一轮中的提议金额是从一个高斯分布中随机选取的数值(μ=5, σ=1.2,四舍五入取整),因此被试的行为对未来收到的提议金额没有任何影响。
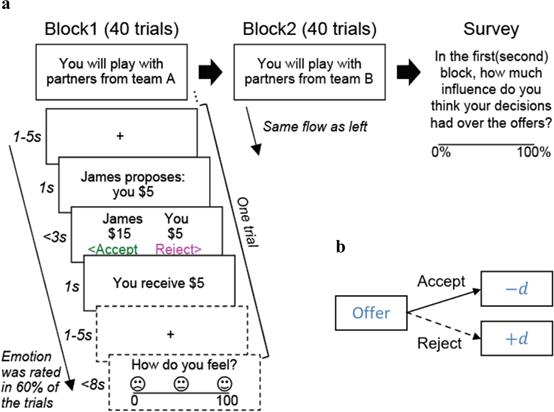
Fig.1
—
Goltstein et al., Nature Neuroscience
结果发现,尽管第一轮的提议总是5美元,被试在可控情境下的平均收益会高于不可控的情境(Fig.2a1, a2);在两种情境下,被试总体的拒绝率相当,但在可控条件下被试更倾向于拒绝中到高金额的提议(4-9美元),而在低金额提议(1-3美元)拒绝率差不多(Fig.2b2)。在可控情境下,被试做决定的时间显著比不可控条件下长,这说明被试对两种情境下的可控性程度有所察觉(Fig.2d)。根据被试的主观报告,在可控情境下的可控程度报告分数显著高于不可控的情境,但即使是在完全不可控的情境下,被试报告的分数(43.7%)也远高于实际(0%),这也说明被试实际上会产生某种能控制对手的幻觉。总的来说,被试能够察觉在社交环境下的可控程度,不过在毫无控制的情境下会产生一定程度的控制感幻觉。
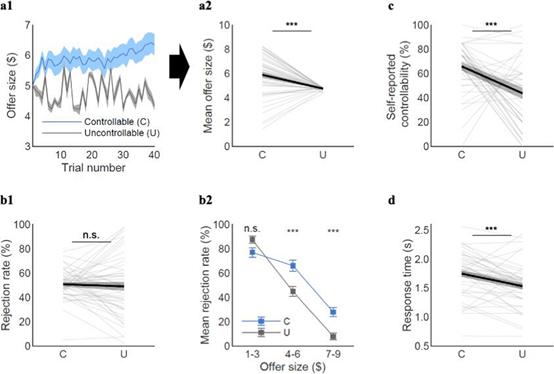
Fig.2 不同情境下的被试行为
—
Na,Chung et al., eLife
此前有研究发现,在当前的行动会对未来产生影响的情况下,人们会利用超前思维,并在内心模拟未来可能的情况。因此,研究者猜测在社交情境下,被试也会同样采取超前思维的策略。假设被试会根据自己所估计的社交可控性,用当前获得的价值(current value,CV)和未来获得的价值(future value,FV)相加来计算某一行动的价值,在这一假设前提下,Na和Chung等人构建了一系列超前思维的模型,结果表明,考虑到被试的超前思维的模型显著地比常规模型(前瞻步长step=0)获得了更高准确度(Fig.3),其中前瞻步长为2时(也就是会提前考虑两轮后的收益)对模型的预测准确度提升最高。
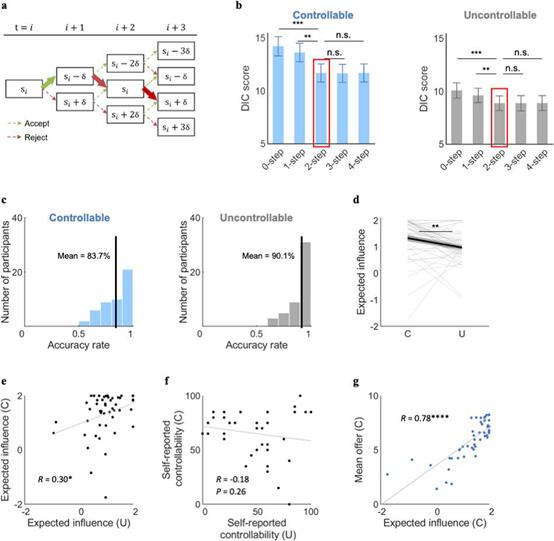
Fig.3 社交情境下的模拟结果
