- +1
用图形教AI认识分子:分子图预训练进展一览
前沿科技投资孵化
2023年8月23日,未来光锥AI For Science社群分享第七期邀请到中国科学院自动化所副研究员刘强博士,介绍“数据视角下的分子图预训练”。以下为未来光锥对刘强博士分享内容,以及部分观众提问进行的简要整理。

分享嘉宾:刘强
中国科学院自动化研究所副研究员
我是中科院自动化所多模态人工智能国家重点实验室的副研究员刘强。我主要的研究领域做是数据挖掘和机器学习的方法。本次分享主要围绕这些方法在化学分子上的应用。我们主要关注的是分子的表达学习和分子预训练,以及在这种框架下获得的数据维度的研究发现。
分子的表达学习
分子,有大分子,也有小分子。分子的功用也不同。分子表达学习想做的就是把分子中的原子和整个分子都转化成连续的特征向量。有了特征向量,就可以做很多下游任务,比如,药物发现、药物性质预测、药物生成等。我们希望这种分子的表达能够充分地表现化学分子的化学性质以及结构拓扑性质。
目前有几种方法可以表达化学分子,其中最常用的就是二维的图结构(2D Graph),将分子的结构投影到二维上,不同的原子就是图形中的节点,原子间的键就是图形中的边。还有一个方法叫做Fingerprint,这是在化学领域中出现得比较早的方法,类似于一种特殊的特征工程的方法。这种方法通过二值化的形式对分子进行编码。第三种是SMILES序列,这种方法也比较常见。这种方法将二维的分子图进行遍历,进而形成序列。最后,有越来越多人开始探索三维分子图,它与二维分子图的二维结构是一样的,但是有三维坐标,这样一来,不仅可以表示原子之间、键与键之间的连接关系,还可以表示出原子之间键的键长、键与键之间的夹角、面与面之间的旋角。这种方式可以帮助我们更复杂的分子信息。

图1 常见的四种表达化学分子的形式|来自分享内容PPT
之所以要进行分子表达学习,举个例子,根据FDA统计,制作一款药物的背后可能有5千到1万个候选,从中再挑出250个进行测试的药物分子,最后进行临床试验的话可能只有5种。通过表达学习,可以更好地把握分子的性质,帮助我们在筛选过程中提升效率,更好地进行药物、材料的发现。最常见的表达式学习是一种监督式的学习。也就是将分子的特征输入到一个神经网络中,通过神经网络的映射,最后输出它的不同性质,比如是否有毒性、水亲和力如何等。
刚才说的四种表达形式,其实也是分子表达学习的发展历程,首先是Fingerprint的结构,它比较简单,就是二值化的特征表示;随后是SMILES序列,在深度学习中,会用循环神经网络RNN或者STM,以及最近今年比较新的Transformer机构对序列结构进行建模。然后,这种二维的图结构是当下主要的一个研究点,它的建模方式就是较为常见的图神经网络,即将图里面的每一个原子表成一个节点,然后通过图神经网络的聚合-消息传递关系得到整个图的特征表示。三维图基本上也是基于这种图形网络进行建模的,但在建模中需要考虑它的三维特性,也就是刚才提到的键长、键角等空间特性。
上述这种有监督的分子表达学习、性质预测存在比较大的缺陷。第一个在深度学习中比较常见的缺陷是,数据量比较少,而且分子的测量数据价格也比较高。测一个分子的性质需要花费很多钱。由此一来,数据量就比较小,针对某一种特性的数据集也会比较小。而且,还会有跨域和域泛化的问题。因此,现在很多人都在关注化学分子预训练的问题。
分子预训练方法
预训练的模型,今年有一个比较热门的,大家也都听过 ChatGPT,效果比较好。它最早在自然语言处理中应用较多。最近有很多研究者在这个基础上探索化学分子的预训练模型,旨在学习这种通用的分子表达,然后助力各种下游任务。
