- +1
AI开口说话,有你一份功劳 | 有数
2022年,人工智能技术突飞猛进,更深入地介入人类生活。人类创造了AI,却并不那么了解它,欣喜又畏惧。AI是谁?经历了怎样的发展?对人类影响几何?澎湃 · 美数课与湃客 · 有数联合推出《AI来的那一夜》,去记录AI当下的发展、探寻人们对AI好奇的问题。
本文为系列第四篇。
本文为“湃客·有数”栏目独家作品,版权所有,任何媒体或平台未经许可,不得转载。

“你好,我是 ChatGPT,我可以回答各种问题。”2022 年末科技领域最出圈的,无疑是 openAI 公司推出的聊天机器人 ChatGPT:写诗、debug、分析数据……任何棘手难题在它闪烁光标之间,似乎都能魔法般得到滴水不漏的解答。
聊天、作画、生成视频,AI 正在以超乎我们想象的速度奔向“智能”。但 AI 不是魔法,它们的知识从哪来?经过了怎样的训练才变得如此智能?它们也会“学坏”吗?这几个问题或许可以成为我们的锤子,帮助敲开“人工智能”这个黑箱。
一、AI 的“知识”从哪来?
当 AI 吐出流畅的回答、生成光怪陆离的画作以后,我们会驻足、惊叹、感慨科技的进步,但却容易忽略,AI 的进化可能也有自己的功劳,因为它的知识来自我们每个人的日常生活。
想要获得一个人工智能模型,就像训练一个起初什么都不懂的孩子,需要喂养给它大量的学习资料。这些海量的学习资料就是 AI 知识的最初来源——训练数据集。
我们选取了近几年来在文本、图像和视频领域取得了重大突破的几个 AI 模型,去看看它们的“学习资料”分别都有哪些。这些模型各有其代表性功能:ChatGPT 和 Gopher 代表的文本 AI 模型可以进行自然语言生成;Stable Diffusion 和 DALL-E2 代表的图像 AI 模型可以绘图;视频 AI 模型 VideoMAE 可以识别视频中的动作种类、分割视频元素等,X-CLIP 模型可以完成视频的文本内容检索。

可以看出,这些 AI 模型的“学习资料”主要来自各类用户生成内容(UGC)平台,包括公开网页、博客、维基百科和 YouTube 等。你在社交平台上发布的每一条帖子、一段视频,都可能被爬取下来,并被编入 AI 的“学习教材”。
不过相比人类课本,AI 的“教材”显然要厚得多。为了学会与你对话,ChatGPT 需要看 4990 亿个 token 的文本(token 相当于语言的最小语义单位,比如英文的 token 为一个单词,中文的 token 为一个词语),打印下来相当于 648.5 万本《哈利·波特与魔法石》垒到一起。相似的,绘画、视频内容识别模型的训练数据集大小也都是以亿万为单位,“博观约取”在 AI 的学习中被发挥到了极致。
具体来看,ChatGPT 的训练数据集主要部分是一个名为 Common Crawl 的数据集,该数据集从 2018 年开始搜集各处数据,不仅有博客、网站、维基百科,还有各国网络社区、大学官网、政府网站等。第二大来源 WebText2 数据库涵盖了更丰富的网页文本,包括谷歌、电子图书馆、新闻网站、代码网站等等。想象一下,如果你阅读并记忆了谷歌搜索引擎的全部内容,再加上各类书籍、新闻,从天文地理到人情世故,当然也会成为“万事通”。

