- +1
SRS:流媒体服务器如何实现负载均衡
作者:Winlin、Azusachino、Benjamin
编辑:Alex

▲扫描图中二维码了解音视频技术大会更多信息▲
当我们的业务超过单台流媒体服务器的承受能力,就会遇到负载均衡问题,一般我们会在集群中提供这种能力,但实际上集群并非是唯一的实现方式。有时候负载均衡还会和服务发现等时髦词汇联系起来,而云服务的 LoadBalancer 无疑不可回避,因此,这个问题其实相当复杂,以至于大家会在多个场合询问这个问题,我打算系统地阐述这个问题。
如果你已经知道了以下问题的所有答案,并且深刻了解背后的原因,那么你可以不用看这篇文章了:
SRS 是否需要 Nginx、F5 或 HAProxy 做流代理?不需要,完全不需要,这样是完全误解了流媒体的负载均衡。而 HTTPS 我们却建议这么做,同时为了减少对外服务的 IP 又建议用云 LoadBalancer。
如何发现 SRS 边缘节点?如何发现源站节点?对于边缘,通常 DNS 和 HTTP-DNS 都可以;而源站是不应该直接暴露给客户端直接连接的。
WebRTC 在服务发现上有什么区别?由于 CPU 性能损耗更大,负载均衡的阈值更低;在单 PeerConnection 时流会动态变化,导致更难负载均衡;移动端 UDP 的切网和 IP 漂移,会引入更多问题。
DNS 和 HTTP-DNS 哪个更合适作为流媒体服务器的服务发现机制?肯定是 HTTP-DNS,因为流媒体服务器的负载变化,比 Web 服务器的变化更大,考虑新增 1K 的客户端对于两种不同服务器的负载影响。
负载均衡是否只需要考虑如何降低系统负载?首要目标是考虑降低系统负载,或者防止系统过载导致质量问题甚至崩溃;同时在同等负载时,也需要考虑就近服务和成本因素。
负载均衡是否只能靠增加一层服务器?一般大型的 CDN 分发系统,明显是分层的,无论是静态的树设计,还是动态的 MESH 设计,在流的传输上都是靠分层增加负载能力;同时,还能通过端口重用(REUSEPORT)方式,用多进程方式增加节点的负载而不会增加层。
负载均衡是否只能使用集群方式实现?集群是基本的增加系统容量的方式,除此之外,也可以通过业务分离配合 Vhost 实现系统隔离,或者通过一致性 hash 来分流业务和用户。
好吧,让我们详细聊聊负载和负载均衡。
What is Load?
在解决系统均衡问题时,首先我们看看什么是负载?对于服务器来说,负载就是因为有客户端的访问,而导致的资源消耗上升。当资源消耗出现严重不均衡,可能会导致服务不可用,比如 CPU 跑满了,所有客户端都会变得不正常。
对于流媒体服务器而言,就是流媒体客户端导致的服务器资源消耗。一般我们会从服务器资源消耗角度度量系统负载:
CPU: 服务器消耗的 CPU,一般我们称 CPU 消耗较多的为计算密集型场景,而把网络带宽消耗较多的称为 IO 密集型场景。直播场景一般属于 IO 密集型场景,CPU 一般不会首先成为瓶颈;而在 RTC 中却不是,RTC 是 IO 和计算都很密集,这是非常大的差异。
网络带宽: 传输流媒体时需要消耗网络带宽,也就是上文介绍的 IO 密集型场景。流媒体肯定是 IO 密集型场景,所以带宽一定是重要的瓶颈。而有些场景比如 RTC 同时还是计算密集场景。
磁盘: 如果不需要录制和支持 HLS,那么磁盘就不是重要的瓶颈,如果一定开启录制和 HLS,那么磁盘将变得非常关键,因为磁盘是最慢的。当然由于现在内存较多,所以一般我们采用挂内存盘的方式避免这个问题。
内存: 相对而言,内存是流媒体服务器中消耗较少的资源,尽管做了不少 Cache,但是内存一般还是不会首先达到瓶颈。所以一般内存也会在流媒体服务器中大量用作 Cache,来交换其他的资源负载,比如 SRS 在直播 CPU 优化时,用 writev 缓存和发送大量数据,就是用高内存换得 CPU 降低的策略。
当负载过高,会有什么问题?负载过高会导致系统直接出现问题,比如延迟增大,卡顿,甚至不可用。而这些负载的过载,一般都会有连锁反应。比如:
CPU: CPU 过高会引起连锁反应,这时候意味着系统无法支持这么多客户端,那么会导致队列堆积,从而引起内存大量消耗;同时网络吞吐也跟不上,因为客户端无法收到自己需要的数据,出现延迟增大和卡顿;这些问题反而引起 CPU 更高,直到系统崩溃。
网络带宽: 若超过系统的限定带宽,比如网卡的限制,或者系统队列的限制,那么会导致所有用户都拿不到自己需要的数据,出现卡顿现象。另外也会引起队列增大,而处理堆积队列,一般需要消耗 CPU,所以也会导致 CPU 上升。
磁盘: 若超过磁盘负载,可能会导致写入操作挂起。而在同步写入的服务器,会导致流无法正常传输,日志堆积。在异步写入的服务器,会导致异步队列堆积。注意目前 SRS 是同步写入,正在进行多线程异步写入。
内存: 超过内存会 OOM,直接干掉服务器进程。一般内存主要是泄露导致的缓慢上涨,特别是在流很多时,SRS 为了简化问题,没有清理和删除流,所以若流极其多,那么内存的持续上涨是需要关注的。
由此可见,系统的负载,首先需要被准确度量,也就是关注的是过载或超载(Overload)情况,这个问题也需要详细说明。
What is Overload?