—
Na,Chung et al., eLife
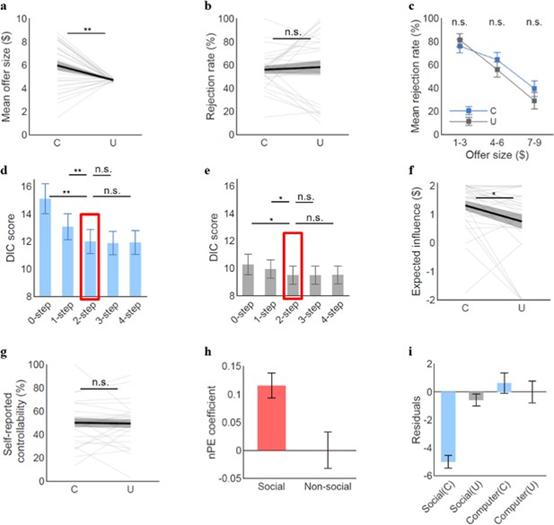
Fig.4 非社交情境下的模拟结果
—
Na,Chung et al., eLife
为了探究这一结果是否仅限于社交情境下,Na和Chung等人接着进行了非社交版本的任务,27名被试进行了同样的游戏并被告知对手是电脑。利用同样的计算模型,2步前瞻思维模型取得了更好的预测度(Fig.4)。有趣的是,在这种实验条件下,可控情境和不可控情境下的自我报告的可控程度没有显著差异,这说明社交环境会影响被试对可控性的主观信念。另外,研究者计算了被试的收益-预期误差(reward prediction errors,RPEs)对被试情绪的影响,发现非社交情境降低了RPEs对被试情绪的影响。总的来说,在各种情境下被试都可能采用了同样的超前思维策略,但社交环境对被试的主观体验产生了影响。在大样本的在线被试(n=1342)上的实验结果也支持这一结论。
doi: 10.7554/eLife.64983
焦虑的人探索得更多,
过多的探索让人错失最优解
Aberg et al., Mol. Psychiatry
@肖本
这个世界充满了不确定性,没有人可以完美地预测每一次抉择的后果,而与不同的选择相伴的不确定性本身往往也难以推断。当我们面对众多可能的选项时,我们是应当只在“熟悉的面孔”中比较,还是应该勇于拥抱未知,看看那些自己不曾尝试的选项是否更可能藏有奖励?前一种倾向被称为利用(exploit),而后一种倾向被称为探索(explore)。
有时,我们做出的探索纯粹是为了搞清楚那些未知选项的利弊,以此降低不确定性;有时,当我们自以为熟悉的选项不再为我们提供奖励后,我们也不得不做出变换(switch),探索其他选项。来自以色列的研究团队让被试在三个不同的“老虎机”中选择奖励最多(或损失最少)的选项,并在实验过程中不断变换奖励的概率(如图C所示),以此探索决策、学习与焦虑特质(trait anxiety)以及神经活动之间的关联。
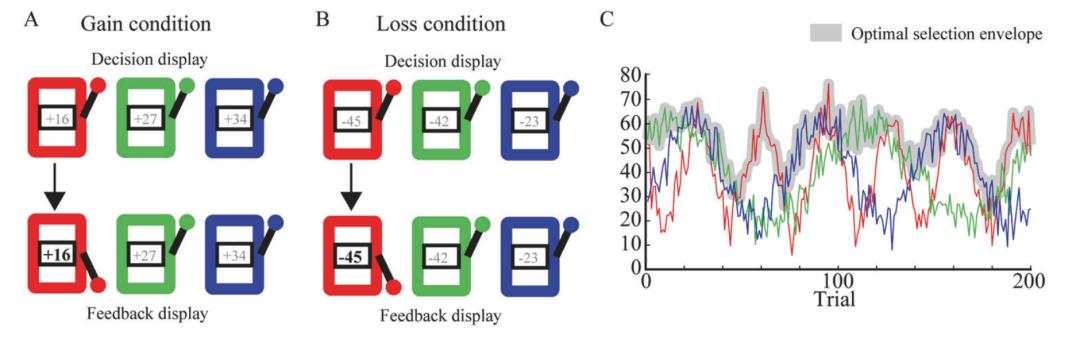