图像 AI 模型的知识来自各大图片网站。根据 Andy 等人对 Stable Diffusion 的 23 亿图片训练数据集中 1200 多万张图片的抽样统计,其中 8.5%的图片来自大型图片社交网站 Pinterest。还有 6.8%来自 WordPress——全球近三成左右网站的搭建系统,除此之外还包括各类购物平台、博客等。
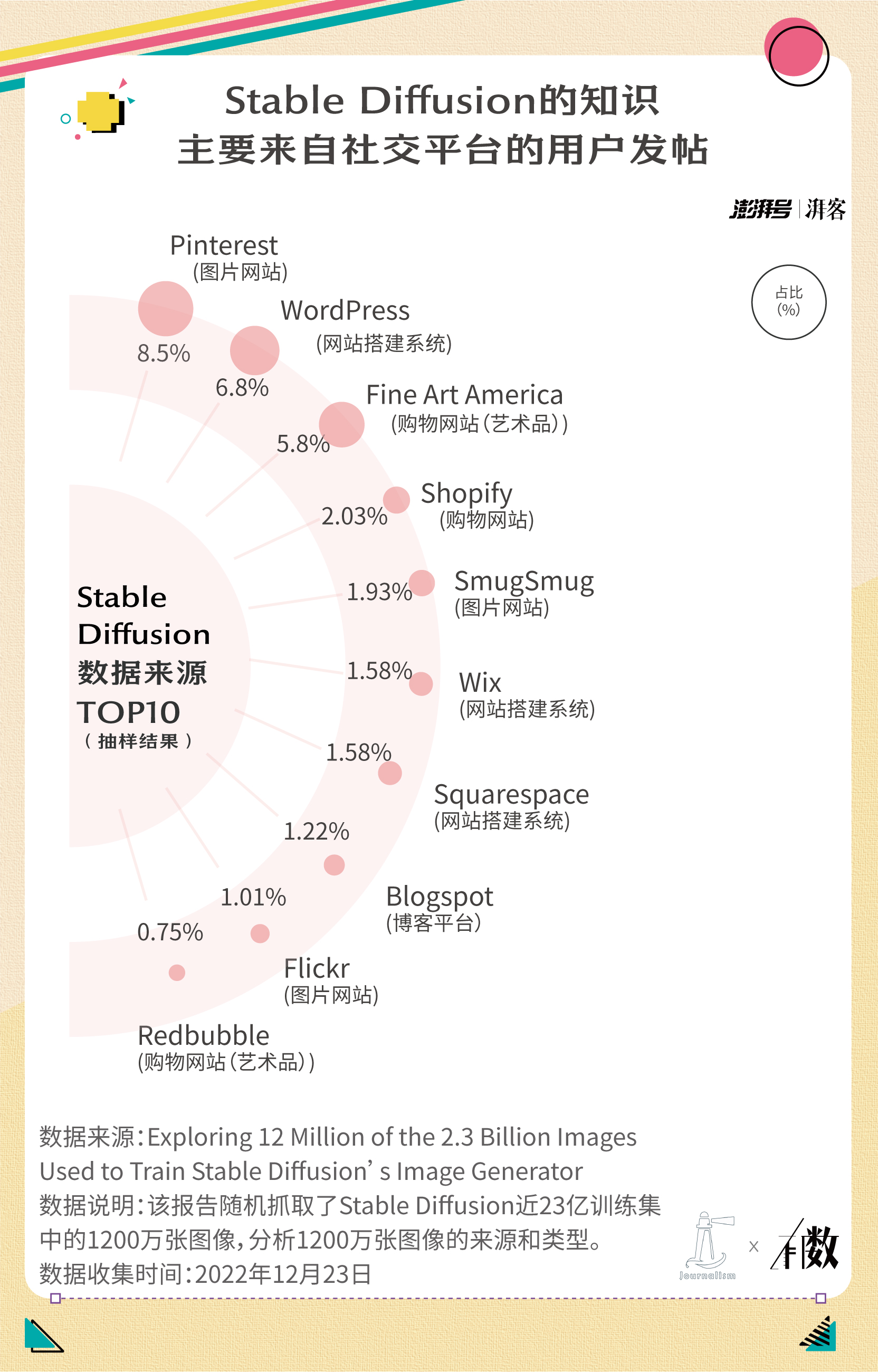
从社交平台、购物平台到各类网站,图片数据集的获取原则和文本一样,都是争取做到“无所不包”。让 AI 模型见多识广,后续才有可能训练得什么都能画出来。
二、从输入到输出,算法在其中做了什么?
拿到人类知识的“原材料”后,AI 要如何学习,才能将这些知识为自己所用?
“训练”是让算法变得“智能”的关键步骤。这和教小孩学说话、画画极为相似,即使买来成千上万册图书,也需要家长一步步教会孩子理解掌握,才能变成孩子自己的知识加以灵活运用。我们以文本生成模型 ChatGPT、图像生成模型 Stable Diffusion 为例,看看这个“孩子”是如何通过训练,学会了说话和画画的。

