- +1
2024年的AI视频,究竟何去何从
原创 数字生命卡兹克 数字生命卡兹克
前几天在A16Z上看到了一篇文章:

看完了有一点感触,正好我自己也在各种不同的场合表达过过AI视频现状的看法和展望。
那我想,不如就写一篇文章,结合A16Z的观点,来一起聊聊这个话题。
2023为什么是AI视频突破的一年,AI视频还缺少什么,以及对2024年AI视频的展望。
2023是AI视频爆发的一年,从最开始时,只有Runway的Gen1和wonder studio勉强可看,但是基本不可用。
直到8月,RunwayGen2正式推出。
Nicolas Neubert做了《创世纪》AI预告片,我做了《流浪地球3》的AI预告片,AI生成式视频,正式走向大众眼前。
直到2024年初,已经有数十家AI视频公司成立,且推出产品,而更有不计其数的大厂的产品正在路上:比如Meta、Google、腾讯、字节、阿里、商汤等等等等。
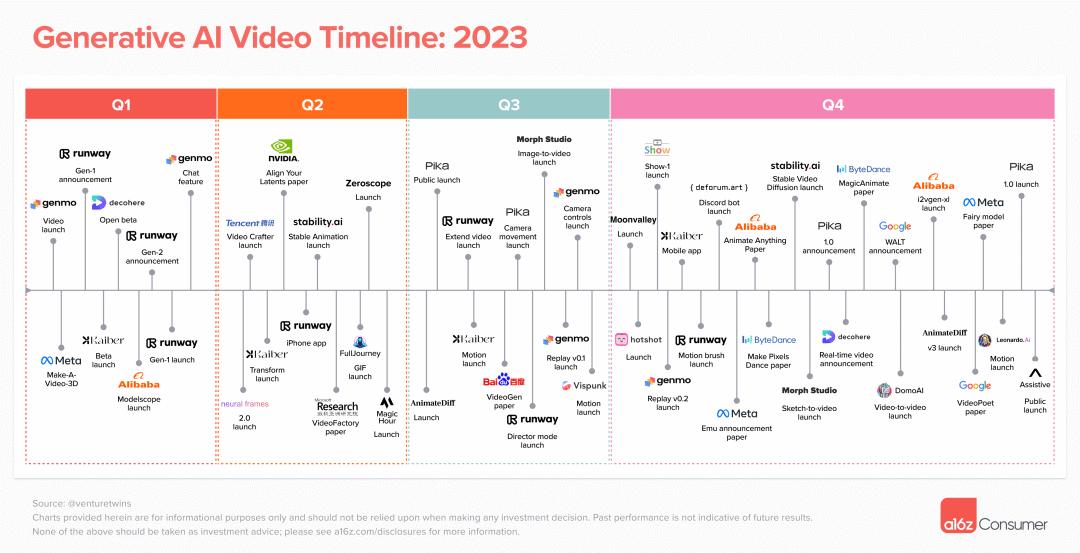
A16Z总结了一张图2023年关键节点图,我觉得总结的非常完整。
今年,我自己也整体体验了非常多的产品,除了最常用的Runway、PIKA、Pixverse之外,还有SVD、Genmo、Moonvalley、domo、Morph等等等等。太多了,也太卷了。
