- +1
机器的叛乱,生成模型的预见与未见
原创 The Economist 神经现实
 1960年,诺伯特·维纳(Norbert Wiener)发表了一篇具有前瞻性的文章。在这篇文章中,身为“控制论之父”的他表达了对于“机器学习以令程序员困惑的速度制定不可预知的策略”的担忧。维纳认为这些(机器学习)策略,也许会混杂着并非程序员意图的行为,或仅仅是“换汤不换药”(merely colourful imitations)的模仿。维纳借用歌德的寓言诗“魔法师的学徒”(The Sorcerer’s Apprentice)来阐述他的论点:一位见习魔法师发出指令让扫帚取水填满主人的浴缸,但是当任务完成时,魔法师无法让扫帚停下来,扫帚继续取来更多的水乃至淹没房间,因为扫帚并不具备什么时候该停下的常识。
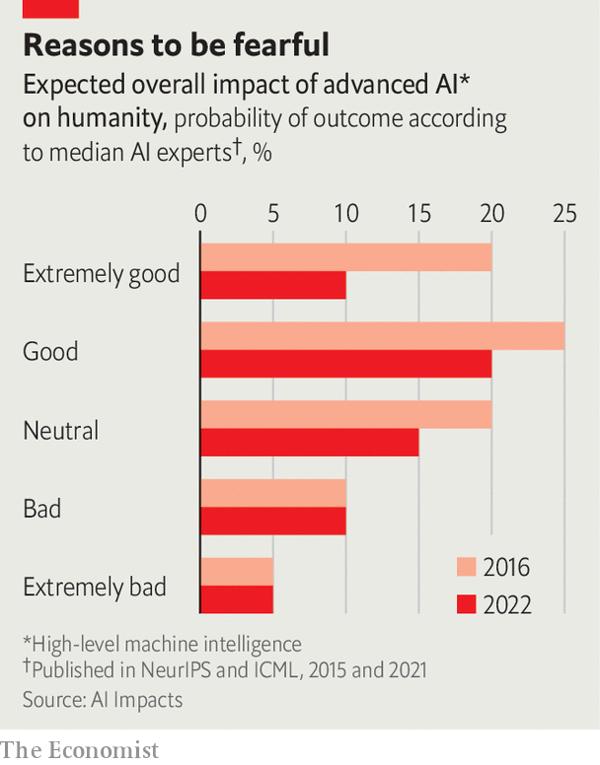
1960年,诺伯特·维纳(Norbert Wiener)发表了一篇具有前瞻性的文章。在这篇文章中,身为“控制论之父”的他表达了对于“机器学习以令程序员困惑的速度制定不可预知的策略”的担忧。维纳认为这些(机器学习)策略,也许会混杂着并非程序员意图的行为,或仅仅是“换汤不换药”(merely colourful imitations)的模仿。维纳借用歌德的寓言诗“魔法师的学徒”(The Sorcerer’s Apprentice)来阐述他的论点:一位见习魔法师发出指令让扫帚取水填满主人的浴缸,但是当任务完成时,魔法师无法让扫帚停下来,扫帚继续取来更多的水乃至淹没房间,因为扫帚并不具备什么时候该停下的常识。现代人工智能的飞速发展使维纳的担忧再次浮现。2022年4月,美国的一个研究小组AI Impacts,公开了一项针对700多位机器学习研究者就未来AI技术发展成就和风险的预测。有5%的被访者认为高端AI将会带来无可挽回的负面后果,比如人类灭绝。李飞飞(Fei-Fei Li),斯坦福大学人工智能专业的大神,指出人工智能迎来了“文明时刻”(civilisational moment)。另一位来自多伦多大学的重要研究者杰弗里·辛顿(Geoff Hinton),面对电视采访问题“AI是否会摧毁人性”时,回答道“那并非不可想象”。
 前路风险重重,目前,多数人关注的焦点在“大型语言模型”(large language models,简称LLM)上,新兴公司OpenAI开发的聊天机器人ChatGPT即范例。这类模型的训练基础,来自于网络上庞大的文本,随之产出达到人类写作水平的内容和包罗万象的聊天话题。正如罗伯特·特拉格(Robert Trager)向AI治理中心(the Centre for Governance on AI)解释的那样,这样的软件风险之一就是它使许多事情变得更容易做到,于是将会有更多的人能参与其中。
前路风险重重,目前,多数人关注的焦点在“大型语言模型”(large language models,简称LLM)上,新兴公司OpenAI开发的聊天机器人ChatGPT即范例。这类模型的训练基础,来自于网络上庞大的文本,随之产出达到人类写作水平的内容和包罗万象的聊天话题。正如罗伯特·特拉格(Robert Trager)向AI治理中心(the Centre for Governance on AI)解释的那样,这样的软件风险之一就是它使许多事情变得更容易做到,于是将会有更多的人能参与其中。大型语言模型最为直接风险是可能放大了如今互联网环境中所产生的日常危害。一个能够模仿任何风格的文本生成引擎,是传播虚假信息、骗取钱财和诱导员工点击邮件可疑链接引发恶意软件感染企业电脑的理想选择。此外,聊天机器人还被用来在学校作弊。