超过系统负载就是超载或过载(Overload),这看起来是个简单的问题,但实际上却并不简单,比如:
CPU 是否超过 100% 就是过载?不对,因为一般服务器会有多个 CPU,也就是 8 个 CPU 的服务器,实际上能达到 800%。
那 CPU 是否不超过总 CPU 使用率,比如 8CPU 的服务器不超过 800% 就不会过载?不对,因为流媒体服务器不一定能用多核,比如 SRS 就是单核,也就是它最多跑 100%。
那是否 SRS 不超过 100% 使用率,就不会过载?不对,因为其他的进程可能也在消耗,不能只看 SRS 的 CPU 消耗。
因此,对于 CPU 来说,知道流媒体服务器能消耗多少 CPU,获取流媒体服务器的 CPU 消耗,才能准确定义过载:
系统总 CPU,超过 80% 认为过载,比如 8CPU 的服务器,总 CPU 超过 640% 就认为过载,一般系统的 load 值也升很高,代表系统很繁忙。
SRS 每个进程的 CPU,超过 80% 认为过载,比如 8CPU 的服务器总 CPU 只有 120%,但 SRS 的进程占用 80%,其他占用 40%,那么此时也是过载。
网络带宽,一般是根据以下几个指标判断是否过载,流媒体一般和流的码率 Kbps 或 Mpbs 有关,代表这个流每秒是多少数据传输:
是否超过服务器出口带宽,比如云服务器公网出口是 10Mbps,那么如果平均码率是 1Mbps 的直播流,超过 10 个客户端就过载了。如果 100 个客户端都来推拉流,那么每个客户端只能传输 100Kbps 的数据,当然会造成严重卡顿。
是否超过内核的队列,在 UDP 中,一般系统默认的队列大小只有 256KB,而流媒体中的包数目和字节,在流较多时远远超过了队列长度,会导致没有超过服务器带宽但是出现丢包情况,具体参考《SRS 性能 (CPU)、内存优化工具用法》(https://www.jianshu.com/p/6d4a89359352)这部分内容。
是否超过客户端的网络限制,有时候某些客户端的网络很差,出现客户端的网络过载。特别是直播推流时,需要重点关注主播上行的网络,没经验的主播会出现弱网等,导致所有人卡顿。
磁盘,主要涉及的是流的录制、日志切割以及慢磁盘导致的 STW 问题:
若需要录制的流较多,磁盘作为最慢的设备,会明显成为瓶颈。一般在系统设计时,就需要避免这种情况,比如 64GB 内存的服务器,可以分 32GB 的内存盘,给流媒体服务器写临时文件。或者使用较小的内存盘,用外部的程序比如 node.js,开启多线程后,将文件拷贝到存储或发送到云存储,可以参考 srs-cloud(https://github.com/ossrs/srs-cloud)的最佳实践。
服务器的日志,在一些异常情况下,可能会造成大量写入,另外如果持续累计不切割和清理,会导致日志文件越来越大,最终写满磁盘。SRS 支持 logrotate,另外 docker 一般也可以配置 logrotate,通常会将日志做提取后(日志少可以直接采集原始日志),传输到云的日志服务做分析,本地只需要存储短时间比如 15 天日志。
STW 问题,写磁盘是阻塞操作,特别是挂载的网络磁盘(比如 NAS),挂载到本地文件系统,而服务器在调用 write 写入数据时,实际上可能有非常多的网络操作,那么这种其实会更消耗时间。SRS 目前应该完全避免挂载网络磁盘,因为每次阻塞都会导致整个服务器 STW(世界暂停)不能处理其他请求。
内存主要是涉及泄露和缓存问题,主要的策略是监控系统整体的内存,相对比较简单。
Special for Media Server
除了一般的资源消耗,在流媒体服务器中,还有一些额外因素会影响到负载或者负载均衡,包括:
长连接: 直播和 WebRTC 的流都是长时间,最长的直播可能超过 2 天,而会议开几个小时也不是难事。因此,流媒体服务器的负载是具有长连接特性,这会对负载均衡造成很大的困扰,比如轮询调度策略可能不是最有效的。
