- +1
单机超越分布式?强化学习新姿势,并行环境模拟器EnvPool实现速度成本双赢
机器之心专栏
机器之心编辑部
在训练强化学习智能体的时候,你是否为训练速度过慢而发愁?又是否对昂贵的大规模分布式系统加速望而却步?来自 Sea AI Lab 团队的最新研究结果表明,其实鱼和熊掌可以兼得:对于强化学习标准环境 Atari 与 Mujoco,如果希望在短时间内完成训练,需要采用数百个 CPU 核心的大规模分布式解决方案;而使用 EnvPool,只需要一台游戏本就能完成相同体量的训练任务,并且用时不到 5 分钟,极大地降低了训练成本。
 目前,EnvPool 项目已在 GitHub 开源,收获超过 500 Stars,并且受到众多强化学习研究者的关注。
目前,EnvPool 项目已在 GitHub 开源,收获超过 500 Stars,并且受到众多强化学习研究者的关注。项目地址:https://github.com/sail-sg/envpool
在线文档:https://envpool.readthedocs.io/en/latest/
arXiv 链接:https://arxiv.org/abs/2206.10558
EnvPool 是一个基于 C++ 、高效、通用的强化学习并行环境(vectorized environment)模拟器,不仅能够兼容已有的 gym/dm_env API,还支持了多智能体环境。除了 OpenAI Gym 本身拥有的环境外,EnvPool 还支持一些额外的复杂环境。
目前支持的环境有:
Atari games
Mujoco(gym)
Classic control RL envs: CartPole, MountainCar, Pendulum, Acrobot
Toy text RL envs: Catch, FrozenLake, Taxi, NChain, CliffWalking, Blackjack
ViZDoom single player
DeepMind Control Suite
追求极致速度
EnvPool 采取了 C++ 层面的并行解决方案。根据现有测试结果,使用 EnvPool 并行运行多个强化学习环境,能在正常笔记本上比主流的 Python Subprocess 解决方案快近 3 倍;使用多核 CPU 服务器能够达到更好的性能。
