- +1
腾讯自研新一代AV1编解码器
编者按: 近年来,腾讯云在编解码领域投入了许多,不同于许多厂商基于开源方案做增强,腾讯从 2017 年就开始自研编解码器包括现在的 AV1。LiveVideoStackCon 2022 音视频技术大会上海站邀请到腾讯云香农实验室编解码器研发负责人张贤国老师,为大家介绍腾讯自研 AV1 编解码器。
文 / 张贤国
整理 / LiveVideoStack

本次和大家分享的主题是《腾讯自研新一代 AV1 编码器》,距离我上一次 2019 年在 LiveVideoStackCon2019 北京站演讲已经过去了快三年,这次就和大家分享下闭关两三年中我们团队进行了哪些工作。
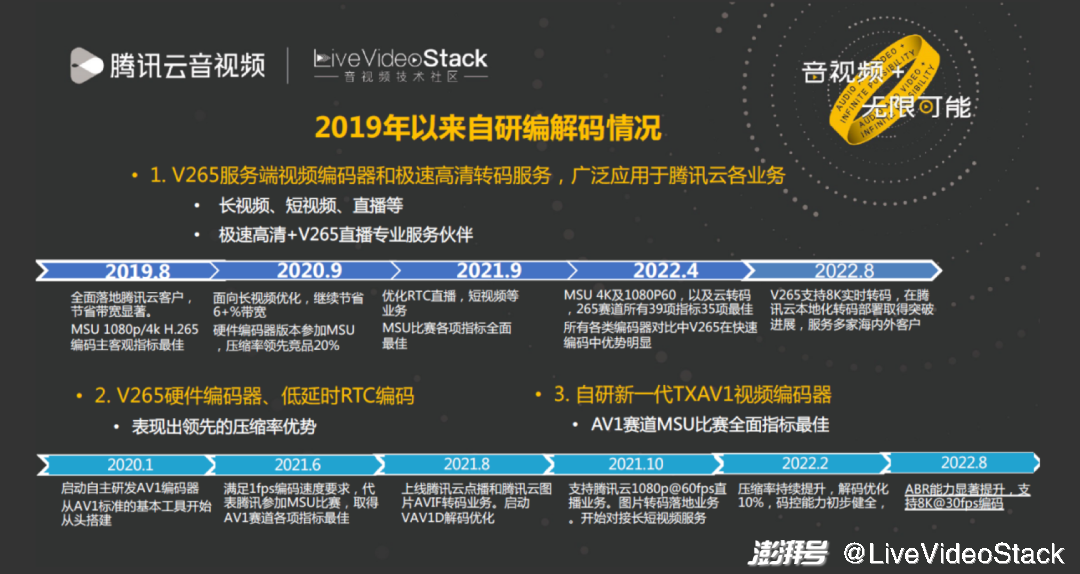
首先,我们继续优化了 V265 编码器,并在腾讯云全面落地,服务多家海内外的客户,265 各赛道中的成绩也一直保持领先。其次,新研发了 V265 硬件编码器,低延时 RTC 编码及其在终端的应用,与其他团队合作研发了腾讯的沧海芯片。第三,从 2020 年开始启动自研了新一代 TXAV1 视频编码器,在去年的比赛及推广业务中都取得了不错的成绩。去年上半年开始在腾讯云落地,如 60fps 直播以及最近开始支持 8K30fps,整个周期沿用了 V265 的思路,按部就班地从头开始做,从标准协议出发优化整个编码器。

2020 年决定研发 AV1 编码器之前,我们分别从三个方面进行了调研。
第一,当时的开源软件很丰富,这意味着良好的生态,在调研了 Google 的 LibAOM、SVT-AV1 的开源编码器后,我们发现 AV1 对比 V265 确实有性能提升。
第二,AV1 的代码还有优化空间,我们许多成熟的优化思路是 AV1 所没有的,在这一点就可以做出差距。