有状态: 流媒体服务器和客户端的交互比较多,中间保存了一些状态,这导致负载均衡服务器无法直接在服务出现问题时,把请求直接给一台新的服务器处理,甚至都不是一个请求,这个问题在 WebRTC 中尤其明显,DTLS 和 SRTP 加密的这些状态,使得不能随意切换服务器。
相关性: 两个 Web 请求之间是没有关联的,一条失败并不会影响另外一条。而在直播中,推流能影响所有的播放;在 WebRTC 中,只要有一个人拉流失败或传输质量太差,尽管其他流都表现良好,但这个会议可能还是开不下去。
这些问题当然不完全是负载和负载均衡问题,比如 WebRTC 支持的 SVC 和 Simulcast 功能,目的就是为了解决某些弱客户端的问题。有些问题是可以通过客户端的失败重试解决,比如高负载时的连接迁移,服务器可以强制关闭,客户端重试迁移到下一个服务器。
还有一种倾向,就是避免流媒体服务,而是用 HLS/DASH/CMAF 等切片,这就变成了一个 Web 服务器,上面所有的问题就突然没有了。但是,切片协议实际上只能做到 3 秒,或者比较常见的 5 秒以上的延迟场景,而在 1 到 3 秒的直播延迟,或者 500ms 到 1 秒的低延迟直播,以及 200ms 到 500ms 的 RTC 通话,以及 100ms 之内的控制类场景,永远都不能指望切片服务器,这些场景只能使用流媒体服务器实现,不管里面传输的是 TCP 的流,还是 UDP 的包。
我们在系统设计时,需要考虑这些问题,例如 WebRTC 应该尽量避免流和房间耦合,也就是一个房间的流一定需要分布到多个服务器上,而不是限制在一台服务器。这些业务上的限制越多,对于负载均衡越不利。
SRS Overload
现在特别说明 SRS 的负载和过载情况:
SRS 的进程: 若 CPU 超过 100%,则过载。SRS 是单线程设计,无法使用多个 CPU 的能力(这个后面我会详细展开讲讲)。
网络带宽: 一般是最快达到过载的资源,比如直播中达到 1Gbps 吞吐带宽时可能 CPU 还很空闲,RTC 由于同时是计算密集型,稍微有些差异。
磁盘: 除了非常少的路数的流的录制,一般需要规避磁盘问题,挂载内存盘,或者降低每个 SRS 处理的流的路数。参考 srs-cloud (https://github.com/ossrs/srs-cloud) 的最佳实践。
内存: 一般是使用较少的资源,在流路数特别特别多,比如监控场景不断推流和断开的场景,需要持续关注 SRS 的内存上涨。这个问题可以通过 Gracefully Quit (https://github.com/ossrs/srs/issues/413#issuecomment-917771521) 规避。
特别说明一下 SRS 单线程的问题,这其实是个选择,没有免费的性能优化,多线程当然能提升处理能力,同时是以牺牲系统的复杂度为代价,同时也很难评估系统的过载,比如 8 核的多线程的流媒体服务器 CPU 多少算是过载?640%?不对,因为可能每个线程是不均匀的,要实现线程均匀就要做线程的负载调度,这又是更复杂的问题。
目前 SRS 的单线程,能适应绝大多数场景。对于直播来说,Edge 可以使用多进程 REUSEPORT 方式,侦听在同样端口,实现消耗多核;RTC 可以通过一定数量的端口;或者在云原生场景,使用 docker 跑 SRS,可以起多个 K8s 的 Pod,这些都是可选的更容易的方案。
Note: 除非是对成本非常敏感的云服务,那么肯定可以自己定制,可以付出这个复杂性的代价了。据我所知,几个知名的云厂商,基于 SRS 实现了多线程版本。我们正在一起把多线程能力开源出来,在可以接受的复杂度范围提升系统负载能力,详细请参考 https://github.com/ossrs/srs/issues/2188。
我们了解了流媒体服务器的这些负载,接下来该考虑如何分担这些负载了。
