- +1
贝叶斯方法如何帮助比较案例研究?| 研究
编者荐语:
合成控制方法是在比较案例研究中用于评估干预效果的重要统计方法,被广泛运用于政治学和经济学研究。然而,合成控制法尚不能完全解决比较案例研究面临的预测和推断挑战。本文提出了一种基于贝叶斯方法的动态多层次模型,并详细说明了建构模型的假设及应用。本文提出的方法对在特定条件下进行比较案例研究具有优势,也启发了未来研究在此之外的拓展。

贝叶斯方法如何帮助比较案例研究?
摘要:
本文提出了一种用于比较案例研究中单个或多个处理单元的贝叶斯方法,以替代合成控制法(synthetic control method)。我们采用了贝叶斯后验预测方法来处理鲁宾的因果模型(Rubin’s causal model),该方法允许研究人员基于实证后验分布对处理观察的反事实情况进行个体和平均处理效应的推断。我们所开发的预测模型是一个动态多层次模型,其中包含一个潜在因子项,用于校正由单元特定时间趋势引起的偏差。该模型还考虑了协变量(covariates)与结果之间的异质性和动态关系,从而提高了因果估计的精度。为了减少模型依赖性,我们采用了贝叶斯收缩方法进行模型搜索和因子选择。蒙特卡洛实验表明,我们的方法比现有方法产生了更精确的因果估计。即使样本量较小且数据中存在丰富的异质性,该方法也能够实现正确的频数覆盖率。我们通过两个政治经济学的实证案例来说明这一方法的应用。
作者简介:庞珣,北京大学
刘力成,麻省理工大学
徐轶青,斯坦福大学
文献来源:
Pang, Xun, Licheng Liu, and Yiqing Xu. “A Bayesian Alternative to Synthetic Control for Comparative Case Studies.”Political Analysis 30, no. 2 (2022): 269–88.

本文作者(从左至右):庞珣、刘力成、徐轶青
一、引言
随着合成控制方法的引入,在社会科学领域,使用时间序列横截面(TSCS)数据或长面板数据进行比较案例研究变得越来越流行。与其他定量社会科学研究相比,比较性案例研究具有一些独特的特点:(1)样本包括少量的聚合实体;(2)少数单位(units)或一个单位接受非随机分配的干预;以及(3)处理效应通常需要一段时间才能显现出来。因此,鉴于数据有限,比较性案例研究面临两个主要挑战:为处理单元的“反事实结果轨迹提供良好的预测”;并进行可信的处理效应的统计推断。
合成控制法使用控制结果的凸组合(编者注:即convex combination,指在凸几何领域,点的线性组合,要求所有系数都非负且和为 1)来预测处理单元的反事实情况。受合成控制法启发,大量文献提出了各种新方法,以改进合成控制法的反事实预测性能和稳健性,或扩展合成控制法以适应多个处理单元。这些方法可以分为三类:(1)匹配或重新加权方法,例如最佳子集、正则化权重以及面板匹配;(2)显式结果建模方法,例如贝叶斯结构时间序列模型、潜在因子模型(LFMs)以及矩阵补全方法;以及(3)双重稳健方法,例如增强型合成控制法和合成差异法(DiD)。