- Aberg et al., Mol. Psychiatry -
通过强化学习模型(reinforcement learning model),研究人员可以估算每个时间点上被试对于各选项的价值的主观估计(expected value),并参数化各种不同因素对最终选择的影响。更重要的是,得出了主观估计的价值后,每一个选择是属于“利用”还是“探索”就一目了然了——如果被试选择了和上次所选不同的机器,且被试对该机器主观所估的价值还不是所有机器中最高的,那么该选择就会被归类为探索。模型比较显示,除了主观价值,影响选择的其他因素还包括结果不确定性(outcome-uncertainty,定义为与上一次选择该选项之间所隔的选择数)和随机变换(random switching;如果刚刚选择了该选项,则值为0,反之则为1)。
- Aberg et al., Mol. Psychiatry-
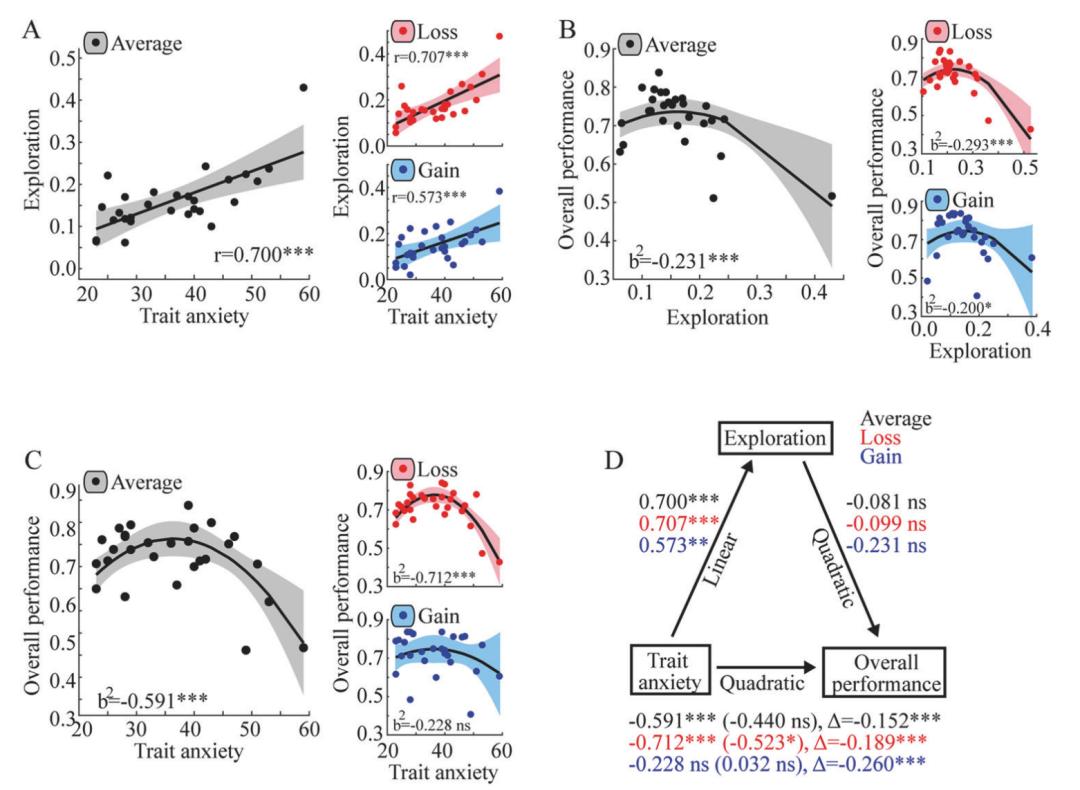
如上图图A的结果所示,焦虑特质越高的人,探索性的选择就越多,且这一倾向在两个不同版本的实验(获取奖励[gain],以及止损[loss])中均有体现。不过,由上图图B所示,探索所占的比例与所在任务上的表现则呈现倒U字型的关系——一定程度的探索可以帮助人们及时改变自己的选择,而过多的探索则会带来不必要的变换,错失最佳选项。因此,焦虑特质与决策的表现也呈倒U字型关系(图C)。
- Aberg et al., Mol. Psychiatry -
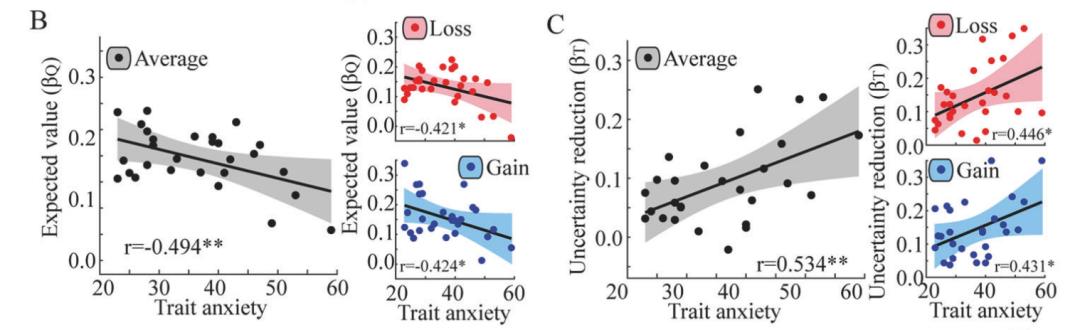
另外,针对强化学习模型参数所做出的的分析显示,焦虑特质越高,决策受主观价值的影响就越小,受结果不确定性的影响则越高。同时,二者的差值也与焦虑特质呈负相关——或许,焦虑特质较高的人群,在价值与不确定性的权衡(trade-off)中会越倾向于不确定性。这一权衡方面的问题也体现在神经层面:通过功能核磁共振,研究人员发现,焦虑特质越高,背侧前扣带皮层(dorsal anterior cingulate cortex,dACC)的活动受主观价值的影响就越小;与此同时,在前岛叶(anterior insula,aINS)中有对于结果不确定性的表征,而焦虑特质越高的人,前岛叶受不确定性的影响就越高。