第三,AV1 的市场比较成熟,2020 年就有 MTK 芯片的支持,一旦有了 MTK 芯片,其他厂商也会陆续进入市场。另外,当时 AV1 的开源解码器就超过了 openhevc,Android、浏览器的支持也很丰富。AV1 在 Youtube 也有很多落地,最近的调研发现有 30%-35% 的视频支持 AV1,而且首页的热门视频都更偏向于使用 AV1 进行播放。
以上几点都是促使我们最终选择 AV1 编码器的原因,而且因为我们部门服务于云部门,所以需要研发出能够尽快落地的产品。
如今回过头看我们的决策是正确的。首先,硬件解码器,除了 MTK 的一系列手机支持硬解之外,三星的 S21、S22、骁龙的下一代也都支持 AV1 硬解,而且现在很多显卡也支持 AV1 硬解。最新的 Apple 软件框架中也添加了 AV1 选项,从生态角度来看,AV1 更加成熟。另外从自研角度,也证明了我们确实能做出和开源的差异,并且在去年的比赛中都取得了较好的成绩。
1、TXAV1 编解码器能力及落地应用
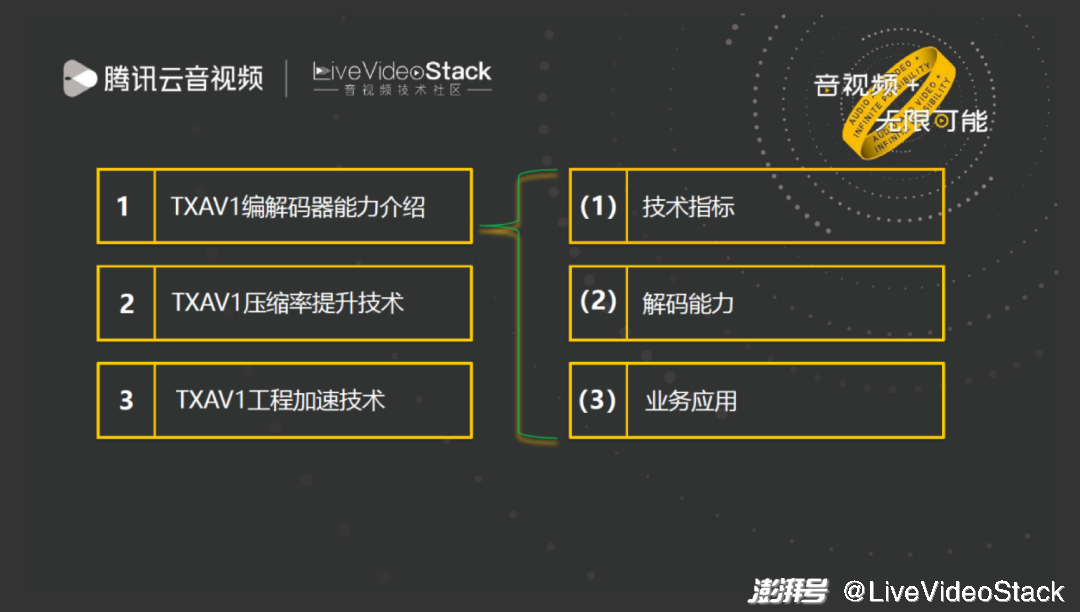
接下来我将从以下三方面进行分享。
第一是 TXAV1 编解码器能力,第二第三点都是技术干货,包括 TXAV1 压缩率提升技术和 TXAV1 工程加速技术。
从压缩性能上,总体来讲,TXAV1 可以实现:
(1)相比 SVT-110 最高压缩率配置 加速 78% 时带宽节省 12-16%,加速 78 倍时仍有带宽节省
(2)相比 AOM-3.2 最高压缩率配置 加速 10.7 倍时带宽节省 12-20%,加速 613 倍时仍有带宽节省
(3)相比 VVenc 最高压缩率配置,在加速 11 倍下,压缩率相当.
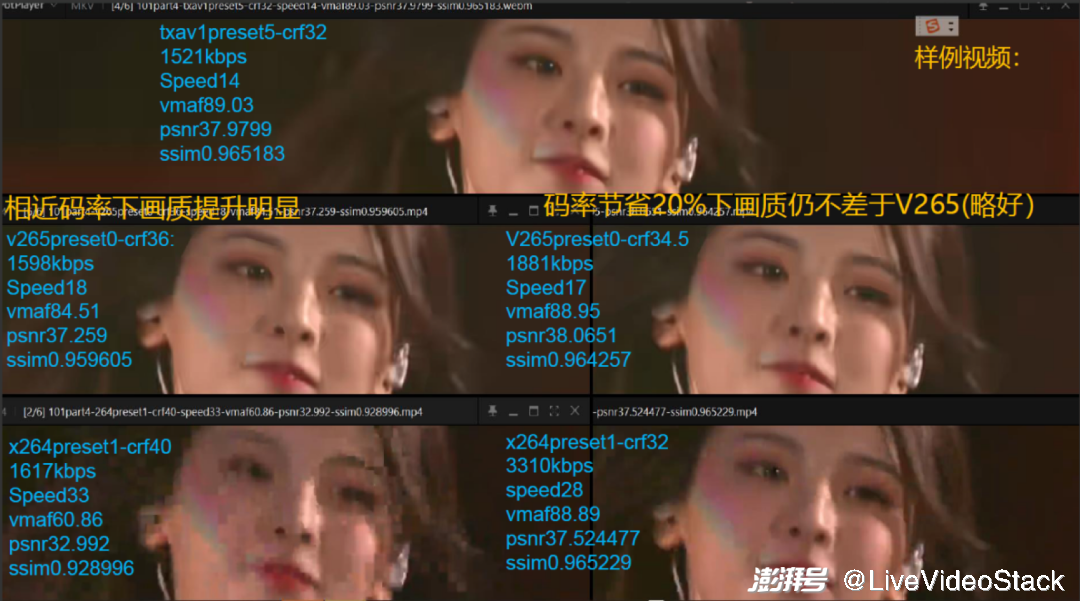
在此我们还测试了主观感受。图中可以发现 1.5M 码率情况下,对比 265 有明显的性能提升,即使在节省 20% 带宽情况下,画质仍略好于 265,也就是 TXAV1 对比自研 265 也有主观画质的提升。
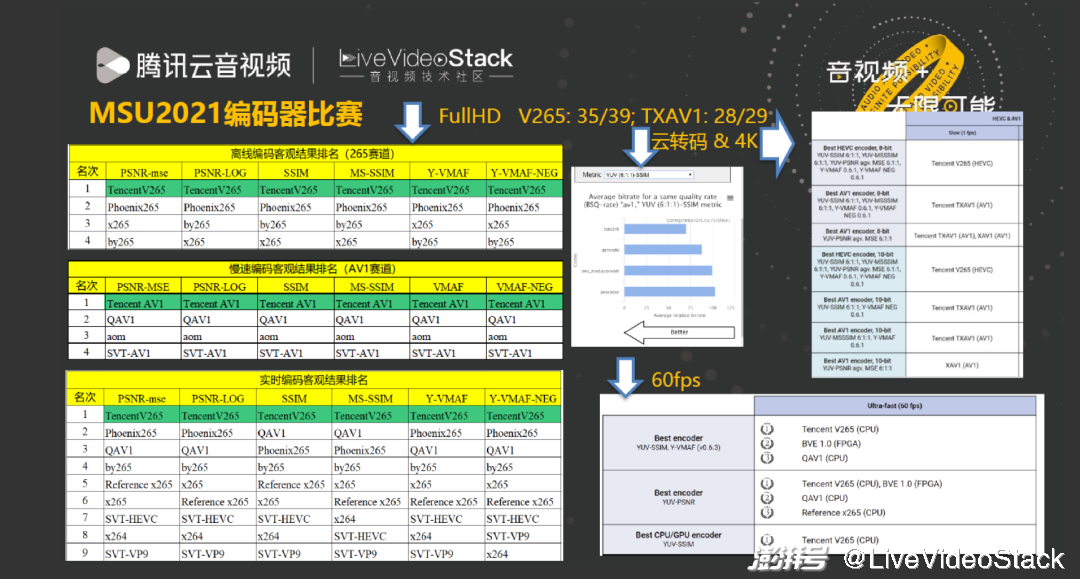