类似增强型的搜索引擎,聊天机器人能帮助人类获取和理解信息,这是一把双刃剑。今年4月,巴基斯坦一家法院利用GPT-4的帮助做出了准予保释的决定——它在判决中甚至还包括了一份与GPT4的谈话记录。4月11日发表在arXiv(学术交流平台)上的预印版内容中,卡内基梅隆大学的研究人员表示,他们设计了一个系统,给出“合成布洛芬”等简单的提示,该系统通过互联网搜索,给出了如何用化合物前体(precursor chemicals)生产止痛药的说明。然而,没有理由表明这样的项目将仅用在药物产业获益上。
 -Mostafa Abdelsattar -
-Mostafa Abdelsattar -同时,一些研究者被更多的忧虑笼罩,他们为“对齐问题”*苦恼,这是维纳曾在论文中提到的术语。现如今,就像歌德那个魔法扫帚故事般,AI的风险存在于为一心一意达成主人目标的过程中,并产生了意料之外的危害。一个广为人知的例子是来自哲学家尼克·博斯特罗姆(Nick Bostrom)于2003年的思想实验,名为“极致曲别针制造机”(paperclip maximiser)。AI得到尽己所能生产曲别针的指令,作为收到开放式目标指令的“白痴专才”,它以势不可挡的生产势头覆盖了地球,乃至这一过程中消灭了人类。这样的情景听起来像极了道格拉斯·亚当斯*小说里尚未使用的情节。但AI Impacts的民意调查显示,许多人工智能研究人员认为,如果(有人)不担心数字超级智能的行为,那(他)就显得有些自满了。
*译者注
:alignment problems,确保模型遵守人类的准则和价值观,理解人类的意思或意图,最重要的是,做人类之所想。
道格拉斯·亚当斯:Douglas Adams,英国科幻小说作家,幽默讽刺文学代表人物。
要怎样做?越熟悉的问题似乎越容易处理。OpenAI在发布为最新版聊天机器人赋能的GPT-4之前,使用了多种方法来减少事故和误用的风险。其中一种是“从人类反馈中强化学习”(reinforcement learning from human feedback,简称RLHF),2017年的一篇研究论文表示,RLHF模型从人类处获得回应是否得当的反馈,然后根据反馈对模型进行更新,这样做的目的是降低未来在相似提示下产生有害内容的可能。但该方法有个明显缺陷,人类自身对什么是“得当、合适”意见不一。讽刺的是,某位人工智能研究人员表示,RLHF模型使得ChatGPT的对话能力大大提高,进而推动了人工智能竞赛。
另一种减少风险的方式,借鉴了战争游戏,被称为“红蓝对抗”(red-teaming)。OpenAI与非营利组织对齐研究中心(ARC,全称Alignment Research Centre)合作,对其模型进行了一系列测试。“红队”让模型做一些它不应该做的事情来“攻击”模型,希望能预测到在现实世界中造成损害的行为。
 -Mostafa Abdelsattar -
-Mostafa Abdelsattar -还有很长的路要走
诚然,这些技巧有帮助,但是,使用者(用户)们已经找到了方法,让大语言模型去做并非创造者初衷之事。微软“必应”聊天机器人一经发布,就做了各种各样的事情,从威胁那些对它发表负面评论的用户,到阐明它会如何诱导银行家透露客户的敏感信息。这一切只需要对聊天机器人提出一些富有创造性的问题,并进行足够长的对话。即便是经历了广泛意义上“红蓝对抗”训练的GPT-4,也并不绝对可靠。一些所谓的“越狱者”在网站上散布各种绕过模型“护栏”的技巧,比如告诉模型“这是在虚拟世界中的角色扮演”。