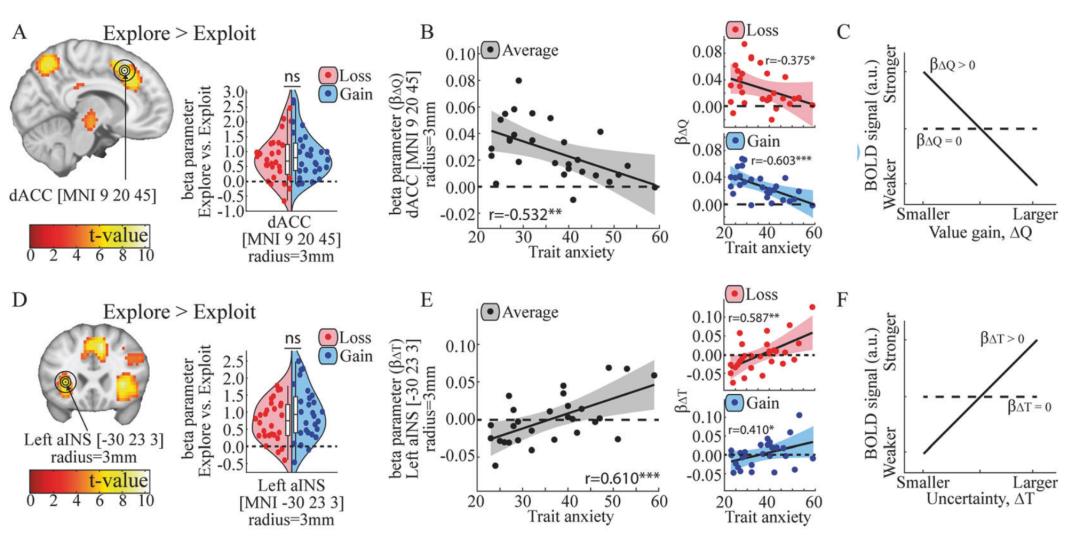
- Aberg et al., Mol. Psychiatry -
总而言之,该研究解析了焦虑特质与探索行为之间的关系,并在神经层面刻画了做出相应权衡的区域:焦虑特质更高的人急需通过探索来降低不确定性,却也因此忽略了价值本身,导致总体收益下降。值得注意的是,研究所发现的关系基本不受任务版本的影响,对于寻找奖励和避免损失的行为均适用。
doi: 10.1038/s41380-021-01363-z
系统与网络
报答或报复,
成年人的世界就这么简单
Báez-Mendoza et al., Nature
@Veronica
《自私的基因》作者理查德道金斯曾经写过一本行为领域的经典之作《合作的进化》,作者以组织的两轮“重复囚徒困境”竞赛作为研究对象,发现即使计算机算法发明了看似更聪明更复杂的策略,也依然比不过人类一直以来采用的“一报还一报”策略。最近,来自哈佛大学的Ziv Williams研究组发表了一篇有趣的论文,用猕猴作为实验对象重现了博弈论的精华。
实验设计是这样的:一位科(shua)学(hou)家(ren)安排三只猴同坐一个圆桌,每一次试验都有一只猴被随机指定作为分发食物的猴(actor),它有权决定转动圆桌把食物分给另外两只猴中的任意一只(recipient)。为了排除其他时空因素的干扰,圆桌的转动方向会在实验中改变,这三只猴也需要在每天中场休息时变换座次,这样一来,猴就会更加纯粹地依赖社会因素而不是空间位置偏好来做出决策。当然,科学家在耍猴的同时并没有忘记给其中一只猴的背内侧前额叶皮层(dorsomedial prefrontal cortex,dmPFC)区域插入了电极,用来记录这个特殊的群体社交实验中神经元的放电情况。
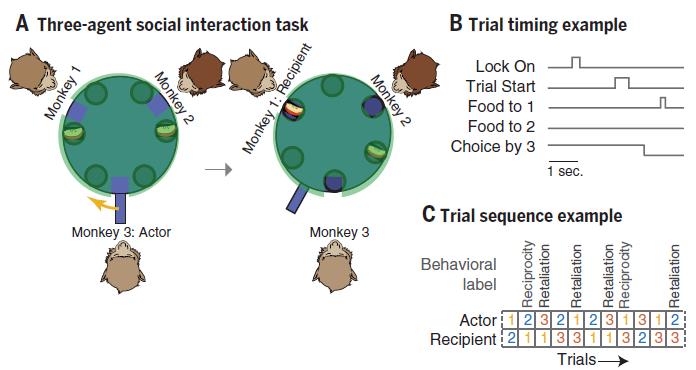
- Báez-Mendoza et al., Nature -