在去年的比赛中,关于 AV1 的比赛指标 TXAV1 参加了 29 项,我们取得了 28 项领先,265 有 39 项比赛指标,我们取得了 35 项领先。
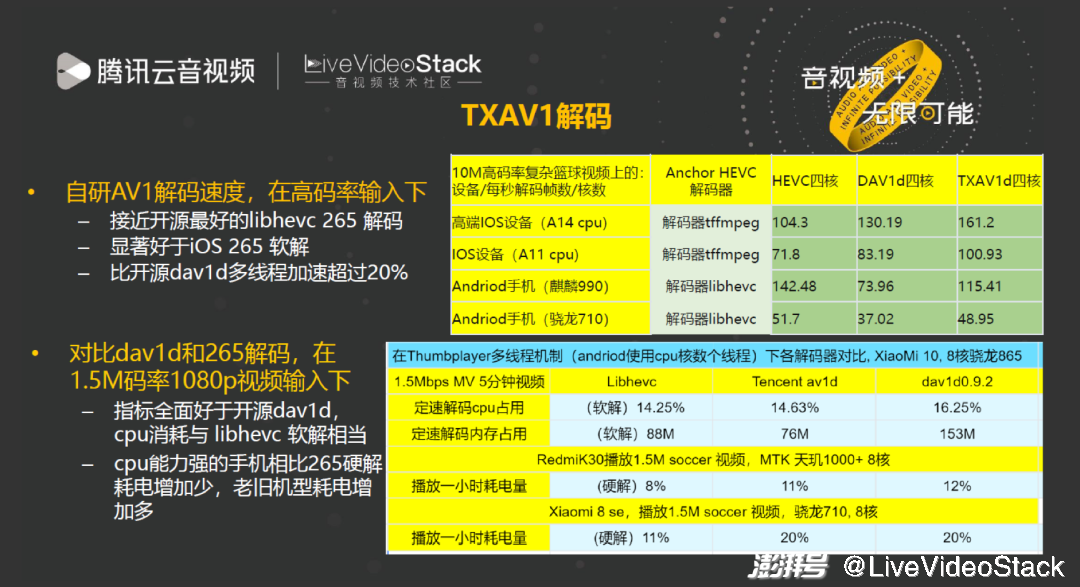
编码器只是一方面,最重要的还是生态,由于 AV1 解码芯片还不够普及,大概有 2-5% 硬解占比,那么为了推广 AV1,我们必须自研 AV1 的解码。
AV1 解码包括两部分,一是解码速度的比较,也就是绝对速度比较。对比目前开源最好的 libhevc,TXAV1 在性能较好的手机上或是在大部分手机上的解码已经接近于 libhevc,且显著优于 iOS265 软解。
在实际播放中不是 PK 绝对速度,而是 PK 在定速解码下的 CPU 占用和内存。于是对比了 TXAV1 和开源的 AV1 和 265 的定速解码,结果显示 TXAV1 的 CPU 占用率、内存、播放一小时耗电量均低于开源软件,在性能较差的机型耗电量高于硬解,但在性能稍好的机型上,TXV1 已经接近于硬解。
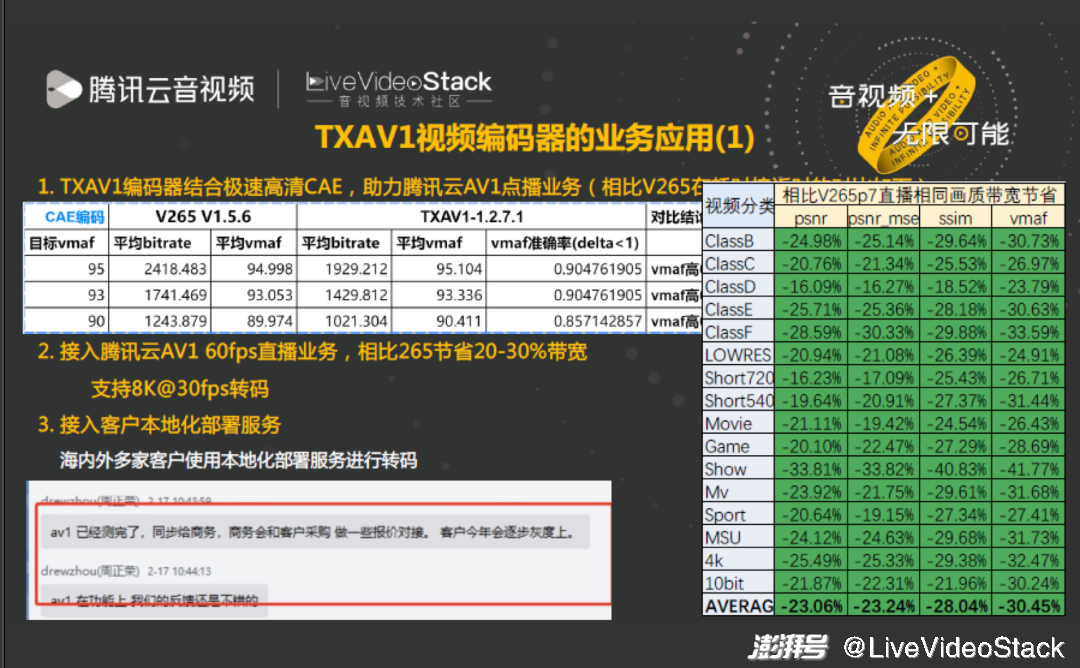
在 AV1 编解码器都研发得差不多的前提下,我们花费了更多的时间在编码器的落地上。
首先为点播业务做 CAE 适配,即内容自适应编码,目标是提升 vmaf 自测准确率,需要保证任一视频的 vmaf 准确率均较好才能够做到 CAE 能力。经过多轮优化,TXAV1 在 CAE 下的 vmaf [-1,1] 区间的预测准确率已经达到 85% 以上,同时相比自研 265 也能够节省 20% 带宽。
之后我们在直播上优化了许多加速算法,事实证明直播场景相同质量下,码率对比 265 能够节省 20-30% 带宽,并且已经开始在海内外客户进行私有化部署服务。

除了应用视频,AV1 还要应用于图片。在 Google 生态中,图片基本能够用浏览器播放,所以 AV1 的图片应用是非常重要的领域。今年腾讯云对 AVIF 的支持能力也进行了大量宣传,我们在后方主要做了编解码库上的支撑。