然而,现有方法尚未完全解决推断和预测挑战。合成控制法使用安慰剂测试作为推断工具,但使用者不能将其解释为置换检验(编者注:置换检验是统计学中一种基于反证法、重抽样原则的非参数性检验),因为处理不是随机分配的。因此,研究人员无法以传统方式量化其估计值的不确定性。其他频数推断方法需要一个重复采样的解释,这往往与许多比较案例研究核心的固定单位群体(fixed population of units)相冲突。此外,从预测的角度来看,研究人员可以在时间序列横截面数据中使用多种信息进行反事实预测,包括(1)已知“过去”和未知“未来”之间的时间关系,(2)基于观察到的协变量的单位相似性的横截面信息,以及(3)基于其结果轨迹的单位之间的时间序列关系。虽然更好的预测性能可以转化为更精确的因果估计,但现有的基于模型的方法具有相对刚性的参数假设,因此没有充分利用数据中的信息。
而贝叶斯方法是一个能够解决现有挑战的替代方案。首先,贝叶斯不确定性度量易于解释。贝叶斯推断通过在观察数据和假设模型的条件下提供“概率陈述”来解决推断问题。其次,贝叶斯多层次建模是捕捉数据中多种异质性和动态性的强大工具。它可以适应灵活的函数形式,并使用缩减先验选择模型特征,从而减少模型依赖性并纳入建模不确定性。
在本文中,我们采用贝叶斯因果推断框架来估计比较案例研究中的处理效应。该框架将因果推断视为一个缺失数据问题,并依赖于处理反事实的后验预测分布,以对处理效应进行推断。在这种假设下,缺失属于“非随机缺失”(MNAR)类别,因为允许分配机制与未观察到的潜在结果相关。基本思想是在观察到的未处理结果矩阵中执行低秩逼近,以便在(T × N)矩形结果矩阵中预测处理反事实。我们依赖的一个关键假设称为潜在忽略性(latent ignorability assumption),它表示在外生协变量和未观察到的潜在变量的条件下,处理分配是可忽略的,这些潜在变量是从数据中得知的。
从概念上讲,潜在忽略性假设是严格外生性假设的一个延伸。使用时间序列横截面数据的现有因果推断方法依赖于两种类型的假设来进行识别:一是严格外生性,这是传统的双向固定效应方法的假设,它暗示了DiD设计中的“平行趋势”;二是顺序忽略性,它在最近变得流行起来。严格外生性要求在给定一组外生协变量和未观察到的固定效应的条件下,处理分配独立于潜在结果的整个时间序列。它排除了过去结果对当前和未来处理分配的潜在反馈效应。其主要优势在于允许研究人员调整特定单位的异质性,并使用来自一组固定控制单位的同期信息来预测处理后的反事实,这是单因子模型的一个关键见解。另一方面,顺序忽略性允许处理概率受到包括已实现结果在内的过去信息的影响。在本文中,我们采用严格外生性框架,因为它与单因素模型背后的假设一致。
具体而言,我们提出了一个动态多层次潜在因子模型(以下简称DM-LFM),并使用马尔可夫链蒙特卡洛(MCMC)方法开发了一个估计策略。它引入了一个潜在因子项,用于校正由于处理时间和随时间变化的潜在变量之间的潜在相关性引起的偏差,这些潜在变量可以通过因子结构表示,例如不同单位之间的趋势分歧。它还允许协变量系数在单位或时间上变化。由于模型参数丰富,我们使用贝叶斯收缩先验来进行随机变量和因子选择,从而减少模型依赖性。我们开发的 MCMC 算法在同一迭代抽样过程中同时进行模型选择和参数估计。在估计 DM-LFM 后,贝叶斯预测通过将所有模型参数积分得到每个反事实结果的后验分布。