科学家发现,猴子的行为跟人类惊人相似:不论是哪一只猴,它们都更倾向于“报答”前一次试验中给它分发食物的猴,比如第一次猴A给猴B分发了食物,第二次如果轮到猴B做决定,它会更多地把食物分给猴A而不是猴C。但如果前一次猴A分发食物给猴C了,接下来如果是猴B做决定,猴B就会“报复”猴A,转而把食物分给猴C(此处猴C非常开心地坐享渔翁之利)。更有意思的是,猴子们还会根据另外两只猴的“名声”来做决定,比如在以往的经验中,其中一只更可能出现报答行为,那么决策者这次就更愿意把食物分给它,这样自己下一次试验吃到食物的概率就会更大。猴子们的这种行为和人类的以眼还眼、以牙还牙(tit-for-tat)策略如出一辙,说明猴不仅能记住自己和谁“交手”过,而且还能记住交手过程中对方到底是友善还是心怀恶意。
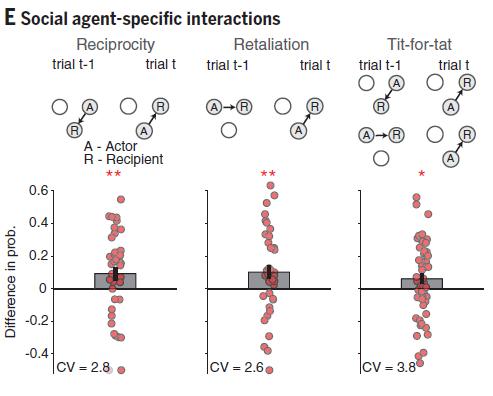
- Báez-Mendoza et al., Nature -
那么,这种行为背后的神经基础是什么呢?科学家在猴子的dmPFC电极记录时找到了不同类型的神经元,其中一类神经元在自己得到食物时会放电,或者在任意一只猴得到食物时就会放电,但他们还发现了一类神经元,独独只在特定一只猴得到食物时才会放电。不仅如此,不论一次试验中谁是分发食物者、谁是享受食物者,总有一部分神经元能特异性地响应特定的猴(自己或是猴B或是猴C),而且这些神经元“敌我分明”,响应自己的和响应他人的神经元基本上没有重合。
那么,既然找到了dmPFC编码不同身份的神经元,是否可以通过机器学习的方法解码出猴子的决策呢?答案是肯定的。科学家发现,如果应用多类分类解码器(multiclass decoder)来预测分配食物的是哪一只猴,其准确率可以高达81.7%,而如果在分配食物的猴下定决心之后、做出行动之前预测谁会得到食物,解码器的准确率也可以高达70.1%,这说明dmPFC神经元包含了丰富的猴子身份信息。不仅如此,科学家还能基于另外两只猴的历史表现,通过神经元群体放电信息来预测这只猴下一次试验的决定:到底是投之以桃,报之以李,还是以眼还眼,以牙还牙。
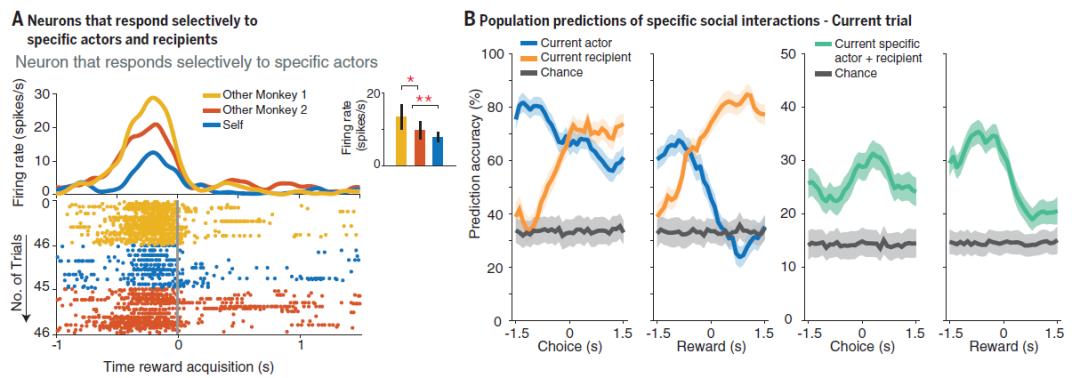
- Báez-Mendoza et al., Nature -