AVIF 的链路比较简单,输入一个视频后,转码为 AVIF 格式,然后大部分可以直接观看,小部分需要临时转码为 264 播放。
从测试对比看,TXAV1 对比 webp 有 30% 以上的带宽节省,而竞品 AV1 的带宽节省就差很多。对比 sharpp 也就是自研的 265 格式,带宽节省显著提升 20% 以上,耗时只有 1.4 倍。无论是转码的资源消耗还是带宽节省上都有所提升。此外,我们还优化了播放端的解码,测试结果显示 AVIF 的播放消耗其实相较 HEIF 还少一些,这其实归功于我们对包含接封装在内的解码的整个链路的优化。
其中 AVIF 编码的细节优化包括:在图片编码时优化内存申请、编码器的启动流程和配套格式;特别针对很多 4K、8K 的图像,因为 AV1 标准规定大于某个分辨率后只能使用 TILE 编码,所以基于 TILE 能力的支持超大图片的编码是必需的;目前 α 通道使用比较多,所以 4:0:0 的编码也是重点做的小技术。
2、新型预分析模型支撑的压缩率提升技术
介绍完项目落地应用,大家可能会感兴趣优化时使用的技术。接着就为大家介绍新型预分析模型支撑的压缩率提升技术。
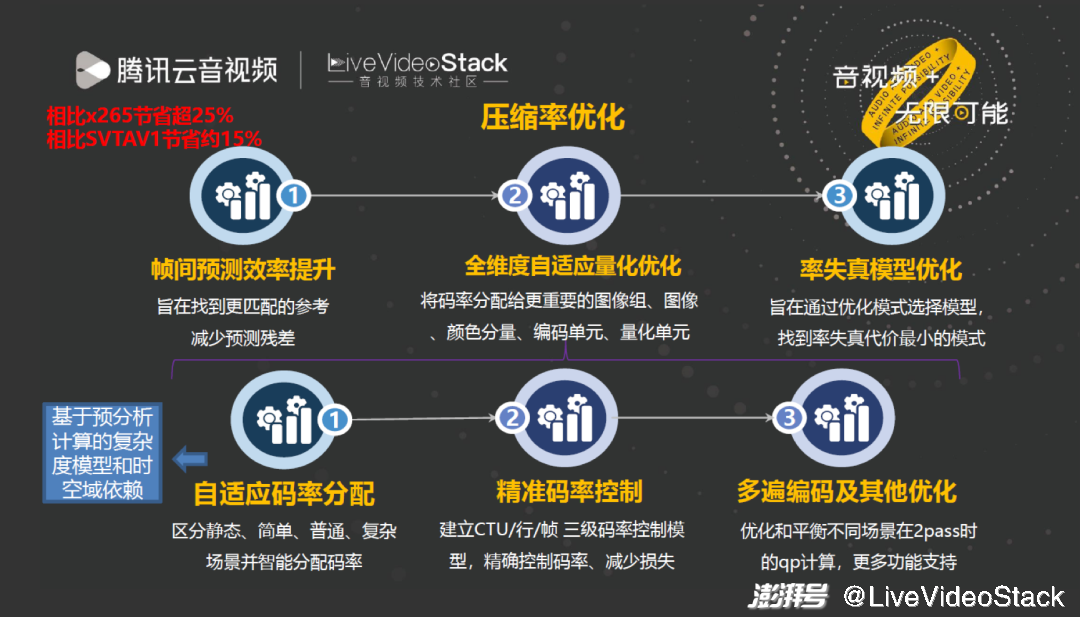
我们主要从三个方向提升压缩率。
第一,预测效率提升,把参考帧管理做到更好。第二,全维度自适应量化优化,包含帧级、GOP 级、块级的 QP 优化。第三,率失真模型优化。一个标准有许多模式,如何做到最优模式的选择,这就主要依靠率失真模型。
其中与其他编码器拉开差距最重要的是全维度自适应量化优化,即通过分析帧间的关系找出最优量化参数分配,实现整个 BD-Rate 最优。这里包含许多细节优化技术,但其实大部分算法都依赖预分析计算每块的复杂度和块与块之间的依赖关系。我会重点介绍在预分析过程中进行的优化。
