- +1
AI大神何恺明:2024年加入麻省理工学院EECS任教职

大数据文摘出品
年初的时候,AI圈有消息说何恺明将离开Facebook AI研究院,去麻省理工担任教职。

最近,据何恺明GitHub主页最新信息,这一“传言”得到了证实,何恺明说:
我将在2024年加入麻省理工学院的电子工程与计算机科学系。
I will be joining the Department of Electrical Engineering and Computer Science (EECS) at Massachusetts Institute of Technology (MIT) as a faculty member in 2024.
对此,英伟达资深科学家Jim Fan表示:如果别人加入MIT我会祝贺他,如果是恺明加入MIT,我会祝贺MIT将拥有恺明。

何恺明的论文引用数超过46万,如果他加入 MIT,那他将会成为全校被引用次数最高的学者。目前 MIT 全校被引用量最高的是化学与生物医学工程系的 Robert Langer,总引用量超过38万次。
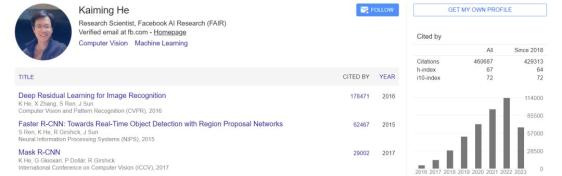
何恺明是计算机视觉领域的超级明星,别人的荣誉都是在某某大厂工作,拿过什么大奖,而何恺明的荣誉是best,best,best ...... 例如2016 CVPR 最佳论文“Deep Residual Learning for Image Recognition”以及2017ICCV最佳论文“Mask R-CNN”。
何恺明:多次按响深度学习门铃
在今年的世界人工智能大会上,商汤科技创始人汤晓鸥评价何恺明多次按响深度学习门铃:
“何恺明把神经网络做深了,谷歌把神经网络的入口拉大了,又深又大,才成为今天的大模型。”
他2009年的那篇CVPR最佳论文,是CVPR整个25年历史上亚洲的第一篇最佳论文。
他的第一项工作是在微软亚洲研究院发布的有关残差网络(ResNet)的论文。在2015年之前,深度学习最多只能训练20层,而CNN(卷积神经网络)模型ResNet在网络的每一层引入了一个直连通道,从而解决了深度网络的梯度传递问题,获得了2016年CVPR的最佳论文奖,是计算机视觉历史上被引用最多的论文。
“在ResNet之后就可以有效地训练超过百层的深度神经网络,把网络打得非常深。”汤晓鸥说,“在大模型时代,以Transformer为核心的大模型,包括GPT系列,也普遍采用了ResNet结构,以支撑上百层的Transformer的堆叠。
尤其是何恺明在Facebook期间发明的Mask R-CNN算法,首次把基于掩码的自编码思想用于视觉领域的非监督学习,开启了计算机视觉领域自监督学习的大门。
何恺明工作的重点方向
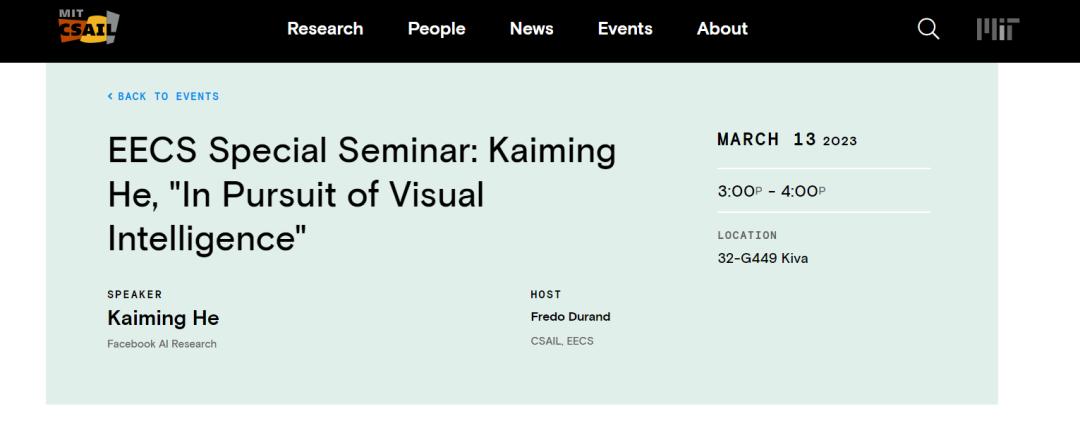
今年的3月13日,何恺明在MIT做学术演讲,演讲主题是 "In Pursuit of Visual Intelligence"(追求视觉智能)。
据说,在现场演讲中,何恺明按时间线顺序回顾其之前的几篇工作,主要包括了 ResNet、Faster R-CNN、Mask R-CNN、MoCo 和 MAE。据何恺明所言,“在 ResNet 出现以前,Deep learning 的大厦上空漂浮着一朵乌云,而 ResNet 去掉了这朵乌云。”
此外,何恺明也在现场透露了接下来的研究方向会是 AI for science,将聚焦视觉和 NLP 大一统做 self-supervised X+AI。
从参会的嘉宾那得知,他分享了两个前沿的未来方向:1、视觉世界中自监督学习的机会;2、计算机视觉研究如何通过自监督学习推广到自然科学观察,继续影响更广泛的领域。
在世界人工智能大会上,汤晓鸥也爆料说何恺明将有更重磅的工作发布。文摘菌猜应该是关于NLP和CV大一统的。