我们的方法适用于具有一个或多个处理单位的比较案例研究。与合成控制法类似,它需要大量的处理前时期和比处理多的控制单位,以准确估计处理效应。我们的模拟研究表明,要使方法达到令人满意的频数特性,处理单位的处理前时期数量需要大于20。与合成控制法或潜在因子模型相比,我们的方法在以下情况下最为合适:(1)不确定性度量具有重要的政策或理论含义;(2)研究人员怀疑潜在因子结构复杂,因子数量大,或某些因子相对较弱;(3)许多潜在的处理前协变量可用,并且它们与结果变量的关系可能在单位或时间上变化;或(4)研究人员对如何选择反事实预测的协变量知之甚少。
二、贝叶斯因果推断:后验预测分布
我们首先介绍基本设置并确定符号。然后,我们定义感兴趣的因果量,并基于几个关键假设开发反事实的后验预测分布。在这一过程中,我们将使用两个实证示例。第一个是关于德国统一的案例。选择这一案例的原因如下:首先,数据集中只有一个单位(西德)受到了处理,而这一历史事件作为处理仅发生了一次。其次,控制组包括16个经济合作与发展组织(OECD)成员国,这个组中没有任何一个单独的国家或他们的简单平均可以作为西德的适当反事实。此外,统一的影响可能会逐渐在时间上显现。第二个示例是研究美国选举日注册(election day registration,以下简称为EDR)对选民投票率的影响。与第一个示例相比,它代表了比较案例研究的更一般设置,即其中有多个处理单位,并且处理在不同的时间点开始。
2.1 设置和估计量
我们将 i = 1,2,...,N 和 t = 1,2,...,T 表示为观察到结果的单位和时间。虽然我们的方法可以适应不平衡的面板数据,但出于符号上的方便,我们假设采用平衡面板。我们考虑一个二进制处理 wit,一旦它取值为 1,就不能再逆转为 0(staggered adoption,交错采用)。我们将每个单位的采用(处理)时间定义为随机变量 ai,它在集合A = {1,2,...,T,c} 中取值,其中 ai = c > T 表示单位 i 属于残余类别,并且在观察到的时间窗口内不受处理。如果单位 i 在任何观察到的时间期间采用了处理(ai =1,2,...,T),我们将其称为受处理单位;如果它在期间 T 之前从未采用处理(ai = c),我们将其称为控制单位。受处理单位的处理前时期数量为 T0,i = ai −1。假设有 Nco 个控制单位和 Ntr 个受处理单位;Nco + Ntr = N。在比较性案例研究中,Ntr = 1 或为一个较小的整数。
将 wi = (wi1,...,wiT )' 表示为单位 i 的处理分配向量。交错采用意味着采用(处理)时间 ai 唯一地确定了向量 wi:wi (ai ),其中如果 t < ai,则 wit = 0,如果 t ≥ ai,则 wit = 1,对于 t = 1,2,...,T。我们进一步定义一个(N×T)的处理分配矩阵 W = {w1,...,wN };同样,W完全由采纳时间向量 A = {a1,...,ai,...,aN } 确定。我们根据以下两个假设排除了横截面溢出和预期效应。
假设1(横截面稳定单位处理值假设(SUTVA))。单位 i 的潜在结果仅是单位 i 的处理状态的函数:yit(W)=yit(wi), ∀ i, t。
这个假设排除了横截面溢出效应,并显著减少了潜在结果轨迹的数量。对于每个单位 i,因为现在只有 (T + 1) 种可能的 wi,存在 (T + 1) 种潜在的结果轨迹,用 yit(wi) 表示,其中 t = 1,2,...,T。在德国统一的示例中,这个假设排除了德国统一影响其他16个国家的经济增长的可能性,这实际上可能是一个强假设。在 EDR 的示例中,这个假设意味着州 B 采纳 EDR 法律不会影响州 A 在是否有 EDR 法律的情况下的投票率。