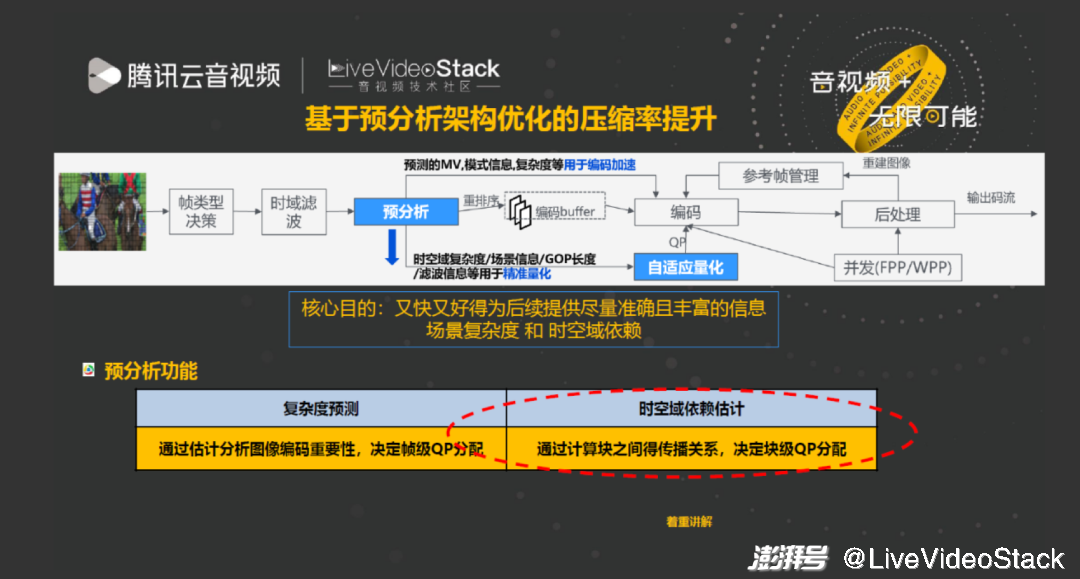
如图是在预分析框架下的整个编码器流程。近两年的一个重要变化是在 HM 和 VTM 中加入时域滤波,其实在 AV1 的编码器实现中做得更好。
视频输入后先进行帧类型决策,在帧类型决策基础上做时域滤波,对滤波后的图像做预分析。预分析是为了各级自适应量化服务的,重点产生帧间及块间的依赖关系,核心目的是又快又好地为后续图像提供更准确丰富的信息场景复杂度和时空域依赖。场景复杂度作用是通过估计图像编码重要性决定帧级 QP 分配,时空域依赖估计是通过计算块之间的传播关系以决定块级 QP 分配。本次重点介绍时空域依赖估计优化的方面。
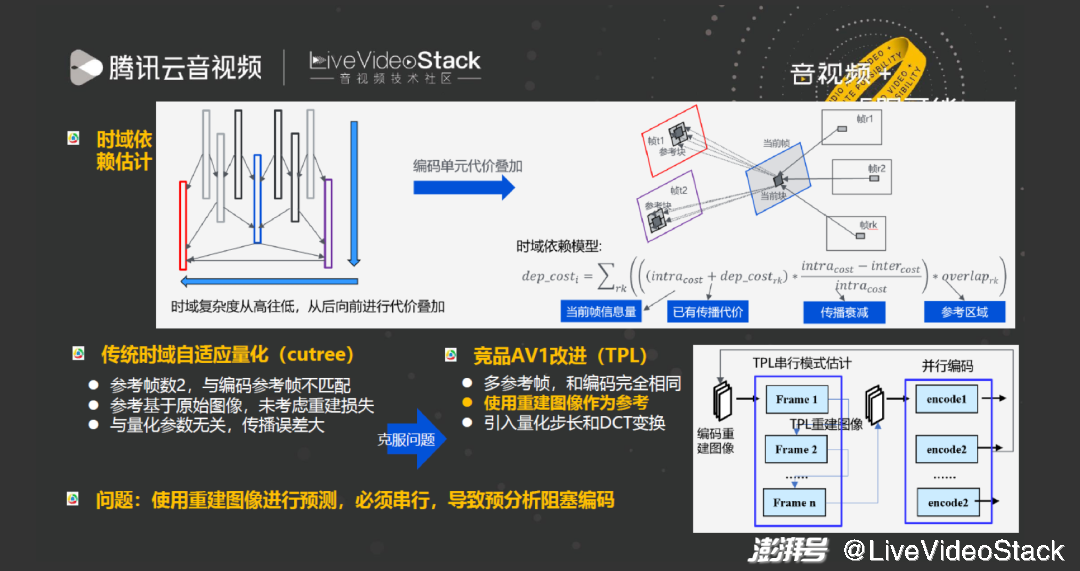
时域依赖即从高到低,从后向前的块级 cost 叠加过程,cost 叠加越大说明块的重要性越强,量化参数使用得越小。在传统的时域自适应量化中存在一些问题:第一,传统的 cutree 参考帧数永远是 2,与编码过程不匹配,导致依赖估计不准确;第二,参考基于原始图像,未考虑重建损失,与量化参数无关,传播误差大。而 AV1 编码器引入了 TPL 技术,分别从以下角度解决了问题:第一,使用多参考帧使其与编码完全相同;第二,引入量化步长和 DCT 变换,在 TPL 过程中生成重建图像并使用重建图像作为参考,避免 cutree 遇到的问题。但 TPL 过程也产生一个重要问题:帧间依赖估计都基于重建图像会使得预分析只能串行而不能并行,继而导致 TPL 过程成为整个编码器在快速档的瓶颈,严重阻塞 CPU 占用率,即使是慢速档也会阻塞一部分。
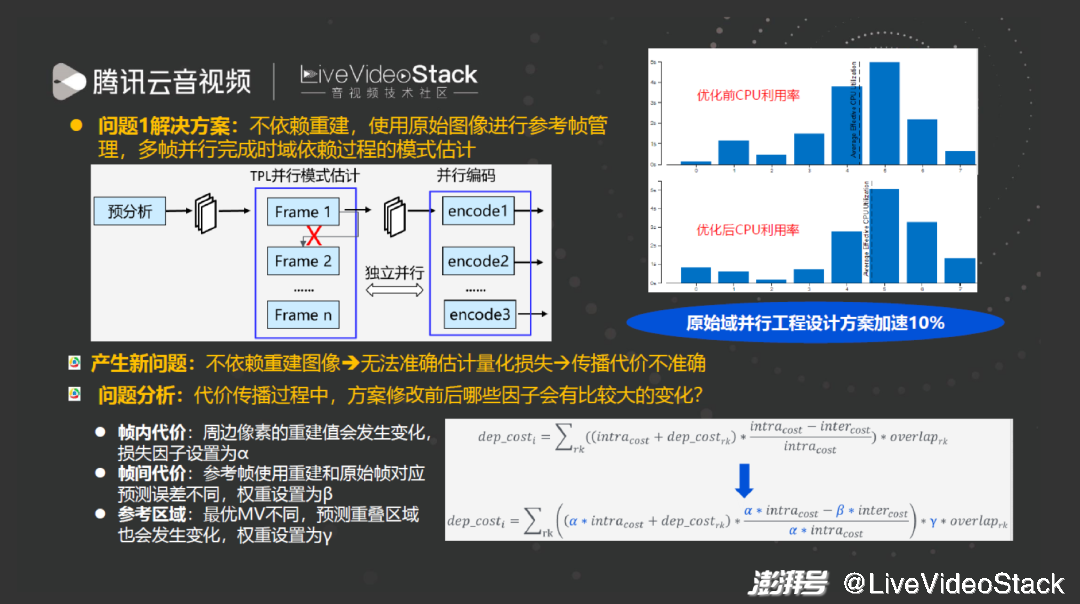
所以我们的主要优化思路是使 TPL 并行处理,不依赖重建而使用原始图像进行参考帧管理。优点是即使在最慢档也能提升 10% 速度,快速档甚至能够加速 50% 以上。缺点不重建后那么使用重建图像中带来的收益也随之消失,导致无法准确估计量化和损失,导致传播代价不准确。
