- +1
给大语言模型“开个眼”,看图说话性能超CLIP,斯坦福等新方法无需多模态预训练
西风 发自 凹非寺
量子位 | 公众号 QbitAI
不靠多模态数据,大语言模型也能看得懂图?!
话不多说,直接看效果。
就拿曾测试过BLIP-2的长城照片来说,它不仅可以识别出是长城,还能讲两句历史:

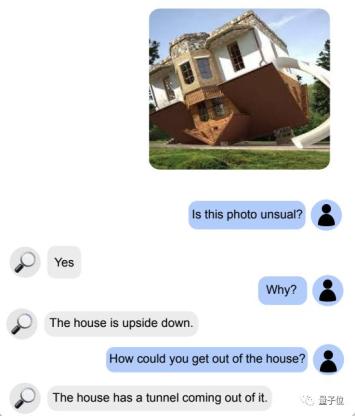
再来一个奇形怪状的房子,它也能准确识别出不正常,并且知道该如何进出:
故意把“Red”弄成紫色,“Green”涂成红色也干扰不了它:

这就是最近研究人员提出的一种新模块化框架——LENS��(Language-Enhanced Neural System)的识别效果。
重要的是,不需要额外在多模态数据集上进行预训练,只用现成的大语言模型就能完成目标识别和视觉推理任务。
既省钱又省力!
研究人员表示:
这种方法在零样本的情况下效果可与多模态大模型Kosmos,以及可开箱即用的Flamingo等端到端联合预训练模型相匹敌,性能甚至可能会更好。
网友看到这不淡定了:
激动啊家人们!用来训练大模型的资源现在也可以被用于解决不同领域的问题了。��
还有网友表示:
想看哪个模块最能提高视觉推理能力,这很有趣!
怎么做到的?
现有的LLM虽然在自然语言理解和推理方面表现出色,但都不能直接解决从视觉输入进行推理的任务。
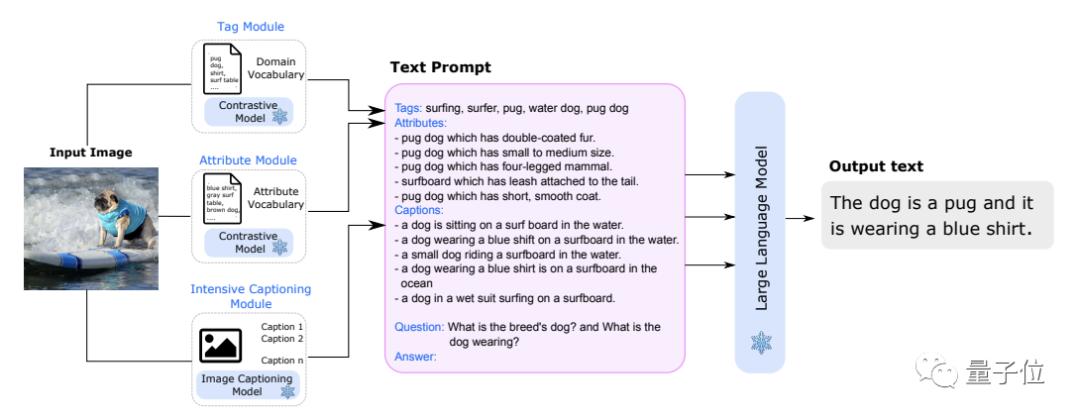
这项由Contextual AI和斯坦福大学研究人员共同完成的工作,利用LLM作为冻结的语言模型(不再进行训练或微调),并为它们提供从“视觉模块”获取的文本信息,使其能够执行目标识别和V&L(视觉和语言)任务。

简单来说,当你问关于一张图片的内容时,该方法会先操作三个独立的“视觉模块”,Tag Module(提取标签信息)、Attribute Module(提取属性信息)、Intensive Captioning Module(生成详细的图像描述),以此提取出关于图像的文本信息。
然后直接将这些信息输入到推理模块(Reasoning Module)中,也就是冻结的LLM,对问题进行响应回答。