假设2(无预期假设)。对于所有单位 i,对于采纳之前的所有时期 t < ai:
yit(ai)=yit(c), for ti
其中 yit (c) 是在“纯控制”条件下的潜在结果,即处理向量 wi 包含所有零。这个假设表明,当前未处理的潜在结果不取决于单元将来是否会接受处理。当预期单位将来会采取处理影响其今天的结果时,这个假设被违反。例如,如果人们预期德国统一将在1990年发生,并且西德的经济在1990年之前就调整到了这一预期,那么这个假设将被违反。
2.2 分配机制
Rubin等人(2010)奠定了贝叶斯因果推断的基础,将“因果推断完全视为一个缺失数据问题”。一般来说,通过使用观察到的结果和协变量,以及分配机制,我们可以从后验预测分布Pr(Y(W)mis |X,Y(W)obs,W)中随机估算出反事实结果。由于在这项研究中主要感兴趣的因果数值是被处理单位上的(平均)处理效应,我们的主要目标是预测反事实结果Y(0)mis,即被处理单位的未处理结果。由于交错采纳意味着W完全由采纳时间向量A决定,我们将Y(0)mis的后验预测分布写为:
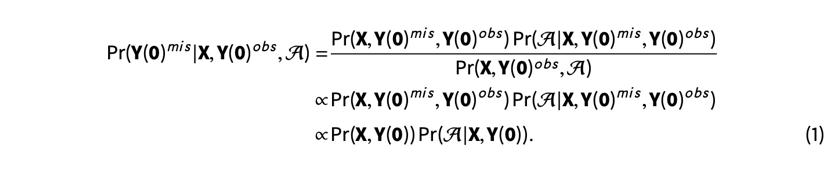
根据贝叶斯法则,等式(1)成立。因为它不包含缺失数据,我们通过去除分母作为归一化常数,得到了比例关系。因此,两个组成部分的概率,即基础的“科学”概率Pr(X,Y(0))和处理分配机制概率Pr(A|X,Y(0)),有助于预测反事实结果。
假设 3(个体化分配和正向性)。Pr(A|X,Y(0))= Pr(ai|Xi,Yi(0)) 和 0 < Pr(ai |Xi , Yi (0)) < 1 适用于所有单位i。
假设4(潜在忽略性)。 在给定观察到的处理前协变量Xi和潜在变量向量Ui = (ui1, ui2, ..., uiT)的条件下,分配机制对于每个单位i不依赖于任何缺失或观察到的未处理结果,即:
假设5(可行的数据提取)。 假设对于每个单位i,存在一个未观察到的协变量向量Ui,使得堆叠的(N×T)矩阵U=(U1,...,UN)可以用两个较低秩矩阵(r ≪min{N,T})近似表示,即U=Γ′F,其中F=(f1,...,fT)是一个a(r ×T)的因子矩阵,Γ=(γ1,...,γN)是一个(r ×N)的因子载荷矩阵。
2.3 后验预测推断
在假设4的条件下,我们暂时将U视为协变量的一部分,将X和U写在一起,记作X'。然后,我们得到Y(0)mis的后验预测分布:
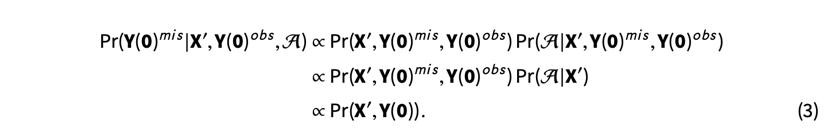
方程(3)表明潜在忽略性假设使得在反事实预测中处理分配机制可以被忽略,只要我们在X'的条件下进行。换句话说,在这些假设下,开发反事实预测分布的任务被简化为对Pr(X',Y(0))建模。我们需要这个技巧,因为在比较案例研究中,被处理的单位数量较少;因此,我们在数据中缺乏足够的采纳时间变化来对Pr(A|X')进行建模。为了对潜在的“科学”进行建模,我们进一步做出了交换性的假设:
假设6(可交换性)。 当U已知时,{(X',yit(c))}i=1,...,N; t=1,...,T 是一组可交换的随机变量序列;也就是说,{(X'it,yit(c))} 的联合分布在索引 it 的置换下是不变的。