方案修改前后会有哪些变化较大的因子呢?重建后的 intra cost、inter cost 会变差,overlap 面积也发生了变化 ——overlap 相当于从后往前传播时需要计算哪些部分已被参考。优化的手段最好能够使这三个参数的损耗成为可以模型化的系数,这就需要建立模型估计 α、β、γ 参数。
经过优化,TXAV1 所实现的三个参数纠偏模型可以做到:相比最原始的 TPL 方案在做到无串行依赖显著加速的同时,额外获得 2% 的压缩率提升。
3、TXAV1 的工程加速优化技术
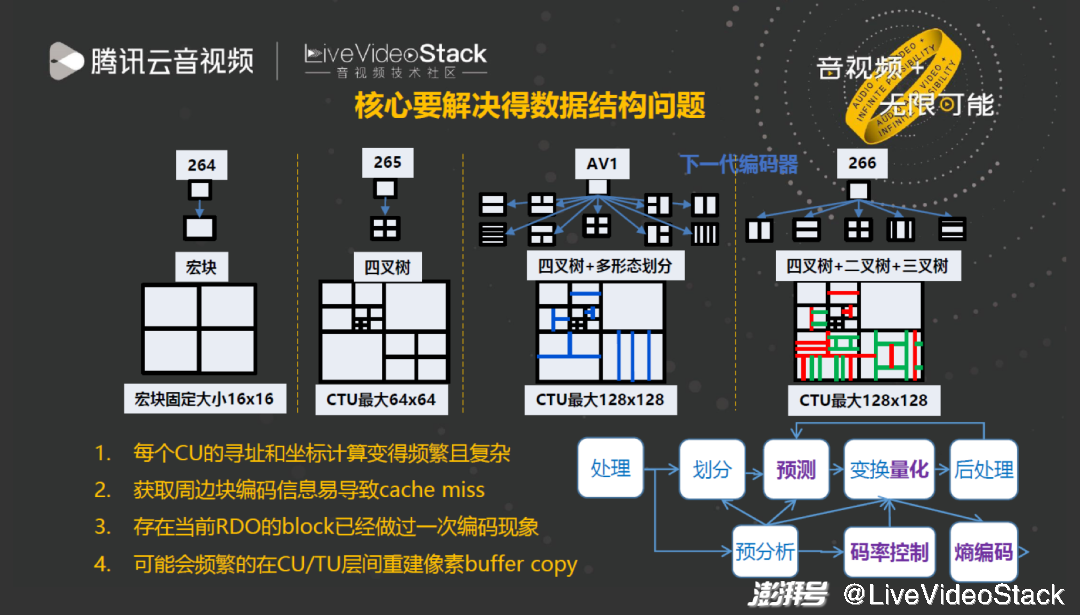
在工程加速方面,首先介绍 TXAV1 的数据结构优化。图中是标准迭代的过程,最明显的变化是划分越来越多,这会导致许多数据结构问题。因此在编码器设计过程中我们完全抛弃了 AOM 和 SVT 的数据结构设计,重新进行优化。
优化过程中包括四个重要问题:
第一,划分更多导致每个 CU 寻址和坐标计算变得频繁且复杂,每输入一个当前块就要重新计算块的坐标、相邻块可用性和 offset 以定位解码重建图像等信息,增加计算复杂度。
第二,由于周边块位置复杂,且每个 CTU 行为 128 像素,跨行的 memory 距离较大,导致获取周边块信息时发生 cache miss。
第三,划分块可能已经按照相同的信息编码一遍,因此需要避免重复编码。
第四,频繁重建 Block 的同时还要很频繁的进行 Buffer copy,过程的复杂度非常高。
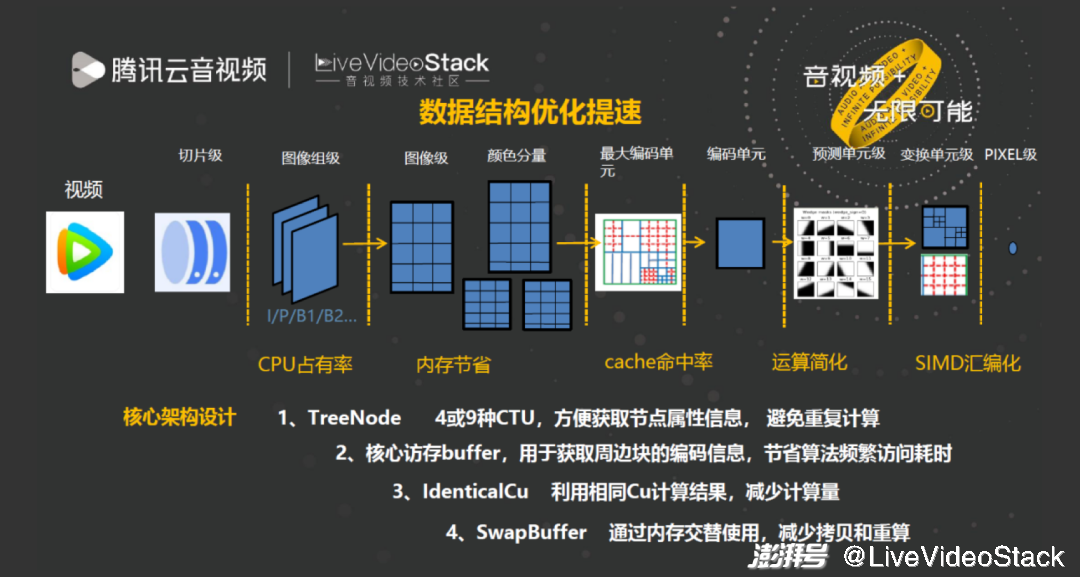
每个图像的 CTU 只有四类:左上角、右边、下边、右下角。首先我们在编码器启动阶段创建这四类 CTU 的寻址,直接获取每个节点属性信息,那么在编码 CTU 时只需要读取节点的宽高、可用性和 offset 信息即可,通过建立 Treenode 解决了频繁地址计算问题。