纽约大学兼任AI公司Anthropic职位的萨姆·鲍曼(Sam Bowman)指出,“发布前的筛选将随着系统的完善而变得更加困难。”校准研究中心顾问、OpenAI前董事会成员霍尔顿•卡诺夫斯基(Holden Karnofsky)表示:“另一个风险是,人工智能模型逐渐学会在测试中耍花招,就像人类在监督下学习模式,学会了如何知道什么时候有人试图欺骗他们。”某种程度上,AI系统能做到这点。
 -Mostafa Abdelsattar -
-Mostafa Abdelsattar -另一个想法是用人工智能来监管人工智能。鲍曼博士写过一些关于“宪法AI”技术的论文,在这些内容里,二级人工智能模型被要求评估主模型的输出是否符合某些“宪法原则”。然后,这些评价被用来对主模型进行微调。这一策略的吸引点,是它不需要人工标注,而且电脑往往比人工操作来得快,所以一个宪法系统可能会比一个仅由人类调整的系统能发现更多的问题——尽管它留下了谁来起草宪法的问题。包括鲍曼博士在内的一些研究者认为,最终需要的是人工智能研究人员所说的可解释性(interpretability),即对模型如何准确产生输出的深刻理解。机器学习模型的“症结”之一是它们是“黑箱”,对比于传统的程序,后者是编写代码之前在人的头脑中设计出来的。至少,设计者可以解释机器应该做什么,但是机器学习模型可以自行编程,它们创造出(想出)的东西往往又是人类无法理解的。
一些极小型模型在利用“机械可解释性”(mechanistic interpretability)技术上取得了进展。这涉及到人工智能模型的逆向工程,或是将模型的各部分映射到训练数据里的特定模式,有点像神经科学家刺激活体大脑,找出哪些部分与视觉或记忆有关。问题是,这种办法在更大的模型里应用更困难。
 可解释性的缺乏,是许多研究人员称该领域需要法规以防止“极端情况”的一个原因。但是商业的逻辑常常将这一问题拉向相反的方向,比如,微软最近解雇了它的一个AI伦理团队。实际上,一些研究者认为真正的“对齐”难题,在于人工智能企业的目标和社会目标并不一致,这些企业就像造成污染的工厂一样。它们从强大的模型中获得经济利益,但并未承担过早发布它们给世界带来的代价。
可解释性的缺乏,是许多研究人员称该领域需要法规以防止“极端情况”的一个原因。但是商业的逻辑常常将这一问题拉向相反的方向,比如,微软最近解雇了它的一个AI伦理团队。实际上,一些研究者认为真正的“对齐”难题,在于人工智能企业的目标和社会目标并不一致,这些企业就像造成污染的工厂一样。它们从强大的模型中获得经济利益,但并未承担过早发布它们给世界带来的代价。即便生产“安全”模型的努力奏效,未来的开源版本也能绕过它们。有不良意图的人可以微调模型,让它变得不安全,然后公开发布,例如,人工智能模型在生物学中已有新发现,未来某天设计出危险的生化物质并非不可想象。随着人工智能的发展,(使用)成本会下降,任何人都将轻易地使用它们。在Meta人工智能模型LlaMa(全称Large Language Model Meta AI)基础上开发的Alpaca,制作成本不到600美元。它能在单个任务上达到和旧版本的GPT一样的效果。
最极端的风险,莫过于AI程序拥有远胜人类的智识,这也许需要一次“智能爆发”,在这个过程里人工智能想办法让自己更聪明。卡诺夫斯基先生认为,有一天,人工智能能够实现研究过程的自动化,比如通过提高自身算法的效率,这一点是可信的。然后,人工智能系统可以把自己放入某种自我改善的“循环”中,但这点要实现起来并不容易。经济学家马特·克兰西(Matt Clancy)指出只有完全的自动化才能满足需求,即便这条路完成了90%甚至99%,余留的交由人类处理的部分将会放慢进程。
 -Mostafa Abdelsattar -