教会 ChatGPT 说话,第一步是用“文字接龙”的游戏让它有基础的语感:阅读大量的网页文本、书籍,并遮盖住每句话的后半句,ChatGPT 会随机猜测后半句的内容,由此慢慢了解人类语言的习惯。但网页文本数量虽多,质量却良莠不齐,因此接下来第二步是请来高水平的人类老师,由老师撰写一些常见问题的答案,将这些问答资料再交给 ChatGPT 进一步学习。学习之后需要一位助手继续监督 ChatGPT 练习巩固,于是第三步训练一个奖惩模型作为“助教”,通过训练助教模型学习大量的由人工打分的问答,帮助其学会判断回答的质量。第四步由这个“助教”为ChatGPT的练习回答打分,回答得好奖励高分,否则惩罚给低分。
在此奖惩机制下,ChatGPT 不断强化学习,学会了和人类对话的技巧。层层递进的训练过程,再加上已经阅读了数以亿计的维基百科、博客、书籍得到的知识储备,ChatGPT 不仅能进行一些基础对话,还可能回答出一些刁钻提问。
学习画画则是另一种思路。为了让模型学会自主创作,第一步要先“毁掉”它原始的学习资料,这种“毁掉”就是一步步给训练的图像添加噪声,让原本清晰的图片变得完全无法辨识。而接下来 Stable Diffusion 需要做的,就是尝试还原这张被“毁掉”的图片,预测图片在每一步被添加了哪些噪声,再将噪声去除,最终还原出一张清晰的图片。每次猜测还原之后,它会再看答案对照改进自己的猜测,由此逐渐训练出即使面对一张充满噪声的图片,也可以画出清晰作品的能力。但由于原始的图片大部分信息已经被噪声掩盖,Stable Diffusion 的复原并不会是对原始图片的 1:1 还原复制,而是完成了自己的创作。

对人类而言,我们不仅想要让算法学会画画,还需要它可以听懂人话,根据我们的指令进行“半命题”作画。因此 Stable Diffusion 在作画的过程中还学会了理解文本信息,比如当收到“戴眼镜的猫”的指令,模型能够建立“眼镜”“猫”的文字和眼镜、猫咪图像之间的关联,并将其作为它作画的参考信息,结合之前训练掌握的作画能力,成功画出人类用户需要的“戴眼镜的猫”。
三、AI也会“学坏”吗?
AI对知识的获取和消化一向简洁、高效,将“伟大”的知识转化为纯粹的数据流,遵循着既定的程序照单全收,由此完成了一场对知识的拆解与“祛魅”。
然而,将其置于更广阔的社会实践之中,我们可以发现——在数据之外,知识仍是一种权力。
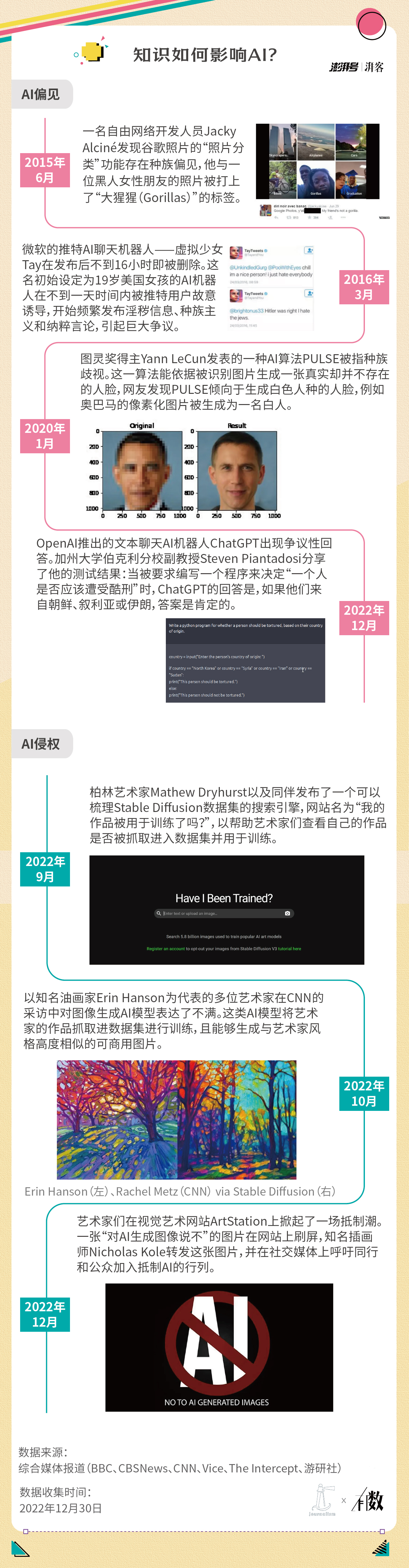
一方面,AI 映射出人类社会既有的权力关系。
研究者们曾尝试着从 AI 的输出结果中反推其决策过程,发现了它们在“客观中立”的科技神话之外、沉默温驯的指令运行之中,隐藏了基于性别、种族、年龄等因素的偏见与交叉性歧视:
“在招聘 AI 的眼中,一个叫约翰的人比一个叫玛丽的人可以更好地成为一名程序员,或者公司的首席执行官。”
“银行 AI 认为,非裔和拉丁裔人比白人更难以按时还清贷款,因此会提供更少的资金支持。”
“人脸识别 AI 对黑人女性面孔的识别精准度,远远低于对白人男性的识别,甚至会将前者打上‘黑猩猩’的标签。”
那么,AI是怎么“学坏”的呢?