关于何恺明:从高考状元到 CV 大神
何恺明是广东人,从小在广州长大,在广州执信中学读书时曾获得全国物理竞赛和省化学竞赛的一等奖。2003年5月,何恺明获得保送清华的资格,同年他以满分900分的成绩,成为当年广东省9位满分状元之一。进入清华大学以后,何恺明放弃保送的机械工程及其自动化专业转向基础科学班。
2007年,还未毕业的何恺明进入微软亚洲研究院实习,出于对计算机图形图像课程的兴趣,他选择加入了视觉计算组。头两年里,何恺明尝试做过不少各种各样的课题,但一直发不了论文,这对此前头顶着高考满分状元光环的他来说,无疑是个不小的打击。
何恺明花了更多时间在问题研究上,甚至在电脑游戏里找灵感。不鸣则已,一鸣惊人。2009 年,汤晓鸥、何恺明以及孙剑凭借论文“Single Image Haze Removal Using Dark Channel Prior ”,获得该年度 CVPR 的最佳论文奖。
此后,何恺明一路开挂,据公众号@Smarter举例他的代表作:
2016 CVPR best paper Deep Residual Learning for Image Recognition
通过残差连接,可以训练非常深的卷积神经网络。不管是之前的CNN,还是最近的ViT、MLP-Mixer架构,仍然摆脱不了残差连接的影响。
2017 ICCV best paper Mask R-CNN
在Faster R-CNN的基础上,增加一个实例分割分支,并且将RoI Pooling替换成了RoI Align,使得实例分割精度大幅度提升。虽然最新的实例分割算法层出不穷,但是精度上依然难以超越Mask R-CNN。
2017 ICCV best student paper Focal Loss for Dense Object Detection
构建了一个One-Stage检测器RetinaNet,同时提出Focal Loss来处理One-Stage的类别不均衡问题,在目标检测任务上首次One-Stage检测器的速度和精度都优于Two-Stage检测器。近些年的One-Stage检测器(如FCOS、ATSS),仍然以RetinaNet为基础进行改进。
2020 CVPR Best Paper Nominee Momentum Contrast for Unsupervised Visual Representation Learning
19年末,NLP领域的Transformer进一步应用于Unsupervised representation learning,产生后来影响深远的BERT和GPT系列模型,反观CV领域,ImageNet刷到饱和,似乎遇到了怎么也跨不过的屏障。就在CV领域停滞不前的时候,Kaiming He带着MoCo横空出世,横扫了包括PASCAL VOC和COCO在内的7大数据集,至此,CV拉开了Self-Supervised研究新篇章。
不止于此,总结下来何恺明的研究兴趣大致分成这么几个阶段:传统视觉时代:Haze Removal(3篇)、Image Completion(2篇)、Image Warping(3篇)、Binary Encoding(6篇)
深度学习时代:Neural Architecture(11篇)、Object Detection(7篇)、Semantic Segmentation(11篇)、Video Understanding(4篇)、Self-Supervised(8篇)
总之,何恺明拥有卓越的科研直觉,总是能准确地找到最核心的问题并提出简明扼要的解决方案,这些方案体现出深厚的思维深度。
原标题:《恭喜麻省理工学院!AI大神何恺明:2024 加入 EECS 任教职》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

