- +1
AI音乐家:给我一个prompt,帮你实现编曲自由
原创 学术头条 学术头条

今天,我们听点音乐。
这段音乐是由 MusicLM 根据下方的提示自动生成。
电子游戏中播放的电子歌曲(0:00-0:15)
在河边播放的冥想歌曲(0:15-0:30)
火(0:30-0:45)
烟花(0:45-0:60)
MusicLM 是谷歌于 2023 年 1 月推出的一种 AI 音乐生成器,能够基于文本描述生成高保真的音乐。在给出提示后,MusicLM 将音乐生成过程视为分层的序列到序列建模任务,它以 24 kHz 的频率生成音乐,并在几分钟内保持一致。
AI 音乐家的诞生
AI 生成音乐的历史悠久,早在上世纪 90 年代,音乐学教授 David Koepp 写出了第一个程序——EMI,意思是 “音乐智能的实验”,能够谱出协奏曲、合唱曲、交响乐和歌剧。尽管写这个程序花费了七年时间,但该程序一经推出,便在短短一天就谱出了 5000 首巴赫风格的赞美诗。
2016 年,三位音乐家企业家创立 AIVA technology,利用 AI 创作音乐。AIVA 能够为电影、广告、游戏、预告片和电视节目创作情感配乐。AIVA 通过读取由历史上最著名的作曲家创作的大型音乐数据库,并在乐谱中寻找模式和规则,来了解音乐的风格,基于强化学习,在忠实于原始主题的同时,根据用户指定的偏好在每次迭代中逐渐偏离原始主题,从而生成个性化的音乐。
最近的 RIFFUSION 使用 AI 图像生成引擎 Stable Diffusion 将文本提示转换为频谱图,然后再转换为音乐。具体来说,通过微调 Stable Diffusion 以生成频谱图图像,如给出提示 “带有爵士乐萨克斯管独奏的放克低音线”,再将生成的频谱图转换为音频剪辑。音频处理发生在模型的下游,它可以通过改变种子而产生无限的提示变化。

另外,OpenAI 在 2020 年发布了一款名为 “Jukebox” 的 AI 音乐生成器。通过输入流派、艺术家和歌词,Jukebox 能够输出从头开始制作的新音乐样本。

从“文生音频”到“文生音乐”
目前,各种生成模型的最先进技术主要由基于 Transformer 的自回归模型或基于 U-Net 的扩散模型所主导。尽管生成具有长期一致性的高质量音频是一个挑战,但最近有一系列方法解决了这个问题。例如,Jukebox 提出了一种不同时间分辨率的 VQ-VAE 的层次结构,以实现高时间一致性,但生成的音乐呈现出明显的假象。
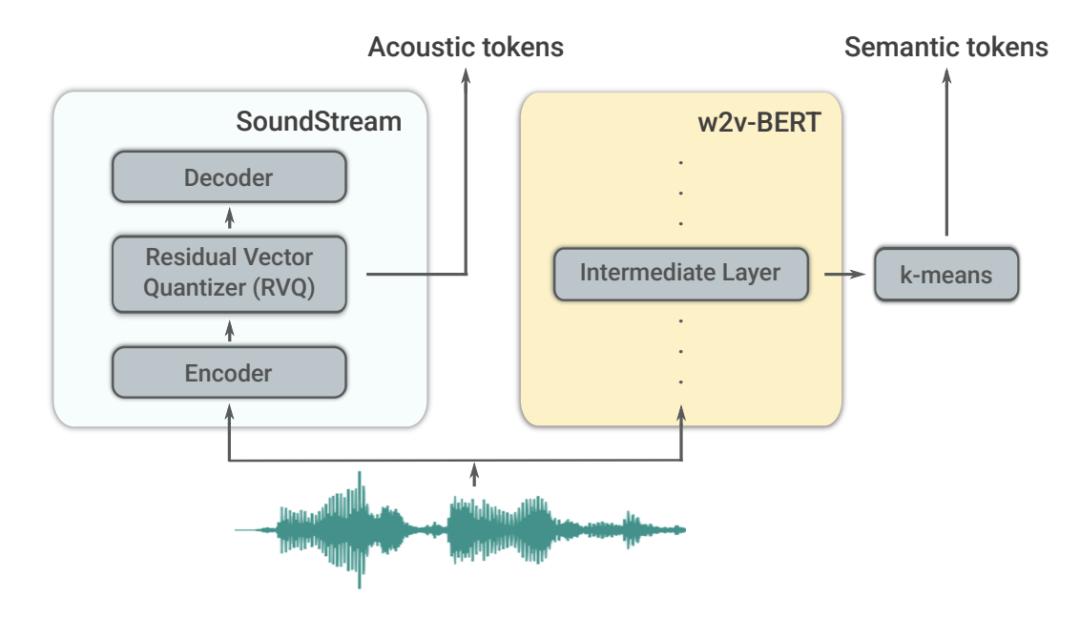
另一方面,PerceiverAR 提议对 SoundStream 标记的序列进行逐步建模,实现高质量的音频,但压缩了长期的时间一致性。受这些方法的启发,AudioLM 通过依赖分层标记化和生成方案来解决一致性和高质量合成之间的权衡。