同样的,这里直接放A16Z总结的图。
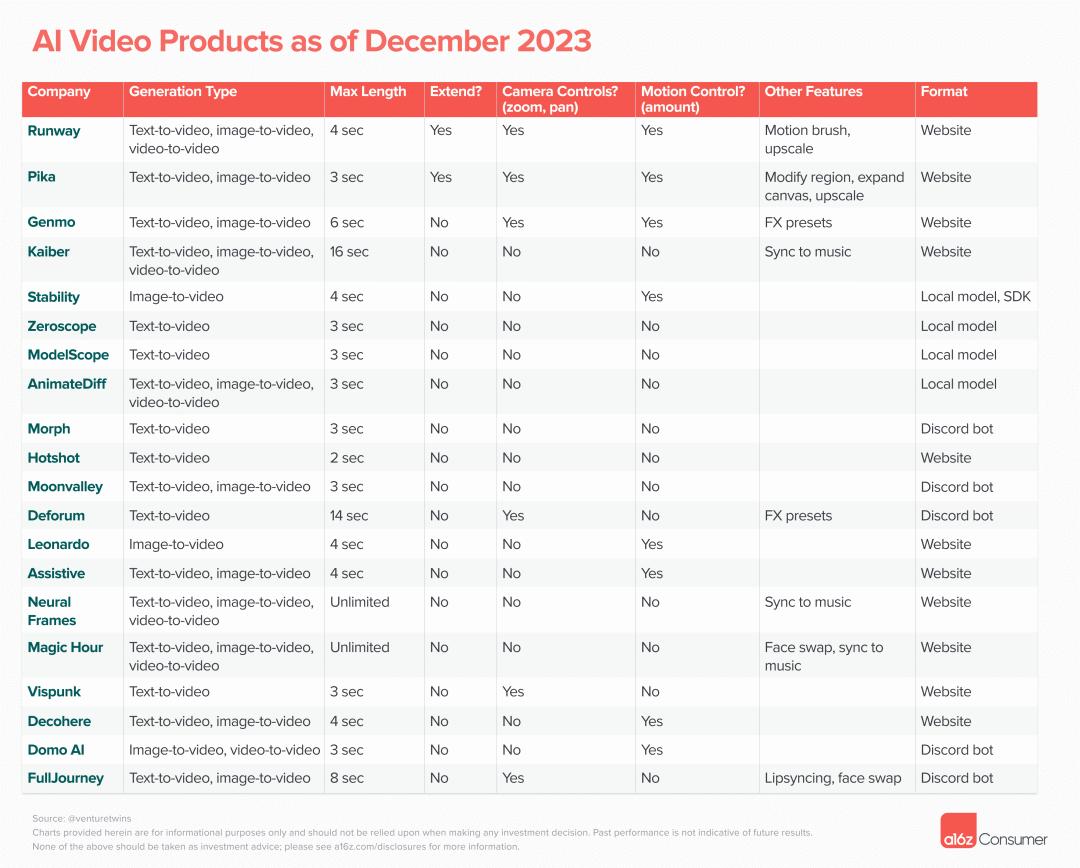
但是,绝大多数的产品都并不完善,在可控性上,只有为数不多的几家产品支持了,比如Runway的运动笔刷、比如PIKA的区域修改,大部分的产品都只有文生图和图生图,生成3~4秒的视频,然后就没了。
也可以从图中看出,大部分的公司,都是小公司,大厂的动作有点慢,不过2024年上半年,大厂的AI生成式视频产品,可能会是涌现式喷发。
但是不要忘了,AI视频的第一次正式全员亮相,是在去年八月。
距离今天,也仅仅过了6个月而已。
说说AI视频的问题。
很多人在交流的时候,经常问我一个问题是,你觉得AI生成式视频,距离终点的进度走到了多少?或者说,你觉得能全面给行业降负还有多久。
虽然我觉得这个问题太大太空,但是我每次还是会说,现在的进度大概是5%到10%的地步吧。
离你们心中那个饼,还有90%的路。
在我心中,有一个最核心的问题需要解决:
物理规律。
这个问题不解决,我不认为会对现在的影视行业会造成很大的冲击。
众所周知,视频里面,是包含大量的交互镜头的,人与人、人与物体、物体与物体的交互,等等。
比如我的玻璃杯子我放在空中,让他垂直落下,他应该掉在地上然后碎掉,或者高度不够的话,杯子会在地上弹起。
但是你让AI去做的话,你就会发现,变形变得你妈妈都不认识了。