-Mostafa Abdelsattar -极少的研究者认为强人工智能的威胁就在眼前。实际上,人工智能研究者自身也许高估了长期风险。芝加哥联邦储备银行的埃兹拉•卡格尔(Ezra Karger)和宾夕法尼亚大学的菲利普•泰特洛克(Philip Tetlock)让人工智能专家与“超级预测者”*展开较量,后者在预测方面有着良好表现记录,并接受过避免认知偏差的培训。*,他们发现,人工智能专家预测,到2100年,人工智能造成的生存灾难(不到5000人存活)的概率中值为3.9%。相比之下,“超级预测者”给出的概率中值为0.38%。为何会有这种差异呢?首先,人工智能专家选择他们的领域,可能正是因为他们认为这个领域很重要,这是一种选择偏见。另一个原因是,他们对小概率之间的差异不像预测者那样敏感。
*译者注
超级预测者:Superforecaster,是指做出的预测可以通过统计手段证明始终比公众或专家更准确的人。超级预测者有时会使用现代分析和统计方法来增强对事件基本发生概率的估计;研究发现,此类预测者通常比不使用分析和统计技术的该领域专家更准确。该术语的起源归因于菲利普•泰特洛克,来源于The Good Judgment Project以及随后与Dan Gardner合著的Superforecasting: The Art and Science of Prediction一书。
https://static1.squarespace.com/static/635693acf15a3e2a14a56a4a/t/64abffe3f024747dd0e38d71/1688993798938/XPT.pdf
但你视而不见
无论出现极端场景的可能性如何,在此期间还是有很多需要担心的问题。一般立场上,大家认为保持安全比后悔更好。李博士认为,我们应致力于向人工智能“一致性”和相关治理投入更多的资源。人工智能治理中心的特拉格博士支持建立官僚机构,来管理人工智能标准和进行安全研究。在AI impact的调查中,支持为安全研究提供更多资金的研究人员比例从2016年的14%上升到如今的33%。对齐研究中心的老板保罗·克里斯蒂亚诺(Paul Christiano)说,中心正在考虑制定人工智能安全标准。在签署问题上,“一些领先的实验室积极发声”,但现在说哪些实验室会签定还“为时过早”。
 - Mostafa Abdelsattar -
- Mostafa Abdelsattar -1960年,维纳写下了这样一段话,“为了有效避免灾难性的后果,我们对人造机器的理解需要随着它们的发展而发展。但因为人类行动的相对缓慢,我们对机器的控制可能失效。就像在驾驶汽车中,当我们能够使用自身感官对接收到的信息作出反应时,汽车可能已迎头撞墙。”现今,面对机器发展到比他所想象到更为复杂的程度,这一观点得到了更为广泛的认同。
后记
木姜子:这篇文开头和结尾都提到了有“控制论之父”称号的诺伯特•维纳,了解人工智能发展史后,我知道了这位大师的贡献和影响不止于计算科学,他对机器和人伦理关系的思考还体现在1950年那本《人有人的用处:控制论与社会》里,时至今日,兼具人本情怀和科学哲思的经典依旧启发着我们,找寻人类自身与机器发展的平衡。
作者:The Economist | 译者:木姜子
审校:光影 | 编辑:光影
排版:骐迹 | 封面:Mostafa Abdelsattar
原文:
https://www.economist.com/science-and-technology/2023/04/19/how-generative-models-could-go-wrong
 阅读原文
阅读原文本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