这样一来,通过集成LENS可以得到一个跨领域自动适用的模型,无需额外的预训练。并且能够充分利用计算机视觉和自然语言处理领域的最新进展,最大限度地发挥这些领域的优势。
在此前,已经有研究提出了几种利用LLM解决视觉任务的方法。
其中一种方法是先训练一个视觉编码器,然后将每个图像表示为连续嵌入序列,让LLM能够理解。
另一种方法是使用已经训练对比的冻结视觉编码器,同时引入新的层到冻结的LLM中,并从头开始训练这些层。
第三种方法是同时使用冻结的视觉编码器(对比预训练)和冻结的LLM,通过训练轻量级transformer将它们对齐。
视觉编码器是指用于将视觉输入(如图像或视频)转换为表示向量的模型或组件。它能够将高维的视觉数据转换为低维的表示,将视觉信息转化为语言模型可以理解和处理的形式。
显而易见,这三种方法都需要用数据集进行多模态预训练。
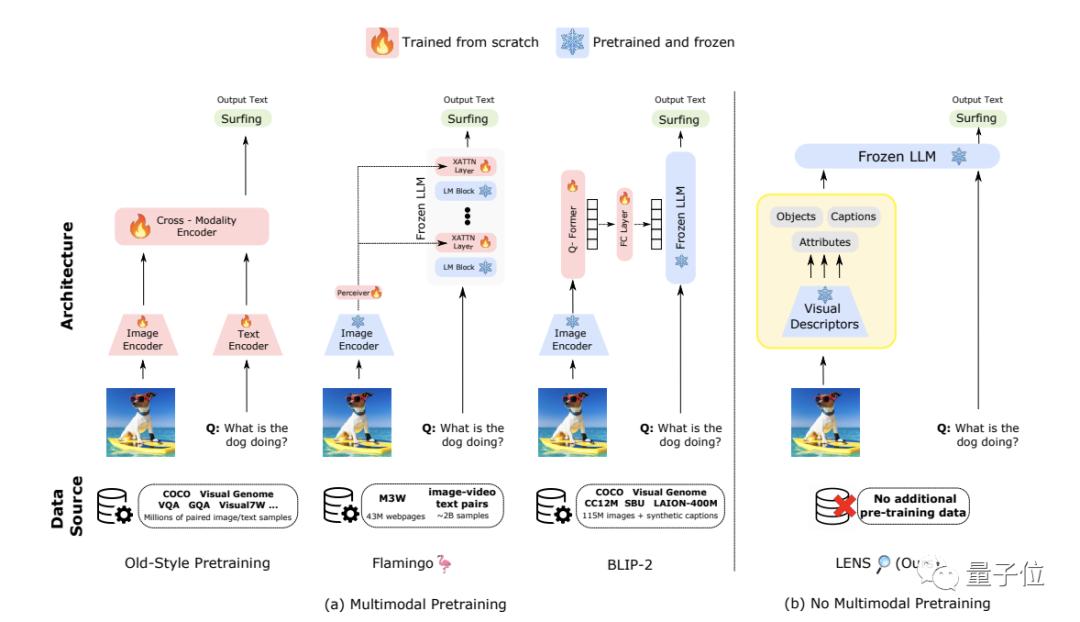
△视觉和语言模态对齐方法的比较,(a)代表上面所说的三种方法(b)是LENS的方法,��代表从头开始训练,❄️代表预训练并冻结
LENS则是提供了一个统一的框架,使LLM的“推理模块”能够从“视觉模块”提取的文本数据上进行操作。
在三个“视觉模块”中,对于标签这一模块,研究人员搜集了一个多样全面的标签词汇表。包括多个图像分类数据集,目标检测和语义分割数据集,以及视觉基因组数据集。为了能够准确识别并为图像分配标签,研究人员还采用了一个CLIP视觉编码器。
这一模块的通用提示语是:
“A photo of {classname}”
用于提取属性信息的视觉模块中,则用到了GPT-3来生成视觉特征描述,以区分对象词汇表中每个对象的类别。并且采用了一个对比预训练的CLIP视觉编码器,来识别并为图像中的对象分配相关属性。
在详细描述信息的视觉模块中,研究人员用BLIP的图像字幕模型,并应用随机的top-k采样为每个图像生成N个描述。这些多样化的描述直接传递给“推理模块”,无需进行任何修改。
而在最后的推理模块,LENS可以与任何LLM集成,将上面的提取的信息按照下面的格式进行整合:
Tags: {Top-k tags}
Attributes: {Top-K attributes}
Captions: {Top-N Captions}.