根据德·芬内蒂定理(de Finetti 1963),给定一些参数及其先验分布,{(X',yit(c))} 可以被写成 i.i.d。注意,Pr(X',Y(0)) 等价于 Pr({(X',yit(c))}),现在我们可以将方程(3)中的 Y(0)mis 的后验预测分布写为:

三、建模与实现
在本节中,我们讨论似然函数和后验预测分布的建模策略。我们解释提出的动态多层次因子模型(DM-LFM),并讨论用于因子选择和模型搜索的贝叶斯收缩方法,以减少模型依赖性。
3.1 一个带有动态因子的多层次模型
假设7(函数形式)。单位 i = 1, . . . , N 在 t = 1, ..., T 时的未处理潜在结果被指定为:

图1以图形方式展示了模型。
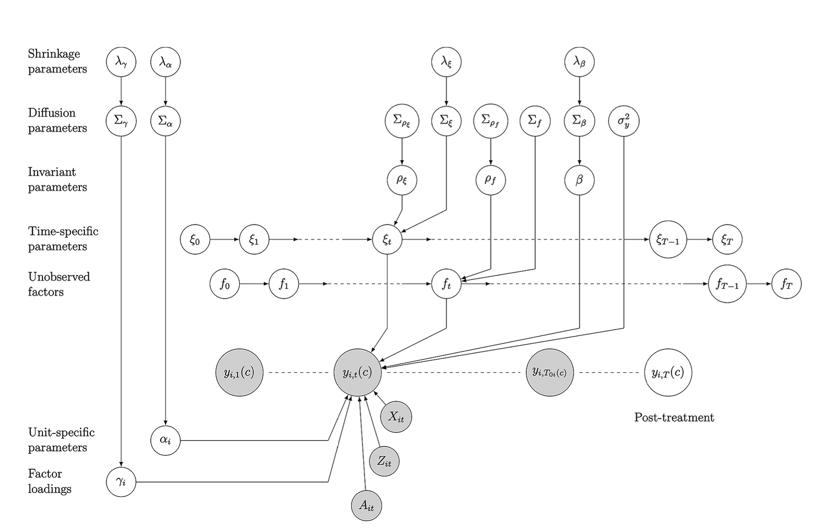
图1 动态多层次潜在因素模型图示
(阴影节点代表观测数据,包括未处理结果和协变量;
非阴影节点代表“缺失”数据和参数)
3.2 贝叶斯随机模型规范搜索
DM-LFM的一个优点是其高度的灵活性。然而,大量的规范选项对模型选择构成了挑战。贝叶斯随机模型搜索减少了模型错误规定的风险,并同时纳入了模型不确定性。我们使用收缩先验来选择潜在因素的数量,并决定是否以及如何包含协变量。
3.3实施DM-LFM模型
步骤1. 模型搜索和参数估计。我们采用贝叶斯收缩法规范和估计DM-FLM模型,从其后验分布中采样G次(不包括burn-in阶段的采样),获得参数的抽样θ(g) ∼π(θit|D), 其中D={(Xit,yit(c)obs):it ∈S0}是未处理观测的集合。由于贝叶斯收缩,π(θi t |D) 实际上是分布的混合。
步骤2:预测和整合。我们通过贝叶斯预测法,从后验预测分布中为每个受处理单位抽取时的反事实 yit(c)mis:
步骤3:推断和诊断。我们对每个受处理单位 i,推断其在处的因果效应 δit,通过汇总由 = (ai) − (c) 形成的经验后验分布 (empirical posterior distribution)δit,其中 g = 1,...,G。总结结果时,我们可以获得其后验均值、方差以及贝叶斯95%可信区间。我们可以通过汇总 δit 的后验分布抽样来推断其他估计量,比如 ATT,然后相应地汇总其后验分布。我们对主要参数后验分布的收敛和混合进行贝叶斯诊断测试,并发现在我们的模拟和实证研究中,MCMC算法收敛迅速,混合良好。
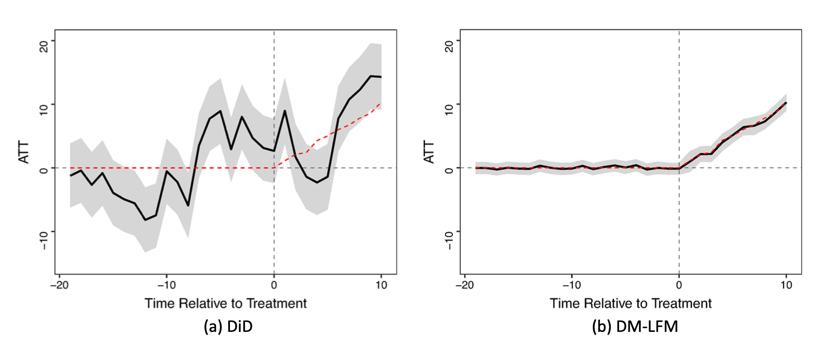
图2 估计的受处理单元的平均处理效应(ATT):
差异分析(DiD)与动态多层次潜在因子模型(DM-LFM)。上述图表展示了DiD和DM-LFM估计器的ATT估计及其95%可信区间,两者均采用贝叶斯马尔科夫链蒙特卡洛(MCMC)算法进行实现。红色虚线代表五个受治疗单元的真实ATT。
四、实证应用
4.1 德国统一的经济影响
首先,我们建立一个DM-LFM,其中包括ADH(2015)考虑的所有处理前时不变协变量,包括贸易开放度、通货膨胀率、产业份额、学校教育和投资率的治疗前平均值。我们考虑的初始模型是 yit (c) = Xi (β + ξt ) + ftγi +εit,其中Xi表示时间不变的协变量。为了与合成控制法保持一致,我们不包括单位固定效应或单位特定系数,但是包括了时间变化的系数。