Round Robin:Simple and Robust
Round Robin 是非常简单的负载均衡策略:每次客户端请求服务时,调度器从服务器列表中找到下一个服务器给客户端,非常简单:
server = servers[pos++ % servers.length()]
如果每个请求是比较均衡的,比如 Web 请求一般很短时间就完成了,那么这种策略是比较有效的。这样新增和删除服务器,上线和下线,升级和隔离,都非常好操作。
流媒体长连接的特点导致轮询的策略并不好用,因为有些请求可能会比较久,有些比较短,这样会造成负载不均衡。当然,如果就只有少量的请求,这个策略依然非常好用。
SRS 的 Edge 边缘集群中,在寻找上游 Edge 服务器时,使用的也是简单的 Round Robin 方式,这是假设流的路数和服务时间比较均衡,在开源中是比较合适的策略。本质上,这就是上游 Edge 服务器的负载均衡策略,相当于是解决了总是回源到一台服务器的过载问题。如下图所示:
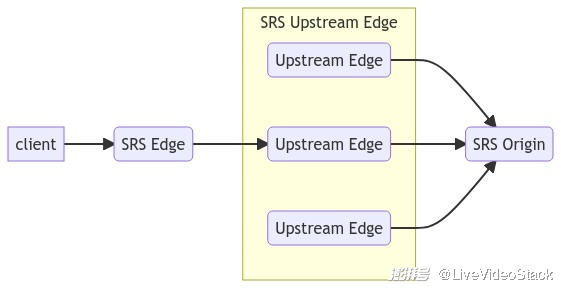
源站集群中,第一次推流时,Edge 也会选择一台 Origin 服务器,使用的也是 Round Robin 策略。这本质上就是 Origin 服务器的负载均衡策略,解决的是 Origin 服务器过载问题。如下图所示:

在实际业务中,一般并不会使用纯粹的 Round Robin,而是有个调度服务,会收集这些服务器的数据,评估负载,给出负载比较低或者质量高的服务器。如下图所示:
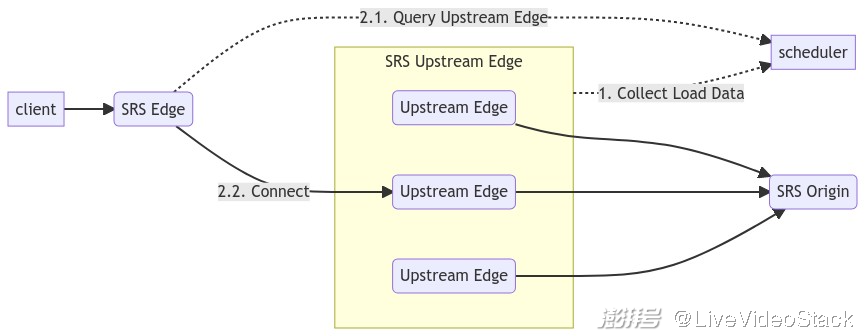
如何解决 Edge 的负载均衡问题呢?依靠的是 Frontend Load Balance 策略,也就是前端接入侧的系统,我们下面讲常用的方式。
Frontend Load Balancer: DNS or HTTP DNS
我们在 Round Robin 中重点介绍了服务内部的负载均衡,而直接对客户端提供服务的服务器,一般叫做 Frontend Load Balancer,情况会有点不太一样:
若整个流媒体服务节点较少,而且是中心化部署,那么也可以用 Round Robin 的方式。在 DNS 中设置多个解析 IP,或者 HTTP DNS 返回时随机选择节点,或者选择相对较轻的负载的机器,也是可行的方案。
在较多节点,特别是分布式部署的节点中,是不可能选择 Round Robin 的方案,因为除了负载之外,还需要考虑用户的地理位置,一般来说会选择分配 “就近” 的节点。同样 DNS 和 HTTP DNS 也能做到这点,一般是根据用户的出口 IP,从 IP 库中获取地理位置信息。
其实 DNS 和 HTTP DNS 在调度能力上没有区别,甚至很多 DNS 和 HTTP DNS 系统的决策系统都是同一个,因为它们要解决的问题是一样的:如何根据用户的 IP,或者其他的信息(比如 RTT 或探测的数据),分配比较合适的节点(一般是就近,但也要考虑成本)。
DNS 是互联网的基础,可以认为它就是一个名字翻译器,比如我们在 PING SRS 的服务器时,会将 ossrs.net 解析成 IP 地址 182.92.233.108,这里完全没有负载均衡的能力,因为就一台服务器而已,DNS 在这里只是名字解析:
ping ossrs.net PING ossrs.net (182.92.233.108): 56 data bytes 64 bytes from 182.92.233.108: icmp_seq=0 ttl=64 time=24.350 ms
而 DNS 在流媒体负载均衡时的作用,其实是会根据客户端的 IP,返回不同服务器的 IP,而 DNS 系统本身也是分布式的,在播放器的 /etc/hosts 文件中就可以记录 DNS 的信息,如果没有就会在 LocalDNS(一般在系统中配置或自动获取)查询这个名字的 IP。