OCR: this is an image with written “{meme text}” on it.
Question: {task-specific prompt}
Short Answer:
值得一提的是,表情包也被考虑在内了,为此研究人员专门加入了一个OCR提示。
性能比CLIP好
为了展示LENS的性能,研究人员用了8块NVIDIA A100 (40GB)显卡进行了实验,并默认冷冻的LLM为Flan-T5模型。
对于视觉任务,研究人员评估了8个基准,并在零样本和少样本设置下与目标识别领域的最新模型进行了比较。
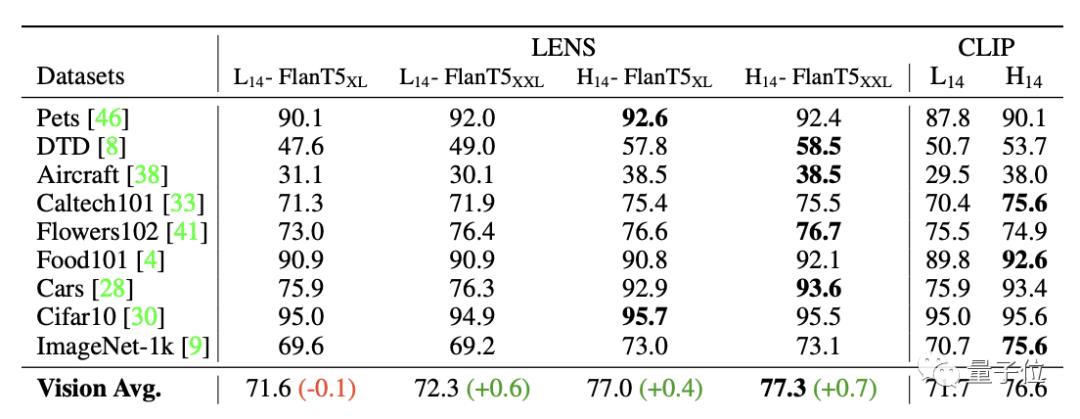
△LENS在目标识别任务中的零样本结果
经上表可看出,在零样本情况下,由ViT-H/14作为视觉主干和Flan-T5xxl作为冻结LLM组成的LENS,平均表现比CLIP高了0.7%。LENS的其它组合在大多数情况下,表现也优于CLIP。
有趣的是,研究人员在目标识别任务中发现:
冻结的LLM的大小与分类性能之间似乎没有直接关系。而标签生成架构(ViT主干)的大小与性能之间存在对应关系。
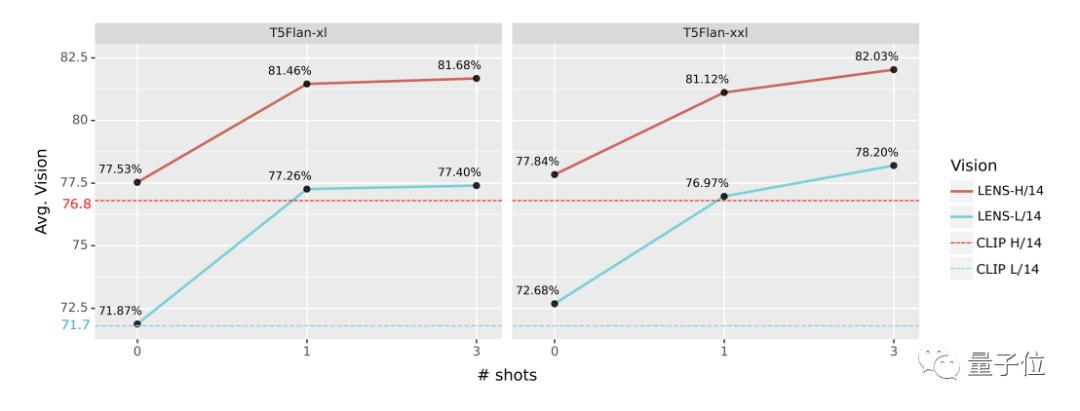
△少样本下,LENS在视觉任务上的平均性能。
如上图所示,研究人员还绘制了除ImageNet之外的所有数据集的平均视觉性能图,并观察到:
更多样本有助于提高性能。同时,冻结LLM的性能与视觉性能之间没有直接关系,而更好的视觉主干有助于提高平均视觉性能。
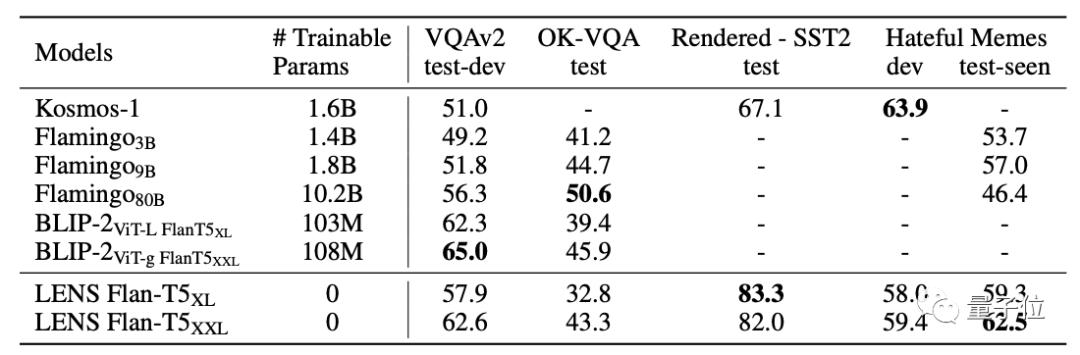