是否有办法让喜欢报复的猴“放下屠刀“,变成一只善良的猴呢?遗憾的是,科学家试图在试验中给dmPFC加入电刺激,结果发现电刺激丝毫不能影响猴子报复别人的行为,更杯具的是,电刺激不仅没能让爱报复的猴“改过自新”,反倒让猴忘记了别人的善意,不再愿意报答其他猴了。
虽然本文最后是一个悲伤的故事,但笔者认为故事的本身精彩无比,可谓是“以猴为镜,可以识人心”~
doi: 10.1126/science.abb4149
抹去你的记忆,so easy
Goto et al., Science
@图图
我们经常可以在科幻电影里看到,主角团经历重重惊险并获得了重要线索的时候,背后的大boss突然出现,抓起来一阵操作,就到了全体失忆的桥段……但我们的记忆真就如此脆弱吗?
在记忆的处理过程中,通常我们会先在海马体(hippocampus)中编辑信息,暂时存放我们的记忆。但因为仓库不够大,所以为了长期储存和方便未来的调用,这些记忆不久就会被网络传送带送往别的脑区,如大脑皮层(cortex)。那么记忆是如何编码的呢?如何转运的呢?其实在过去的几十年里,科学家们已经给出了很多的猜想和证据,其中最为大众熟知的就是,突触可塑性(synaptic plasticity)是学习记忆的基石,如果突触间的联系得不到巩固加强,那么我们就很有可能会忘记那些从我们生活中匆匆路过的信息。然而,突触可塑性是在何时何地发生的呢?他们会如何影响神经元的表征?这些问题看似简单,但受限于技术方法的发展,一直悬而未决。
近日,来自日本京都大学、理化学研究所脑科学中心的YASUNORI HAYASHI实验室开发了一种新技术,利用光遗传手段精准消除突触间的长时程增强(long-term potentiation,LTP)。通过对突触可塑性定时定点的控制,他们发现这种可塑性在记忆编码的不同阶段扮演着不同的角色。
前期研究表明,早期LTP与树突突触的快速肌动蛋白聚合密不可分,坚定地支持着突触体积地增大,而丝切蛋白(Cofilin,CFL)在低密度的情况下会瓦解actin的稳定性,这使得科学家们猜想,如果可以精确的抑制CFL的活性,是否就有可能选择性消除突触LTP呢?