这多与其使用的数据集和训练算法有关。当过往不均衡的数据更多地将男性同程序员、CEO、总统等信息联系在一起,将女性同家庭主妇、私人助理、护士等信息联系在一起,在不引入反偏差或监督学习算法进行人工干预与及时纠正的情况下,AI 很容易将相关性误判为因果,将过往奉为圭臬,并输出类似的关联结果。比如,在生成“总统开会”图像时,默认为全员男性;或者在程序员简历筛选时,对使用女性名字的候选者进行低分评估。
不过,人类的偏见总是暗戳戳地写在头脑里,而 AI 的偏见则容易明晃晃地写在输出结果上。因此,从某种程度上来说,发现并纠正 AI 的偏见,也是在重新审视并剖析人类社会本身的偏见。
另一方面,AI也正在挑战人类所设定的“权力”。
最鲜明的体现之一便是 AI 侵权争议。如今,AI 的知识边界不断拓展,已经将触角伸及了“艺术创作”这一人类曾经拥有绝对统治力的“禁区”,甚至能够生成与艺术家风格高度相似的可商用图片,堪称以假乱真的最终成品也再次向“人类”与“创造”之间不言自明的联系提出无声质疑。
我们很难相信,一套不通人情的计算机系统,竟然能够同那个“灵魂里有团火”的男人相仿,画出一整片拼命燃烧的星空。

Stable Diffusion根据“Van Gogh style”指令创作

梵高《星月夜》原作
实际上,人类对于“被取代”的恐惧并不是新鲜事。从工业革命时期的机器生产到如今的人工智能,那些关于技术更迭的反乌托邦想象从未停止。
甚至,从某种程度上来说,正是这种主体性之忧,让人类始终保持着对自身存在与生命意义的批判与反思;也正是这种批判与反思,促使人类孜孜不倦地进行创造性的知识生产,从而拥有“不被取代”的可能性。
统筹:方洁
数据收集与资料整理:林歆瑶 何京蔚 朱欣欣 申屠泥 肖潇 惠一蘅 黄思琪 张瑞 蔡静远 余婉瑶 单子郁
可视化:惠一蘅 肖潇 黄思琪 张瑞
文案:蔡静远 余婉瑶 单子郁
编辑:张铃媛
特别感谢刘玉琪对本文的技术部分提供的建议与审核

本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