例如在 NVIDIA DGX-A100(256 核 CPU 服务器)上的测试结果表明,Atari 游戏能够跑出每秒一百多万帧的惊人速度,Mujoco 物理引擎的任务更是能跑出每秒三百多万模拟步数的好成绩,比 Python Subprocess 快近二十倍,比之前最快的 CPU 异步模拟器 Sample Factory 还快两倍。
与此同时,EnvPool + CleanRL 的整系统测试表明,使用原始的 PPO 算法,直接把原来基于 Python Subprocess 的主流解决方案替换成 EnvPool,整体系统在标准的 Atari 基准测试中能快近三倍!
标准测试结果表明,对于数量稍大(比如超过 32)的并行环境,Subprocess 的运行效率十分堪忧。
为此有研究者提出分布式解决方案(比如 Ray)和基于 GPU 的解决方案(比如 Brax 和 Isaac-gym)进行加速。分布式方案经过测试,计算资源利用率其实并不高;基于 GPU 的解决方案虽然可以达到千万 FPS,但并不是所有环境都能使用 CUDA 重写,不能很好兼容生态以及不能复用一些受商业保护的代码。
EnvPool 由于采用了 C++ 层面的并行解决方案,并且大部分强化学习环境都使用 C++ 实现来保证运行效率,因此只需要在 C++ 层面实现接口即可完成高效的并行。
打造开放生态
EnvPool 对上下游的生态都有着良好的支持:
对于上游的强化学习环境而言,目前最多使用的是 OpenAI Gym,其次是 DeepMind 的 dm_env 接口。EnvPool 对两种环境 API 都完全支持,并且每次 env.step 出来的数据都是经过 numpy 封装好的,用户不必每次手动合并数据,同时也提高了吞吐量;
对于下游的强化学习算法库而言,EnvPool 支持了目前 PyTorch 最为流行的两个算法库 Stable-baselines3 和 Tianshou,同时还支持了 ACME、CleanRL 和 rl_games 等强化学习算法库,并且达到了令人惊艳的效果(在笔记本电脑上,2 分钟训练完 Atari Pong、5 分钟训练完 Mujoco Ant/HalfCheetah,并且通过了 Gym 原本环境的验证)。
为了更好地营造生态,EnvPool 采用了 Bazel 进行构建,拥有完善的软件工程标准,也提供了高质量的代码、单元测试和在线文档。