第二是核心访存 buffer,目前的编码器为避免 cache miss 所采取的最好手段就是将其需要的所有信息储存在一个 local buffer,这样 local buffer 不仅储存单行块的信息,还储存相邻 CTU 信息。通过这个 buffer,每编码一个块就预先存入信息,那么下一个 buffer 使用信息时只需要读取周边块,节省了频繁访问造成的耗时。第三是 identical CU,和第一点相关,在创建节点时能够得知判断相同 ID 的 CU,当发现某一 CU 相同的 ID 已经做过时,当前的 CU 就不用重复做,而是直接 copy 编码结果信息,所以 identical CU 就是避免重复计算的过程。最后是 Swap buffer,本质是使用空间换时间的手段,比如大 CTU 和小 CTU 重建 buffer 的位置不同,那么在决策出 CU 划分之后,只需要缝合 buffer 就不会发生 copy 现象,也就是通过内存 swap buffer 操作减少 copy 和重算。
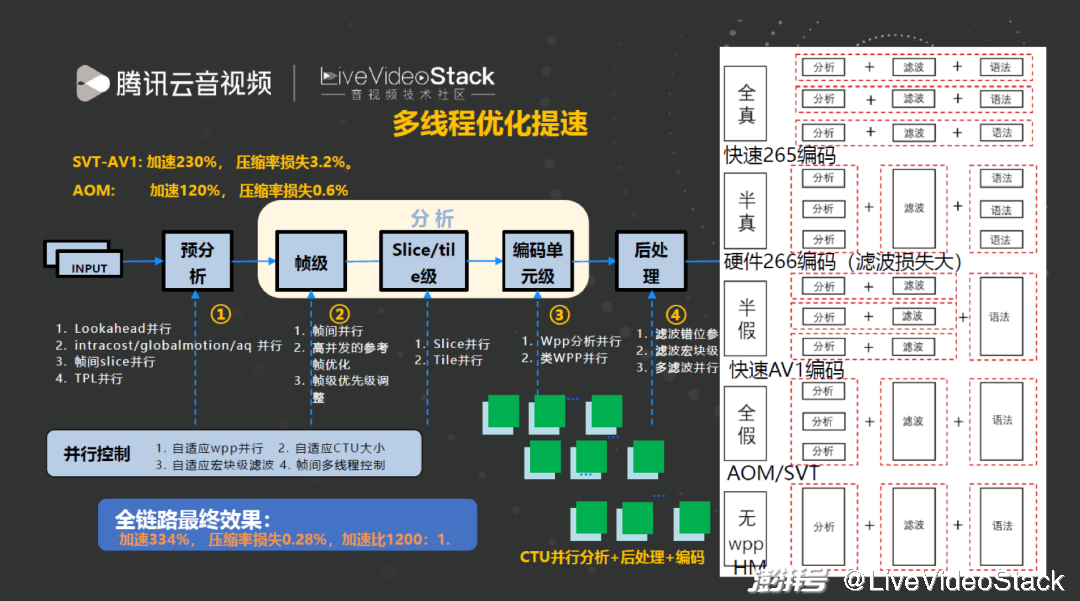
一个商业编码其的实现许多方面会用到编码器多线程,比如预分析过程、独立的编码单元分析过程及后处理过程。编码器的并行过程大体包括五种:预分析并行、帧间并行、WPP 并行、后处理并行及熵编码并行。
我们测试 SVT-AV1 后发现它加速 230%,压缩率损失 3.2%;AOM 加速 120%,压缩率损失 0.6%;而我们的编码器可以做到加速 334%,压缩率只损失 0.28%,这是并行算法发挥了作用。其中核心解决的是分析、后处理和编码三个模块的并行问题。
我们提出了 “无 wpp、全假 wpp、半假 wpp、半真 wpp、全真 wpp” 五个概念。
无 wpp: 类似 HM,在分析一个帧之后,再做帧的滤波及帧的编码。
全假 wpp: 只对分析内部并行,每一行一个线程,但滤波和编码过程没有流水的并行。