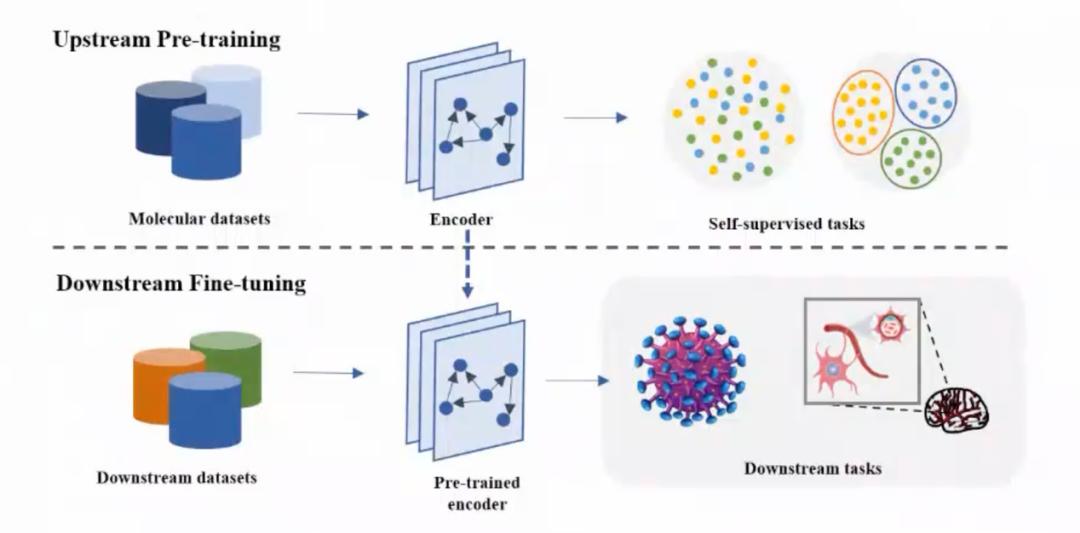
图2 分子预训练流程图|来自分享内容PPT
分子预训练首先会从各个渠道和各种测试中收集大量的、无标注的分子数据集;然后通过一个Encoder结构进行自监督、无监督的学习;随后再根据具体任务的不同对上游的具体数据进行微调,然后辅助不同的药物发现和药物性质预测的任务(图2)。
分子预训练方法综述
图3是目前整个分子预训练的方法汇总图,包括两方面,一个是Encoder结构,一个是预训练学习的策略。图3中,Encoder部分我只列出了图神经网络和Transformer两种,因为这是目前的主流。
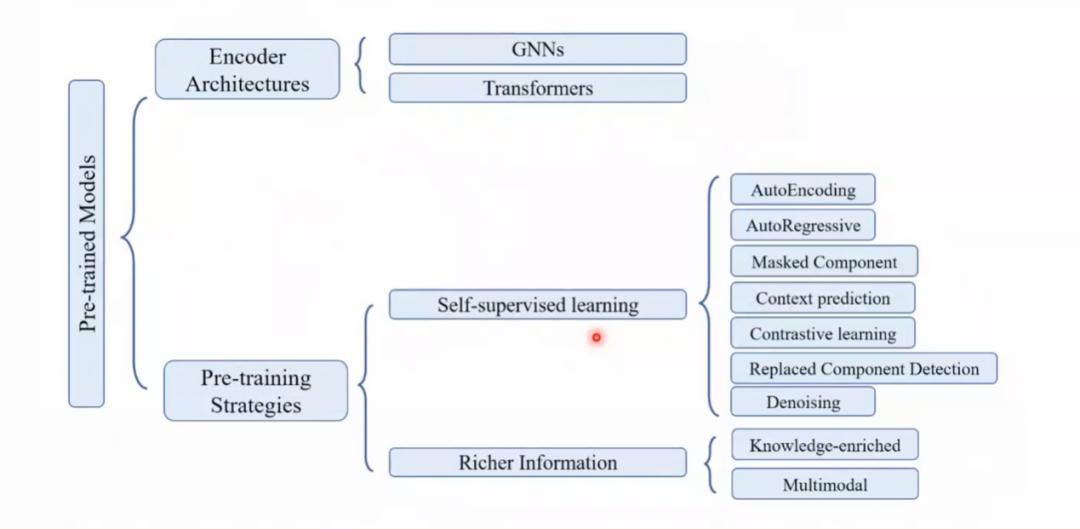
图3 分子预训练方法汇总图|来自分享内容PPT
预训练策略中,最简单的一种自监督策略就是自编码机(AutoEncoding),这是深度学习中一种比较早的方法,就是把分子的特征输入到Encoder编码器中得到编码后的表达,然后再解码恢复原始特征。这种方式的效果不是很好,因为它只关注分子内部的单一的结构,没有比较分子之间的结构,也没有做分子的特征增强、特征扰动等。
第二种方法是自回归模型(AutoRegressive Modeling)。它与语言模型比较相似,将分子中的原子一个个生成出来,比如,图4中的环状结构,就可以先生成A1键,然后是A2键,以此类推,一个个生成。这个方法的计算量比较大,因为需要将一个个特征逐次生成,是一个串行的步骤。同时,因为分子中的原子顺序不是固定的,采用自监督的方式一个个生成,其实存在着一定的不合理性。

图4|来自分享内容PPT
第三种方法是基于上下文的预测(Context Prediction),这种方法用得比较少,效果也一般。这种方法是基于分子中的两个不同区域,然后预测这两个区域之间是否有重合的中心原子。这个方法的问题是计算量很大,但是效果不佳。
第四种方法是替换元素检测(Replaced Components Detection),这个方法用得也不多。这种方法是对分子的某些部分进行替换,然后判断替换的这个部分和分子中的另外一部分是否来自于同一个原子。
第五个方法比较常见,叫对比学习法(Contrastive Learning)。这个方法不仅在分子领域应用广泛,在各种文本、视频、图像的自监督训练中也非常常见。它的基本思想是,基于一个原始的特征,以及一个轻微扰动后的特征,这两个特征分别进入Encoder得到表达——我们希望这两个表达可以尽量相近。在分子领域中,这种学习策略可以进一步分为cross-scale和same-scale两种对比方式。cross-scale是分子和局部结构之间的表达的对比;same-scale是对原始输入的分子进行扰动,然后进行原始分子和扰动后分子特征的对比。这种方法虽然应用广泛,但是还是存在一些缺点,第一是很难保证数据扰动增强的合理性。还有就是,即使是轻微的扰动,也可能会造成分子之间的性质相差很大。因此,这两个缺陷使得这个方法在化学中的应用可能不成立。但是目前来看,效果整体上说还是不错的。
下一个方法是基于掩码的学习(Masked Components Modeling),它是继对比学习法后,相对较火的一种方法。这种方法通过遮盖输入特征中的某些维度,进而让模型通过其他的特征维度去恢复被遮盖的特征维度。无论是在语言模型,还是图像模型中,这个方法的效果都是非常好的。但是在分子预训练领域,这个掩码策略的效果目前还不太理想。可能的原因是,目前的训练过程中,掩码的位置都是比较固定的,训练出来的泛化性就会相对较弱。还有一个比较新的策略,叫去噪(Denoising)。其基本思想是,在原始输入中增加一个极小的噪声,通过Encoder去预测这个噪声。
