- +1
羊驼家族大模型集体进化,32k上下文追平GPT-4,田渊栋团队出品
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
开源羊驼大模型LLaMA上下文追平GPT-4,只需要一个简单改动!
Meta AI这篇刚刚提交的论文表示,LLaMA上下文窗口从2k扩展到32k后只需要小于1000步的微调。
与预训练相比,成本忽略不计。
 扩展上下文窗口,就意味着AI的“工作记忆”容量增加,具体来说可以:
扩展上下文窗口,就意味着AI的“工作记忆”容量增加,具体来说可以:支持更多轮对话,减少遗忘现象,如更稳定的角色扮演
输入更多资料完成更复杂的任务,如一次处理更长文档或多篇文档
更重要的意义在于,所有基于LLaMA的羊驼大模型家族岂不是可以低成本采用此方法,集体进化?
羊驼是目前综合能力最强的开源基础模型,已经衍生出不少完全开源可商用大模型和垂直行业模型。
 论文通信作者田渊栋也激动地在朋友圈分享这一新进展。
论文通信作者田渊栋也激动地在朋友圈分享这一新进展。 基于RoPE的大模型都能用
基于RoPE的大模型都能用新方法名为位置插值(Position Interpolation),对使用RoPE(旋转位置编码)的大模型都适用。
RoPE早在2021年就由追一科技团队提出,到现在已成为大模型最常见的位置编码方法之一。
 但在此架构下直接使用外推法(Extrapolation)扩展上下文窗口,会完全破坏自注意力机制。
但在此架构下直接使用外推法(Extrapolation)扩展上下文窗口,会完全破坏自注意力机制。具体来说,超出预训练上下文长度之外的部分,会使模型困惑度(perplexity)飙升至和未经训练的模型相当。
新方法改成线性地缩小位置索引,扩展前后位置索引和相对距离的范围对齐。
 用图表现二者的区别更加直观。
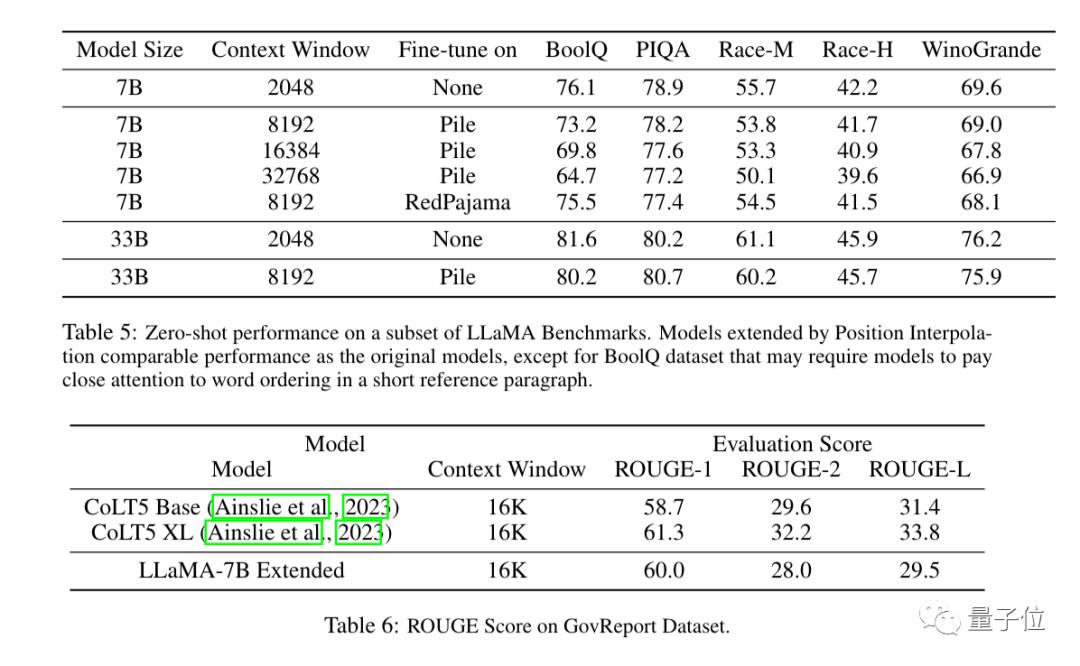
用图表现二者的区别更加直观。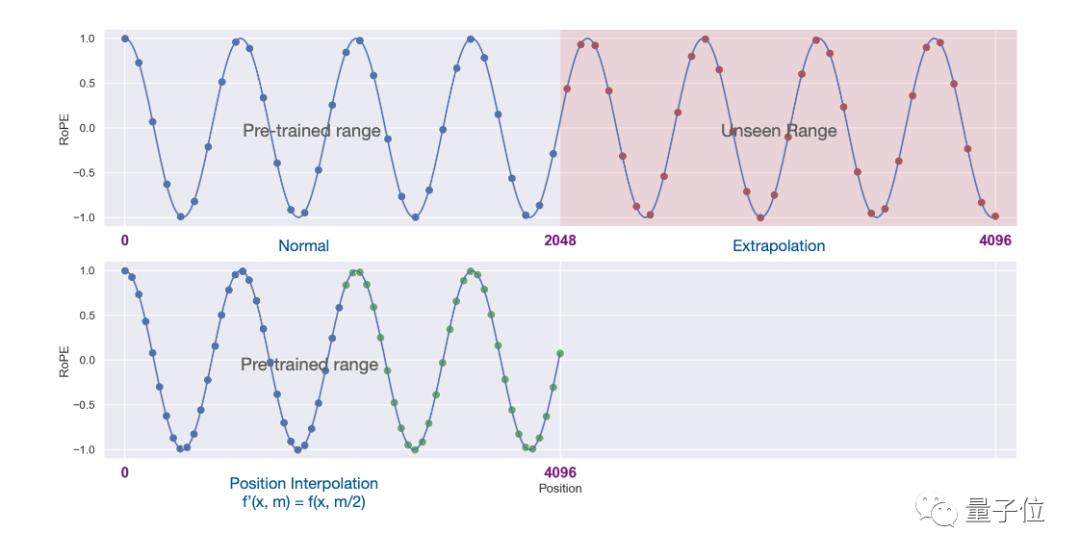 实验结果显示,新方法对从7B到65B的LLaMA大模型都有效。
实验结果显示,新方法对从7B到65B的LLaMA大模型都有效。在长序列语言建模(Long Sequence Language Modeling)、密钥检索(Passkey Retrieval)、长文档摘要(Long Document Summarization)中性能都没有明显下降。