这意味着 DNS 能抗住非常大的并发,因为并不是一台中心化的 DNS 服务器在提供解析服务,而是分布式的系统。这就是为何新建解析时会有个 TTL(过期时间),修改解析记录后,在这个时间之后才会生效。而实际上,这完全取决于各个 DNS 服务器自己的策略,而且还有 DNS 劫持和篡改等操作,所以有时候也会造成负载不均衡。
因此 HTTP DNS 就出来了,可以认为 DNS 是互联网的运营商提供的网络基础服务,而 HTTP DNS 则可以由流媒体平台也就是各位自己来实现,就是一个名字服务,也可以调用一个 HTTP API 来解析,比如:
curl http://your-http-dns-service/resolve?domain=ossrs.net {["182.92.233.108"]}
由于这个服务是自己提供的,可以自己决定什么时候更新该名字代表的含义,当然可以做到更精确的负载,也可以用 HTTPS 防止篡改和劫持。
Note: HTTP-DNS 的这个 your-http-dns-service 接入域名,则可以用一组 IP,或者用 DNS 域名,因为它只有少数节点,所以它的负载相对比较好均衡。
Load Balance by Vhost
SRS 支持 Vhost,一般是 CDN 平台用来隔离多个客户,每个客户可以有自己的 domain 域名,比如:
vhost customer.a { } vhost customer.b { }
如果用户推流到同一个 IP 的服务器,但是用不同的 Vhost,它们也是不同的流,播放时地址不同也是不同的流,例如:
• rtmp://ip/live/livestream?vhost=customer.a
• rtmp://ip/live/livestream?vhost=customer.b
Note:当然,可以直接用 DNS 系统,将 IP 映射到不同的域名,这样就可以直接在 URL 中用域名代替 IP 了。
其实 Vhost 还可以用作多源站的负载均衡,因为在 Edge 中,可以将不同的客户分流到不同的源站,这样可以不用源站集群也可以扩展源站的能力:
vhost customer.a { cluster { mode remote; origin server.a; } } vhost customer.b { cluster { mode remote; origin server.a; } }
那么不同的 Vhost 实际上共享了 Edge 节点,但是 Upstream 和 Origin 可以是隔离的。当然也可以配合 Origin Cluster 来做,这时候就是多个源站中心,和 Consistent Hash 要实现的目标有点像了。
Consistent Hash
在 Vhost 隔离用户的场景下,会导致配置文件比较复杂,还有一种更简单的策略,也可以实现类似的能力,那就是一致性 Hash(Consistent Hash)。
比如,可以根据用户请求的 Stream 的 URL 做 Hash,决定回源到哪个 Upstream 或 Origin,这样就一样可以实现同样的隔离和降低负载。
实际应用中,已经有这种方案在线上提供服务,所以方案上肯定是可行的。当然,SRS 没有实现这个能力,需要自己码代码实现。
其实 Vhost 或者 Consistent Hash,也可以配合 Redirect 来完成更复杂的负载均衡。
HTTP 302: Redirect
302 是重定向(Redirect),实际上也可以用作负载均衡,比如通过调度访问到服务器,但是服务器发现自己的负载过高,那么就给定向到另外一台服务器,如下图所示:
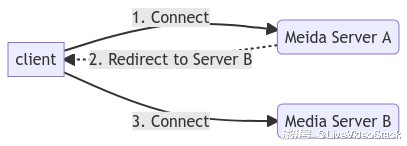
Note: 除了 HTTP 302,实际上 RTMP 也支持 302,SRS 的源站集群就是使用这个方式实现的。当然这里 302 主要用于流的服务发现,而不是用于负载均衡。