首先,他们将感光抑制蛋白(SuperNova,SN)嵌入CFL,那么一旦给出相应波长的光,CFL就会因为发色团辅助光失活(CALI)的存在而罢工,从而导致CFL从actin上脱离,促进actin解聚。不仅如此,他们也观察到已经建立起的突触体积的增大(代表建立了LTP)会因此而逆转。然而这种效用并不是随用随生的,只有在LTP发生的前期(10-30min)才会生效,50min后则就失去了这种魔力,相反如果想防范于未然,早早在LTP发生前就一顿操作,其实是徒劳无功的,就像只有你感冒了喝感冒药才有用一样。不用担心的是,虽然CFL-SN的CALI会短暂的破坏突触里的机械构造,但并不会造成永久性的损伤。
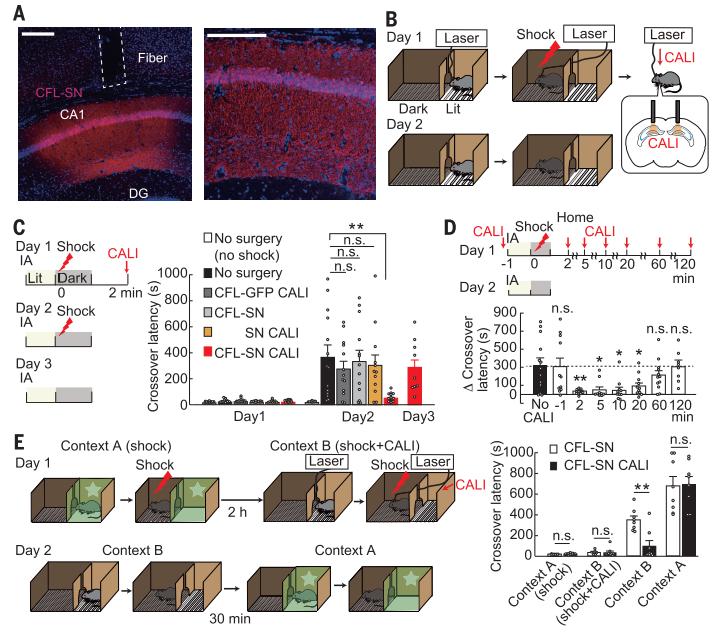
- Goto et al., Science -
技术在手,研究者们接着好奇,这种逆转LTP的方法真的能够某种程度抹去我们的记忆吗?他们在小鼠海马体的兴奋性神经元中特异性表达CFL-SN,并将小鼠们置于抑制性躲避学习训练中。与LTP实验结果一致,只有在电击后20分钟内诱发CALI会明显损伤小鼠的记忆(online LTP)。更进一步,之前的研究表明,小鼠在当天休息(睡觉)期间会重播当天学习的内容,相当于线下复习,这是对当天学习记忆的重要巩固过程(offline LTP)。
研究者们进一步发现,如果在小鼠当天训练完回房休息后持续给光照诱导CALI(持续8h)居然可以完全抹去小鼠的记忆,还真的就是“一闭眼一睁眼,我还是昨天的我”。更为有趣的是,线上和线下的LTP居然对于海马体细胞的表征起到不同的作用,前者控制着神经元选择性放电,而后者则可能更关注神经元活动的同步。为了更进一步探究记忆的转移(海马体-皮层),研究者们选择性的利用CALI抑制前扣带皮层(Anterior cingulate cortex,ACC)的神经元突触可塑性,他们注意到在小鼠训练后的第二天给光照可以非常有效的消除记忆,也就是说记忆在学习的第二天就通过建立皮层神经元中的LTP从海马体转移到皮层了。
突触可塑性与记忆是个已经饱经风霜的研究话题,而这个研究“站在巨人的肩膀上”开发出了一个简单的多功能光遗传技术,通过有选择性(时间和空间)的擦除建立起的LTP非常有效地操控记忆的形成、巩固及调用。这为未来对学习记忆的研究提供了一个强有力的技术手段,并且让我们对记忆的认识又迈出了小小(大大)的一步。看来抹去记忆还真是简单呢,真不知道未来的哪一天会用到我们自己身上呢?
doi: 10.1126/science.abj9195
编者:阿莫東森、Veronica、Orange Soda、图图、肖本
编辑:阿莫東森 | 排版:光影
封面:纪善生
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