具体来说,该方法区分了两种标记类型:(1)语义标记,允许对长期结构进行建模,这些标记是从对音频数据进行训练的模型中提取的,目的是对语言进行建模;(2)声学标记,由一个神经音频编解码器提供,用于捕捉精细的声学细节。这使得 AudioLM 能够生成连贯的、高质量的语音以及延续的钢琴音乐,而不需要依赖转录本或符号化的音乐表示。
一些尝试从文本描述中生成音频的工作逐渐涌现。DiffSound 使用 CLIP 作为文本编码器,并应用扩散模型来预测基于文本嵌入的目标音频的量化旋律谱特征。AudioGen 使用 T5 编码器嵌入文本,并使用自回归变换器解码器预测由 EnCodec 产生的目标音频代码。这两种方法都依赖于适量的配对训练数据。
基于文本的音频合成的前身是基于文本的图像生成模型,由于架构的改进和大量高质量的配对训练数据的可用性,这些模型在质量上取得了显著的进步。文生图的方法已被扩展到从文本提示生成视频。例如,DALL-E 2 依靠 CLIP 进行文本编码的方式同样能为音乐和文本的联合嵌入模型提供参考。
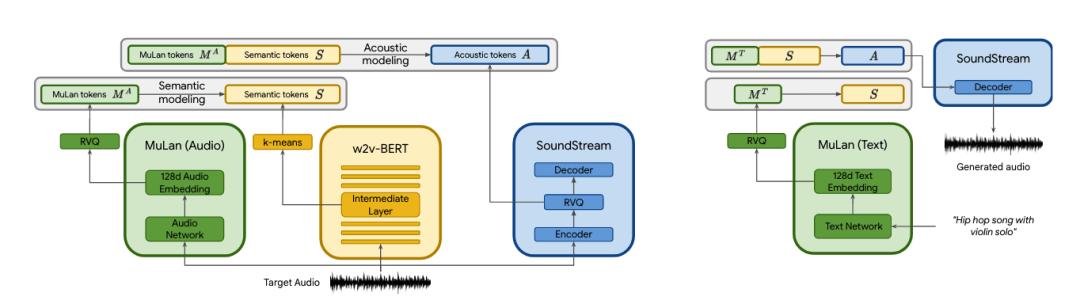
作为一种音乐-文本联合嵌入模型,MuLan 由两个嵌入塔组成,每个模态一个。MuLan 是在成对的音乐片段及其相应的文本注释上训练的。重要的是,MuLan 对其训练数据质量的要求非常弱,即使在音乐-文本对只有微弱关联的情况下也能学习跨模式的对应关系。
好听吗?和人类音乐家相比
以 Jukebox 为例,这些系统并没有像生成文本和图像的系统那样受欢迎。尽管它们生成的音乐在质量、连贯性、音频样本长度以及根据艺术家、流派和歌词进行调节的能力方面向前迈进了一步,但输出的音乐并没有那么令人印象深刻——大多数都是低保真、简单的,并且缺乏传统的歌曲结构,比如重复的合唱,仍旧与人类创作的音乐之间存在显著差距。
但是,MusicLM 将 “文生音乐” 向前推进了一大步。实验表明,MusicLM 在音频质量和对文本描述的遵守方面都优于以前的系统。MusicLM 主要分为两个部分:首先,它接受一系列音频标记,并将它们映射到字幕中的语义标记进行训练。第二部分接收用户字幕和/或输入音频,并生成声学标记。这些都让其保真效果比其它系统好,该系统依赖于早期的人工智能模型 AudioLM 以及 SoundStream 和 MuLan 等其他组件。
一方面,MusicLM 模型能够根据文本自动生成符合场景的音乐。模型能够生成 10 秒乐器片段(如大提琴或沙球)、某些音乐流派的 8 秒片段,初学者钢琴演奏者与高级钢琴演奏者的声音,以及由一两个词(如 “旋律技术”)生成的 5 分钟长的片段。一个特别有趣的例子是,对一幅画进行描述并以此生成音乐。