既然 RTMP 也支持 302,那么在服务内部,完全可以使用 302 来实现负载的再均衡。若某个 Upstream 的负载过高,就将流调度到其他的节点,并且可以做多次 302 跳转。
一般在 Frontend Server 中,只有 HTTP 流才支持 302,比如 HTTP-FLV 或者 HLS。而 RTMP 是需要客户端支持 302,这个一般支持得很少,所以不能使用。
另外,基于 UDP 的流媒体协议,也有支持 302 的,比如 RTMFP,一个 Adobe 设计的 Flash 的 P2P 的协议,也支持 302。当然目前用得很少了。
WebRTC 目前没有 302 的机制,一般是依靠 Frontend Server 的代理,实现后续服务器的负载均衡。而 QUIC 作为未来 HTTP3 的标准,肯定是会支持 302 这种基本能力的。而 WebRTC 逐渐也会支持 WebTransport(基于 QUIC),因此这个能力在未来也会具备。
SRS: Edge Cluster
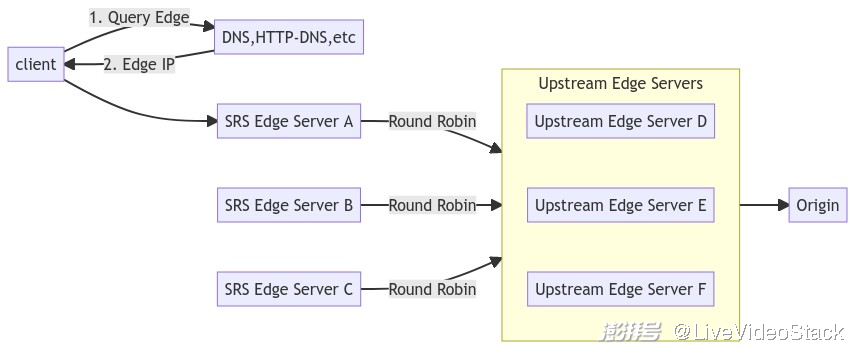
SRS Edge 本质上就是 Frontend Server,它可以解决以下问题:
直播的播放能力扩展问题,比如支持 10 万人观看,可以水平扩展 Edge Server。
解决就近服务的问题,和 CDN 起到的作用是一样的,一般会选择和用户所在的城市部署。
Edge 使用 Round Robin 方式连接到 Upstream Edge,实现 Upstream 的负载均衡。
Edge 本身的负载均衡,是依靠调度系统,比如 DNS 或 HTTP-DNS。
如下图所示:
特别说明:
Edge 是直播流的边缘集群,支持 RTMP 和 HTTP-FLV 协议。
Edge 不支持切片比如 HLS 或 DASH,切片协议使用 Nginx 或 ATS 分发。
不支持 WebRTC,WebRTC 有自己的集群机制。
由于 Edge 本身就是 Frontend Server,因此一般不需要为了增加系统容量,再在前面挂 Nginx 或 LB,因为 Edge 本身就是为了解决容量问题,而且只有 Edge 能解决合并回源的问题。
Note:合并回源,指的是同一个流只会回源一次,比如有 1000 个播放器连接到了 Edge,Edge 只会从 Upstream 获取一路流,而不会获取 1000 路流,这和透明 Proxy 是不同的。
当然,有时候还是需要前面挂 Nginx 或 LB,比如:
为了支持 HTTPS-FLV 或 HTTPS-API,Nginx 支持得更好,而且 HTTP/2 也支持。
减少对外的 IP,比如多个服务器对外使用一个 IP,这时候就需要有一台专门的 LB 代理到后端多台 Edge。
在云上部署,只能通过 LB 提供服务,这是云产品的设计导致的,比如 K8s 的 Service。
除此之外,不应该在 Edge 前面再挂其他的服务器,应该直接由 Edge 提供服务。
SRS: Origin Cluster
和 Edge 边缘集群不同,SRS 源站集群主要是为了解决源站扩展能力:
如果有海量的流,比如 1 万路流,那么单个源站是扛不住的,需要多个源站形成集群。
解决源站的单点问题,比如多区域部署,出现问题时自动切换到其他区域。
切片协议的性能问题,由于写入磁盘损耗性能较大,除了内存盘,还可以用多个源站降低负载。
SRS 源站集群是不建议直接对外提供服务,而是依靠 Edge 对外服务,因为使用了两个简单的技术:
流发现:源站集群会访问一个 HTTP 地址查询流,默认是配置为其他源站,也可以配置为一个专门的服务。
RTMP 302 重定向,若发现流不在本源站,那么会定向到其他源站。
Note: 其实 Edge 在回源前也可以先访问流查询服务,找到有流的源站后再发起连接。但是有可能流会切走,所以还是需要一个重新定位流的过程。