或者一个人物戴着头盔转下头,头盔没了,脸也不要了。

这就是一个很离谱的事情,AI并不懂这个世界的物理规律,而一个不懂物理规律的视频,你认为他的上限能高到哪里去呢?
影视里,我们的最喜欢看的,是关系,是交互。
《海边的曼彻斯特》里有很多苦衷的两人之间的亲吻相拥。
《环太平洋》里机甲一拳将怪兽砸到海中的快感。
《复仇者联盟4》里钢铁侠那一个响指的浪漫。
没有这些,那一切都是空镜,一切都是转场,这样的镜头,怎么好看呢?
所以我们需要让AI视频,拥有物理引擎。
现在就我知道的,有两条路线,一条以Runway为代表,做世界模型;一条以商汤为代表,做3D。
先说世界模型。
Runway很久以前发了一个帖子,简单介绍了一下世界模型。

但是不要以为他就开始干了,他的原话是:
We are building a team to tackle those challenges. If you’re interested in joining this research effort, we’d love to hear from you.
翻译过来是:我们正在组建一个团队来应对这些挑战。如果您有兴趣加入这项研究工作,我们很乐意听取您的意见。
。。。
就,怎么说呢......
斯坦福有一个团队在我的印象中也在做,但是世界模型遇到的最大的问题是:数据收集的问题。
世界模型最麻烦的就是对物理现实的数据收集,人类的抽象能力很强,看到一个球,可能会识别出这是足球或者头;看到一个白色的物体,可能是桌子或是一堵墙。
但是现在大部分的视频数据,有大量的垃圾噪点,怎么能抽象的把大量的噪音抽离,只留关键的物理信息?这是一个非常坑的点。
自动驾驶其实就是这个方向的最落地的应用之一,但是自动驾驶要的数据,并不是那么多,来来回回就是道路、街道、人物、车子那些东西了,但是也搞了N久,现在离L4还很远。
当你要做生成式AI视频的通用世界模型的时候,那数据要的就不是那一丁点了。那是海量的数据。
物理规律我们能很容易想象到,但是对于AI来说,太难。难的不是后期的训练,而是前期的数据收集。
在我跟大佬们的交流中,他们说现在最痛苦的点是:
"人经历过千万年的进化,对于世界的常识,是藏在基因里的,会自动把一些冗余的信息以极快的速度,一步一步剔除直到只剩到最关键的信息,然后做做一些思考推断。但是机器没有,机器现在不懂抽象,所以需要人去做类似人类抽象化过程的学习算法,来抽离关键信息,收集视频数据。"
这个点非常痛苦。
这也是我对于所谓的AI视频的通用世界模型没有那么多信心的原因。
另一条路,就是AI 3D + AI视频。
商汤的一部分技术就是走的这条路。
他们曾经发了一篇论文:https://story2motion.github.io/

这个项目很有意思,从故事可以直接生成动作,非常连贯。
如果给一张图,能直接分离场景和主体,然后3D建模后,再用Story to motion生成轨迹和动作呢?
不需要什么世界模型,3D世界中的物理引擎,游戏行业都做了N多年了,非常成熟了。
只要能分离建模,那就没问题。
而AI 3D,我之前也写过一篇评测文章,现在正在冉冉升起的阶段:还没有那么成熟,但是按照现在这卷的速度,AI 3D,可能要不了半年,就能达到MJ的V4的程度。
当AI 3D和AI视频结合,那就是王炸。
所以我也能理解为什么MJ给自己定的星辰大海是AI视频,但在做AI视频之前,先从英伟达挖了一个专门搞3D的大佬去做AI 3D。
当然,这里面也有很多坑,3D建模的精度问题、贴图问题、骨骼问题、渲染问题等等。不过相比世界模型,我觉得这玩意的难度,还是小不少的。
总结一下,AI视频当然还有很多问题,比如一致性、比如时长、比如运动幅度、比如可控性等等。
但是我认为没有一个,像物理规律这样重要。
我期待后面大厂们加大筹码,疯狂开卷。
早一点解决这个问题。
早一点迎来,那超级的“颠覆时刻”。
我真的很想看到那一天。
原标题:《2024年的AI视频,究竟何去何从》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