然后,我们生成了一个GDP人均收入的经验后验分布,用于反事实情况下没有发生德国统一的情况下的西德。为了检查拟合效果,我们还计算了处理前年份其GDP人均收入的模型预测。在图5中,我们将合成控制法(a)的反事实预测与DM-LFM(b)的预测进行了比较,将95%的贝叶斯置信区间用灰色进行了着色。虚线垂直线表示1989年,即采用时间前1年。两种方法得出了类似的结果:除了统一后的前几年外,反事实情况下的西德的GDP人均收入都高于实际情况下的西德。

图5
最后,我们对处理效应进行推断。图6(a)和图6(b)分别报告了使用合成控制法和贝叶斯DM-LFM对西德统一效应的估计结果。对应的95%的置信区间在(b)中增加了。为了进一步加强我们的因果估计的可信度,我们进行了安慰剂测试,将1987年至1989年,即统一前3年,作为安慰剂期。图6(c)显示,在安慰剂期间的每个时间点的估计效应接近于0,这增强了我们对识别假设的信心。

图6
4.2 选举日注册与选民投票率
对于这一案例,我们设置了一个完整的DM-LFM模型。结果表明,至少有六个因子影响结果预测。与之相反,Gsynth只使用了一个留一交叉验证过程选择的两个因子。对于αi和ξt,截距在时间和空间维度都有变化,但协变量斜率的变化部分几乎被缩减为零。我们使用MCMC估计参数。与Xu(2017)的结果一致,我们发现这两个协变量在解释投票率的变化方面并不多。
然后,我们根据九个受处理州的后处理年份生成反事实结果的后验分布,根据这些结果估计EDR对选民投票率的影响。在图7中,我们报告了在相同采纳期内的ATT。比较从Gsynth和DM-LFM获得的点估计和不确定性估计,最明显的区别是贝叶斯95%置信区间比Gsynth的95%置信区间要窄得多。我们考虑这是因为我们的贝叶斯方法在个体反事实预测方面具有更好的预测性能。

图7
五、结论
什么时候适用 DM-LFM?它在什么情况下比现有方法更有优势?表格2总结了 DM-LFM 与 DiD、合成控制法和 Gsynth 方法之间的特点进行了比较。总而言之,贝叶斯 DM-LFM 特别适用于比较性案例研究,尤其是当研究人员怀疑传统的“平行趋势”假设不太可能成立时;当存在多个处理单位时;当研究人员希望在平均或个体处理效应上获得易于解释的不确定性估计时;当有许多处理前协变量可用且它们与结果之间的关系复杂时;或当时间变化的混淆因素复杂和/或足够微妙,需要相对较多的因子来表示,或者某些因子相对较弱。贝叶斯方法的最大缺点是,在样本量较大时,它的计算成本比 Gsynth 等频率论方法要高。我们还发现,当控制单位过少或处理前时期的数量过小时(例如,T0 < 20),我们方法的频数特性是不令人满意的。
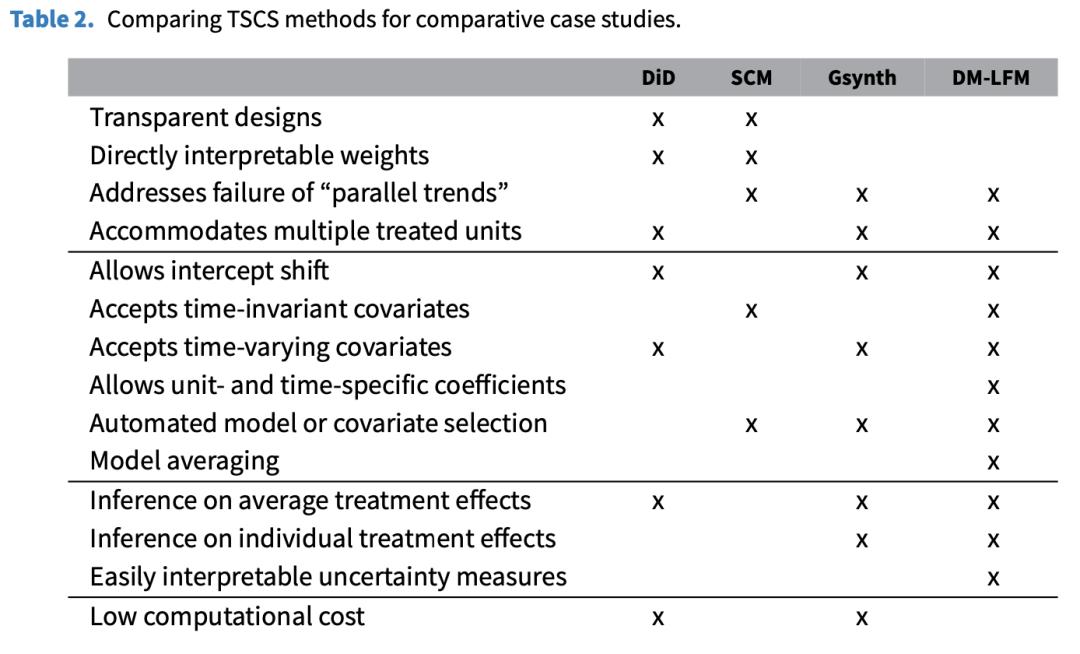
表2
由于不同方法的优势和劣势,我们建议研究人员在可能的情况下同时使用多种方法来交叉验证他们的发现。未来的研究应该考虑将该方法扩展到交错采纳之外的情况,同时对处理分配机制和响应曲面进行联合建模,并解决潜在的 SUTVA 违规问题,例如政策扩散和溢出效应。
编译 | 张译文
审核 | 李晶晶
终审 | Mono
©Political理论志
本文观点仅供参考,不代表Political理论志观点
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