这个过程非常简单,如下图所示:
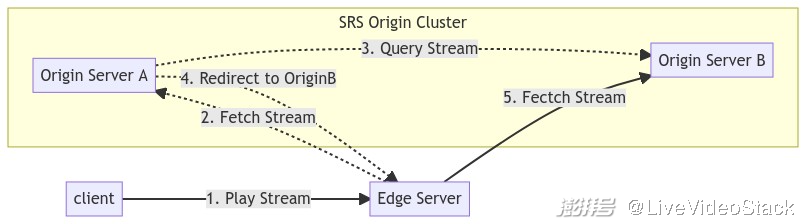
由于流始终只在一个源站上面,因此生成 HLS 切片时也会由一个源站生成,不需要做同步。一般使用共享存储的方式,或者使用 on_hls 将切片发送到云存储。
Note: 还有一种方式,使用双流热备,一般是两个不同的流,在内部实现备份。这种一般需要自己实现,而且对于 HLS、SRT 和 WebRTC 都很复杂,SRS 没有支持也不展开了。
从负载均衡角度看源站集群,实际上是调度器实现的负载均衡,比如 Edge 回源时若使用 Round Robin,或者查询专门的服务应该往哪个源站推流,甚至当源站的负载过高,可以主动断开流,让流重推实现负载的重新均衡。
SRS: WebRTC Casecade
WebRTC 的负载只在源站,而不存在边缘的负载均衡,因为 WebRTC 的推流和观看几乎是对等的,而不是直播这种一对万级别的不对等。换句话说,边缘是为了解决海量观看问题,而推流和观看差不多时就不需要边缘做负载均衡(直播可以用来做接入和跳转)。
WebRTC 由于没有实现 302 跳转,因此接入都没有必要边缘做负载均衡了。比如在一个 Load Balance,也就是一个 VIP 后面有 10 台 SRS 源站,返回给客户端的都是同一个 VIP,那么客户端最终会落到哪个 SRS 源站呢?完全就是看 Load Balance 的策略,这时候并不能像直播一样加一个边缘实现 RTMP 302 的跳转。
因此,WebRTC 的负载均衡,就完全不是 Edge 能解决的,它本来就是依靠源站集群。一般在 RTC 中,这种叫做 Casecade(级联),也就是它们是平等关系,只是一级一级的路由一样地连接起来,增加负载能力。如下图所示:
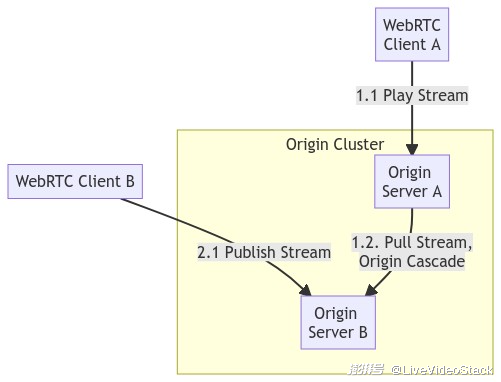
这里和 OriginCluster 有本质的不同,因为 OriginCluster 之间并没有媒体传输,而是使用 RTMP 302 让 Edge 跳转到指定的源站,因为源站的负载是可控的,它最多只有有限个 Edge 来回源取流。
而 OriginCluster 不适合 WebRTC,因为客户端需要直接连接到源站,这时候源站的负载是不可控的。比如在 100 人的会议中,每个流会有 100 个人订阅,这时候需要将每个用户分散到不同的源站上,和每个源站建立连接,实现推流和获取其他人的流。
Note: 这个例子很罕见,一般 100 人互动的会议,会使用 MCU 模式,由服务器合并成一路流,或者选择性的转发几路流,服务器内部的逻辑是非常复杂的。
实际上考虑 WebRTC 的常用场景,就是一对一通话,基本上占了 80% 左右的比例。那么这时候每个人都推一路流,播放一路流,是属于典型的流非常多的情况,那么用户可以完全连接到一个就近的 Origin,而一般用户的地理位置并不相同,比如在不同的地区或国家,那么源站之间级联,可以实现提高通话质量的效果。
在源站级联的结构下,用户接入使用 DNS 或 HTTP DNS 协议访问 HTTPS API,而在 SDP 中返回源站的 IP,因此这就是一次负载均衡的机会,可以返回离用户比较接近而且负载较低的源站。
此外,多个源站如何级联,若大家地区差不多,可以调度到一台源站避免级联,这可以节约内部的传输带宽(在大量的同地区一对一通话时很值得优化),同时也增加了负载的不可调度性,特别是它们会演变成一个多人会议。
因此,在会议中,区分一对一的会议,和多人会议,或者限制会议人数,对于负载均衡实际上是非常有帮助的。如果能提前知道这是一对一会议,那么就更容易调度和负载均衡。很可惜的是,产品经理一般对这个不感兴趣。
Remark: 特别说明,SRS 的级联功能还没有实现,只是实现了原型,还没有提交到开源仓库。