使用示例
以下是一些简单的 EnvPool 使用示例。首先导入必要的包:
import numpy as np, envpool
以 gym.Env 接口为例,初始化 100 个 Atari Pong 的并行环境,只需要一行代码:
env = envpool.make_gym("Pong-v5", num_envs=100)
访问 observation_space 和 action_space 和 Gym 如出一辙:
observation_space = env.observation_spaceaction_space = env.action_space
在同步模式下,API 与已有的 Gym API 无缝衔接,只不过第一维大小是并行环境个数:
obs = env.reset() # should be (100, 4, 84, 84)act = np.zeros(100, dtype=int)obs, rew, done, info = env.step(act)
当然也可以只 step/reset 部分环境,只需多传一个参数 env_id 即可:
while True: act = policy(obs) obs, rew, done, info = env.step(act, env_id) env_id = info["env_id"]
为了追求极致性能,EnvPool 还支持异步模式的 step/reset,于在线文档和论文中对此进行了详细阐述与实验。
实际体验效果
EnvPool 只需要一句命令 pip install envpool 就能安装,目前仅支持 Linux 操作系统并且 Python 版本为 3.7/3.8/3.9。EnvPool 在短期内会对其他操作系统(Windows 和 macOS)进行支持。
在 EnvPool 的论文中,作者们给出了如下 rl_games 的惊艳结果:只用一台游戏本,在其他条件都完全相同的情况下,把基于 ray 的 vectorized env 实现直接换成 EnvPool,能够直接获得免费的加速。
Atari Pong 使用了 EnvPool,可以在大约 5 分钟的时候训练完成,相比而言 ray 的方案需要在大约 15 分钟的时候训练完成(达到接近 20 的 reward);Mujoco Ant 更为明显,使用原始 PPO 算法在不到 5 分钟的时间内达到了超过 5000 的 reward,而基于 ray 的解决方案运行了半小时还没达到 5000。