对于视觉与语言任务,研究人员评估了四个具有代表性的视觉问答任务,并与需要进行额外预训练来对齐视觉和语言模态的最新模型进行了比较。
在零样本设置上,与VQAv2、OK-VQA、Rendered-SST和Hateful Memes最先进的方法进行比较,LENS表现依旧能与依赖大量数据进行对齐预训练的方法相竞争。即使与规模更大、更复杂的系统如Flamingo、BLIP-2、Kosmos相比也是如此。
虽然LENS在大多数情况下表现良好,但也有一些失败的情况:

研究人员认为:
LENS的视觉能力严重依赖于其底层的视觉组件。这些模型的性能有进一步提升的空间,需要将它们的优势与LLM结合起来。
传送门:
[1]https://huggingface.co/papers/2306.16410(论文链接)
[2]https://github.com/ContextualAI/lens(代码已开源)
— 完 —
「AIGC+垂直领域社群」
招募中!
欢迎关注AIGC的伙伴们加入AIGC+垂直领域社群,一起学习、探索、创新AIGC!
请备注您想加入的垂直领域「教育」或「电商零售」,加入AIGC人才社群请备注「人才」&「姓名-公司-职位」。
点这里��关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~
原标题:《给大语言模型“开个眼”,看图说话性能超CLIP!斯坦福等新方法无需多模态预训练丨开源》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