TURN, ICE, QUIC, etc
特别补充一下 WebRTC 相关的协议,比如 TURN、ICE 和 QUIC 等。
ICE 其实不算一个传输协议,它更像是标识协议,一般指 Binding Request 和 Response,会在里面带有 IP 和优先级信息,来标识地址和信道的信息,用于多条信道的选择,比如 4G 和 WiFi 都很好时优先选谁。还会用作会话的心跳,客户端会一直发送这个消息。
因此 ICE 对于负载均衡没有作用,但是它可以用来标识会话,和 QUIC 的 ConnectionID 作用类似,因此在经过 Load Balance 时可以起到识别会话的作用,特别是客户端的网络切换时。
而 TURN 协议其实是对 Cloud Native 非常不友好的协议,因为它是需要分配一系列的端口,用端口来区分用户,这种是在私有网络中的做法,假设端口无限,而公有云上端口往往是受限的,比如需要经过 Load Balance 这个系统时,端口就是有限的。
Note: 当然 TURN 也可以复用一个端口,而不真正分配端口,这限制了不能使用 TURN 直接通信而是经过 SFU,所以对于 SRS 也没有问题。
TURN 的真正用处是降级到 TCP 协议,因为有些企业的防火墙不支持 UDP,所以只能使用 TCP,而客户端需要使用 TURN 的 TCP 功能。当然了,也可以直接使用 TCP 的 host,比如 mediasoup 就已经支持了,而 SRS 还没有支持。
QUIC 比较友好的是它的 0RTT 连接,也就是客户端会缓存 SSL 的类似 ticket 的东西,可以跳过握手。对于负载均衡,QUIC 更有效的是它有 ConnectionID,那么经过 LoadBalance 时,尽管客户端改变了地址和网络,Load Balance 还是能知道后端哪个服务来处理它,当然这其实让服务器的负载更难以转移了。
其实 WebRTC 这么复杂的一套协议和系统,讲起来都是乱糟糟的,很糟心。由于 100ms 级别的延迟是硬指标,所以必须使用 UDP 和一套复杂的拥塞控制协议,再加上安全和加密也是基本能力,也有人宣称 Cloud Native 的 RTC 才是未来,引入了端口复用和负载均衡,以及长连接和重启升级等问题,还有那改得天翻地覆的结构,以及来搅局的 HTTP3 和 QUIC……
或许对于 WebRTC 的负载均衡,有一句话是最适用的:世上无难事,只要肯放弃。
SRS: Prometheus Exporter
所有负载均衡的前提,就是能知道负载,这依赖数据采集和计算。Prometheus (https://prometheus.io) 就是做这个用的,它会不断采集各种数据,按照它的一套规则,也可以计算这些数据,它本质上就是一个时序数据库。
系统负载,本质上就是一系列的时序数据,会随着时间变化。
比如,Prometheus 有个 node_exporter (https://github.com/prometheus/node_exporter),它提供了主机节点的相关时序信息,比如 CPU、磁盘、网络、内存等,这些信息就可以作为计算服务负载的依据。
每个应用服务,也会有对应的 exporter,比如 redis_exporter (https://github.com/oliver006/redis_exporter) 采集 Redis 的负载数据,nginx-exporter (https://github.com/nginxinc/nginx-prometheus-exporter) 采集 Nginx 的负载数据。
目前 SRS 还没有实现自己的 exporter,未来一定会实现,详细请参考 https://github.com/ossrs/srs/issues/2899。

本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