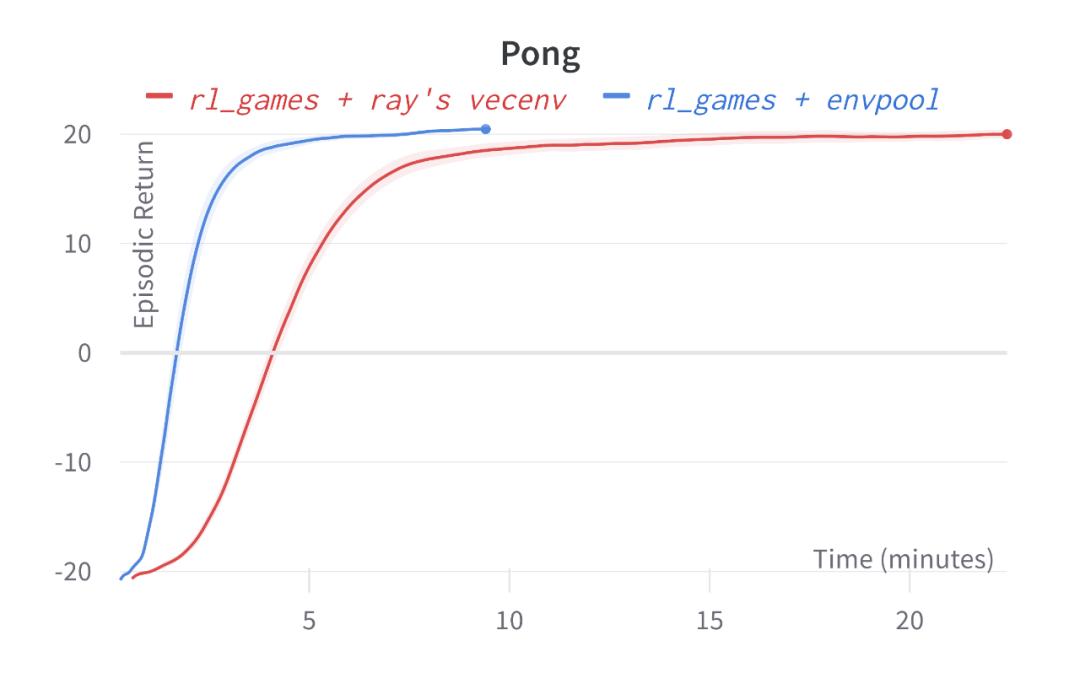
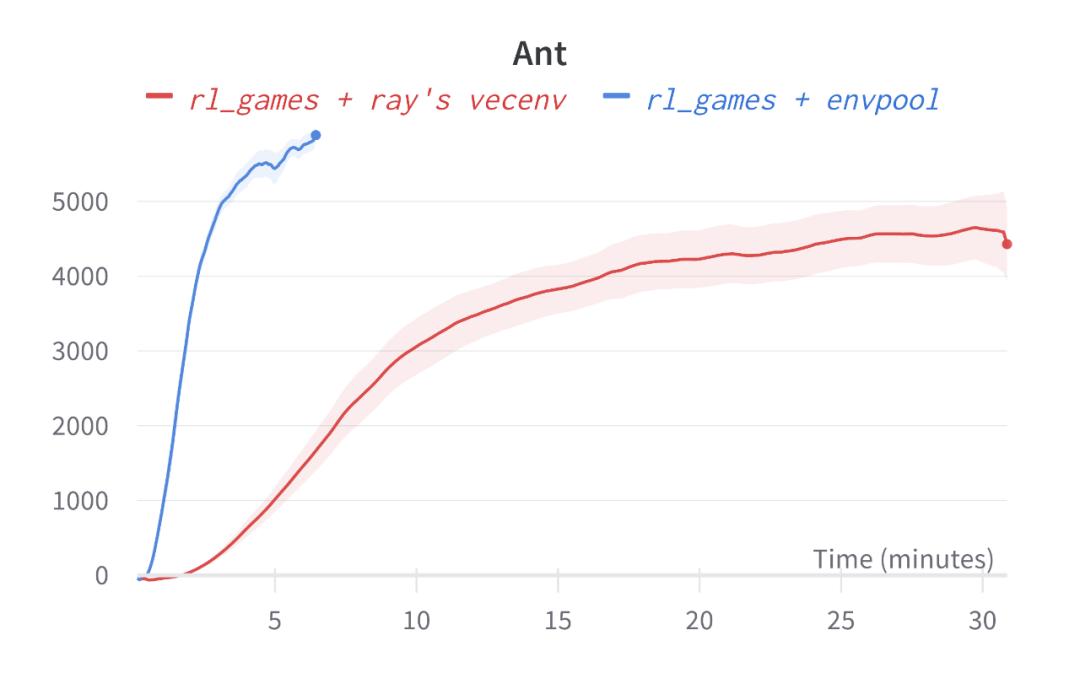 为了验证上述结果的真实性,我们尝试着运行了一下在 EnvPool README 提供的 colab 示例:
为了验证上述结果的真实性,我们尝试着运行了一下在 EnvPool README 提供的 colab 示例:Pong:https://colab.research.google.com/drive/1iWFv0g67mWqJONoFKNWUmu3hdxn_qUf8?usp=sharing
Ant:https://colab.research.google.com/drive/1C9yULxU_ahQ_i6NUHCvOLoeSwJovQjdz?usp=sharing
我们找了台和论文 appendix 中与 rl_games 的实验类似配置的机子:
OS: Debian GNU/Linux 11 (bullseye) x86_64
Kernel: 5.16.0-0.bpo.4-amd64
CPU: AMD Ryzen 9 5950X (32) @ 3.400GHz
GPU: NVIDIA GeForce RTX 3080 Ti
Memory: 128800MiB
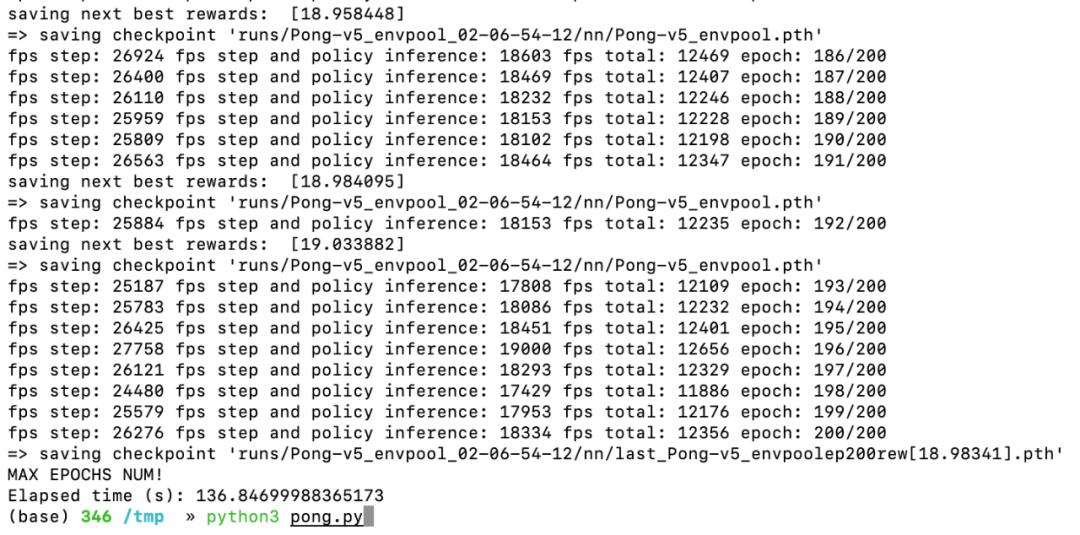
从 colab 的结果来看,Pong 跑到 200 个 epoch 结果已经收敛了,于是设置 200 个 epoch 跑测试,发现在这台测试机上运行代码,居然只需要要 2 分 17 秒就能跑完,并且 reward 能超过 19:
 Ant 跑到 1000 个 epoch 结果差不多收敛了。设置 max_epochs 为 1000 之后运行,在 2 分 36 秒之后运行完毕,并且 reward 超过了 5300:
Ant 跑到 1000 个 epoch 结果差不多收敛了。设置 max_epochs 为 1000 之后运行,在 2 分 36 秒之后运行完毕,并且 reward 超过了 5300: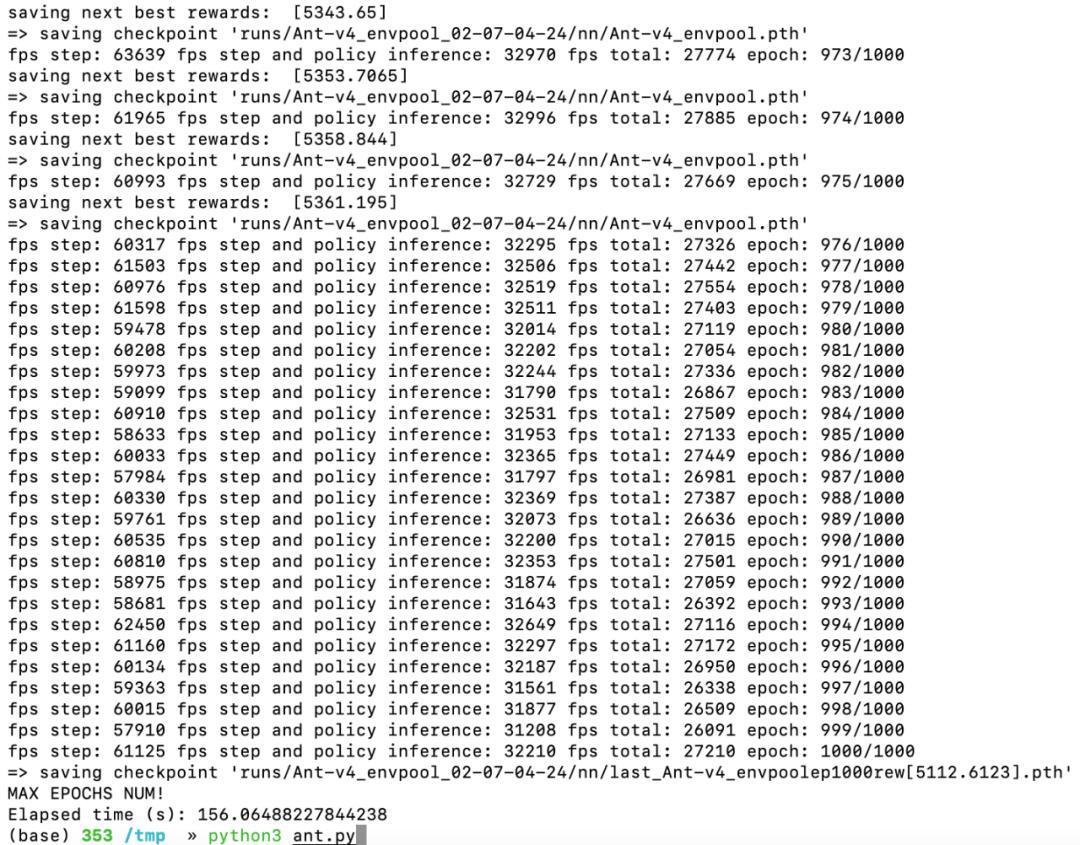