 除了实验之外,论文附录中也给出了对新方法的详细证明。
除了实验之外,论文附录中也给出了对新方法的详细证明。 Three More Thing
Three More Thing上下文窗口曾经是开源大模型与商业大模型之间一个重要差距。
比如OpenAI的GPT-3.5最高支持16k,GPT-4支持32k,AnthropicAI的Claude更是高达100k。
与此同时许多开源大模型如LLaMA和Falcon还停留在2k。
现在,Meta AI的新成果直接把这一差距抹平了。
扩展上下文窗口也是近期大模型研究的焦点之一,除了位置插值方法之外,还有很多尝试引起业界关注。
1、开发者kaiokendev在一篇技术博客中探索了一种将LLaMa上下文窗口扩展到8k的方法。
 2、数据安全公司Soveren机器学习负责人Galina Alperovich在一篇文章中总结了扩展上下文窗口的6个技巧。
2、数据安全公司Soveren机器学习负责人Galina Alperovich在一篇文章中总结了扩展上下文窗口的6个技巧。 3、来自Mila、IBM等机构的团队还在一篇论文中尝试了在Transformer中完全去掉位置编码的方法。
3、来自Mila、IBM等机构的团队还在一篇论文中尝试了在Transformer中完全去掉位置编码的方法。 有需要的小伙伴可以点击下方链接查看~
有需要的小伙伴可以点击下方链接查看~Meta论文:
https://arxiv.org/abs/2306.15595
Extending Context is Hard…but not Impossible
https://kaiokendev.github.io/context
The Secret Sauce behind 100K context window in LLMs
https://blog.gopenai.com/how-to-speed-up-llms-and-use-100k-context-window-all-tricks-in-one-place-ffd40577b4c
无位置编码论文
https://arxiv.org/abs/2305.19466
— 完 —
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