Prompt:Jacques-Louis David 的《拿破仑穿越阿尔卑斯山》——这幅作品展示了拿破仑和他的军队于 1800 年 5 月通过大圣伯纳德山口穿越阿尔卑斯山的真实穿越的强烈理想化景象。

另一方面,MusicLM 还可以建立在现有的旋律之上,即无论是哼唱、演唱、吹口哨,还是在乐器上演奏,MusicLM 都可以继续创建音乐,保障音乐不失真,带来各种创造性的可能。此外,MusicLM 还具有故事模式,能够将几种描述拼接在一起,创造出唤起特定情感的配乐。
当然,MusicLM 目前还并不是一个成熟的模型,就以模拟人声为例,虽然它可以正确处理声音的音调,但是质感还存在问题。此外,很多自动生成的 “歌词” 有些含糊不清,就像是根本无人能听懂的外星语。
不过,谷歌的研究人员也提出了一些改进方向:“未来的工作可能会集中在歌词生成,同时改善提示文本准确性和提高生成质量。复杂歌曲结构的建模,如前奏、主歌和副歌也将是重点发展方向。”
文生音乐,同样令人担忧
MusicLM 基于文本描述生成高质量的音乐,进一步扩展了一套工具,使人类能够完成创造性的音乐任务。然而,值得注意的是,谷歌并没有对外发布 MusicLM,只是公开了一个包含大约 5500 个音乐文本对的数据集,这可能有助于训练和评估其他音乐 AI。
谷歌指出,模型及其处理的用例存在一些风险。例如,该系统生成的音乐中约有 1% 是直接从人类音乐人那里复刻得来;生成的样本将反映训练数据中存在的偏差,这就提出了对训练数据中代表性不足的文化进行音乐生成的一些问题,同时也引发了对文化挪用的担忧。因此,未来需要更多的工作来解决这些风险。
但可以预见的是,AI 研究人员将继续改进音乐生成技术,直到每个人都能通过描述创造出任何风格的工作室质量的音乐。尽管没有人能准确预测这个目标何时能实现,或者它将如何影响音乐产业,但这一天一定会到来。
参考链接:
https://www.riffusion.com/about
https://www.theverge.com/2023/1/28/23574573/google-musiclm-text-to-music-ai
https://www.audiocipher.com/post/ai-daw
https://openai.com/research/jukebox
https://d3.harvard.edu/platform-digit/submission/aiva-technology-composing-music-using-ai/
https://www.nytimes.com/1997/11/11/science/undiscovered-bach-no-a-computer-wrote-it.html
原标题:《AI音乐家:给我一个prompt,帮你实现编曲自由》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