还有一些自监督之外的预训练策略——增加数据维度。第一种是增加知识图谱,比如加入化学的知识图谱。第二种是加入更多的模态,将化学分子与描述化学分子的文本对齐,帮助学习。
以数据为中心:数据对分子表示学习和预训练模型的影响
在分子图表达学习中还没有人研究过数据与模型的关系。我们想要了解的是,数据的应用和表达学习的能力之间的关系是怎样的,是否遵循某些规律,比如power-law(图5)

图5 Power law|来自分享内容PPT
图6是基于现有研究总结出的学习曲线和数据量之间的关系,我们要研究的便是,在分子表达学习领域是否也存在power-law规律。因此,我们做了很多实验来验证分子表达学习的性能和数据之间的关系,然后探索了分子表示学习的性能和数据量、模态等方面的关系。我们总结发现,还是2D图的特征是最强的。
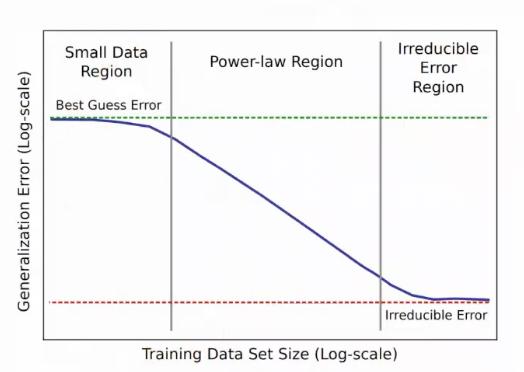
图6 基于现有研究总结出的学习曲线和数据量的关系|来自分享内容PPT
最后,我们做了一个数据修剪(Data Pruning)的实验。我们期望,在训练和预训练模型时,可以用尽可能少的数据达到和完整使用数据差不多的效果。这样就可以极大地提高训练的效率。我们测试了多种数据修剪策略,但是从结果上来看,结果都比较差。如何进行样本挑选以实现更高效的数据修剪还有很大的研究空间。
前景
首先,数据修剪:如何设计高效的数据修剪策略,实现高效的预训练和表示学习。第二,设计更好的预训练策略,比如前文提到的基于掩码的策略的方法,虽然在分子领域的效果目前看来较差,但在其他数据类型下的效果是较好的,因此有较大的研究发展空间。第三,如何更好地应用所有数据模态,综合利用它们的效果。最后,还有一些更有挑战的场景等待我们去研究,比如域泛化的表达学习以及小样本和跨域的问题。
观众提问
观众1
刘老师好,我们最近在观众用图网络去预测一些性质,比如说一个结构它对应的计算的能量。但是能量需要3D结构才能准确地确定,但是我们只有2D图的信息,这个过程就需要我们对它的能量的波动进行预测。因此我比较想知道,在图学习方面,如果我们给出一个图,如何确定其中的不确定性,比如说,这个不确定性到底是因为我们输入的信息是2D的形式导致的,还是样本分布导致的?
刘强
我大概理解你的问题。我感觉这个问题比较难。因为不确定性还是从模型的角度给出的更多。是否能衡量这个不确定性是不是数据带来的,我觉得需要一些实验。目前很难给出确定的回答。
观众2
我们平时做科研有时会合成一些周期性的催化剂的一些东西,这方面网络上有一些数据库,您可能也知道,Materials project,它里面会有一些训练。您现在用的这些数据训练数据是从哪里采集的呢?是从文献呢?还是从类似于Materials project的数据库?
刘强
我们大部分是用有人整理好的数据库。我们也和一些单位进行合作,他们有自己测的数据,比如说我们在做的药物代谢,某中人吃进去,ta代谢的规律是怎样的,这种就由该机构提供数据。
原标题:《用图形教AI认识分子:分子图预训练进展一览 | 未来光锥AI For Science社群分享回顾》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