 相比 RLLib 和 SeedRL 等工作,使用几百个 CPU 核心的分布式计算,EnvPool + rl_games 只用了单机做到了同样的效果(甚至更好),确实不错。
相比 RLLib 和 SeedRL 等工作,使用几百个 CPU 核心的分布式计算,EnvPool + rl_games 只用了单机做到了同样的效果(甚至更好),确实不错。项目作者
Jiayi Weng(翁家翌)是强化学习算法库 Tianshou(天授)的第一作者,目前的研究兴趣主要是对机器学习与强化学习系统进行加速。该项目是他在 Sea AI Lab 的实习项目。CMU 硕士毕业后入职 OpenAI 当任 Research Engineer。
Min Lin(林敏)是 Network in network 的第一作者,在图灵奖获得者 Yoshua Bengio 下从事多年博士后研究,目前就职于 Sea AI Lab;
Shengyi Huang(黄晟益)是 CleanRL 的第一作者,目前在 Drexel University 攻读计算机博士学位。
Bo Liu(刘博)是 TorchOpt 的共同第一作者,目前在北京大学担任研究助理。
Denys Makoviichuk 是 rl_games 的第一作者,目前就职于 Snap 担任多年机器学习部门经理。
Viktor Makoviychuk 目前就职于 NVIDIA,是 Isaac-gym 的第一作者。
Zichen Liu (刘梓辰)就职于 Sea AI Lab,同时也是新加坡国立大学 NUS 的博士生。
Yufan Song(宋宇凡)、Ting Luo(罗婷)、Yukun Jiang(蒋宇昆)是 CMU MCDS 项目的在读学生。
Zhongwen Xu(徐仲文)曾在 DeepMind 担任 Research Scientist,目前就职于 Sea AI Lab。
Shuicheng Yan(颜水成),Sea AI Lab负责人、Sea集团首席科学家。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《单机超越分布式?!强化学习新姿势,并行环境模拟器EnvPool实现速度成本双赢》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