半假 wpp: 即除熵编码以外流水并行,我们编码器的快速档就使用这种过程:每分析一个 CTU 后会滤波左上角的块,这样行与行之间即为流水级的并行关系。编码不能并行的原因是 AV1 标准不支持 wpp 语法,因此只能串行。快速 AV1 编码器需要做到半假 wpp 工作。
半真 wpp: 对于硬件编码器特别是 266 编码器,它的滤波如果做流水线并行,损失会比较大,所以硬件编码器就可以做半真 wpp 并行。其中,语法为了减少输出码流延迟会并行,但滤波过程为了提升压缩率就不会并行,分析过程也可以并行。
全真 wpp: 传统快速档的 265 编码器都会使用,分析滤波和编码一起流水线进行。
AV1 编码器中包含了半假 wpp 和全假 wpp,有混合的自适应机制。
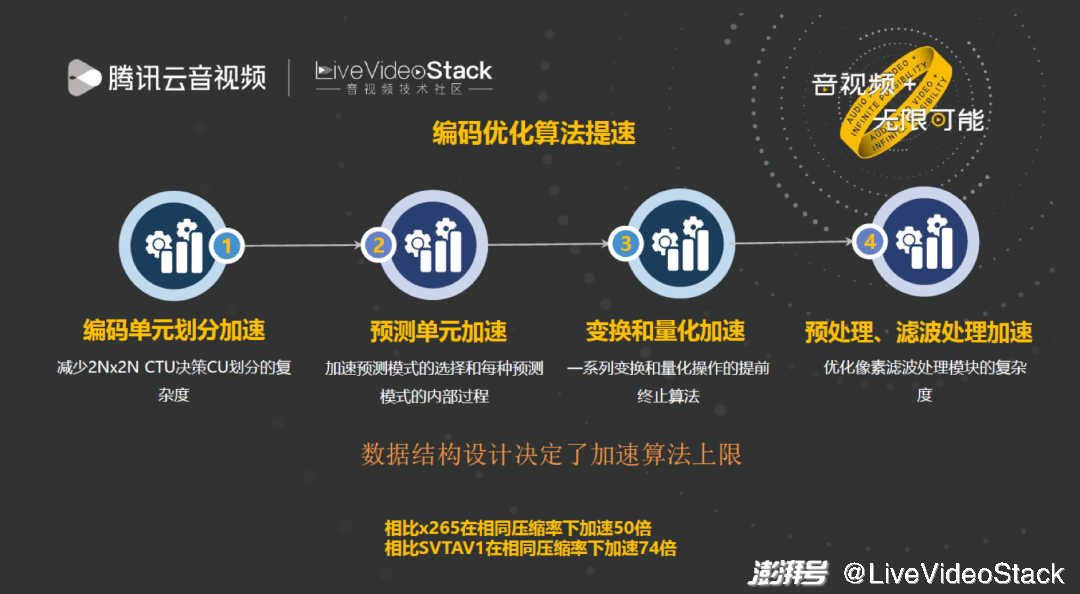
编码器加速有许多细节,最重要的一点是数据结构设计决定加速算法上限。AV1 编码器的开源软件不能方便获取相邻非最优 CU 划分类型的编码结果信息,而我们的编码器能够通过新建数据结构获得每个 CU 划分的编码结果,通过这种方式可以实现更多更好的快速算法。
4、总结
总结一下,TXAV1 编码器已经具备行业领先的 AV1 视频、图片编解码能力,拥有丰富的腾讯云 MPS 产品支持的落地案例,欢迎大家使用。
最后针对本次 TXAV1 编解码器的研发经验分享,可以概括如下几点:
第一点是前瞻性,研发方向决策极为关键,比如我们在 2020 年决定做 AV1 编码器就是非常关键的时间点。第二点是持续性,我了解到的许多编码器团队投入半年后没有成果就放弃了,这是不现实的,持续的投入非常重要,要么不投入用云方案要么就持续投入。第三点是内外兼修,我们的团队从来不只打比赛,在做一个产品的同时还会将编码器速度、码控和工程优化、CAE 等一起做起来,这样的编码器才更容易落地。
以上是本次的分享,谢谢。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

