- +1
北大发起复现Sora,框架已搭,袁粒田永鸿领衔,AnimateDiff大神响应
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
重磅:
北大团队发起了一项Sora复现计划——Open Sora。

框架、实现细节已出:
初始团队一共13人:
带队的是北大信息工程学院助理教授、博导袁粒和北大计算机学院教授、博导田永鸿等人。
为什么发起这项计划?
因为资源有限,团队希望集结开源社区的力量,尽可能完成复现。

消息一出,就有人北大校友兼AnimateDiff贡献者等人即刻响应:
还有人表示可以提供高质量数据集:
所以,“国产版Sora”的新挑战者,就这么来了?
计划细节,已完成3个初步功能
首先,来看目前公布的技术细节——即团队打算如何复现Sora。
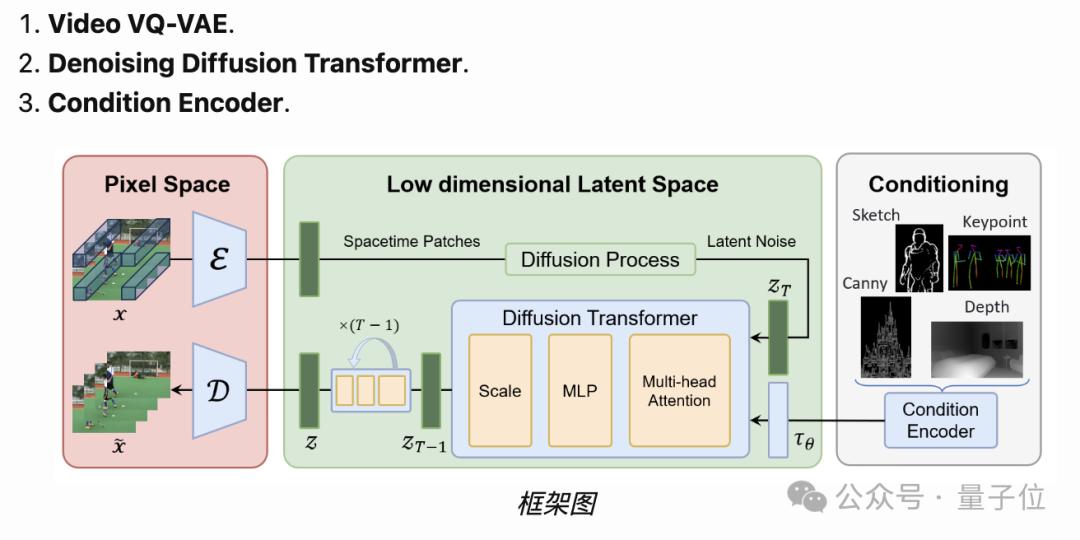
整体框架上,它将由三部分组成:
Video VQ-VAE
Denoising Diffusion Transformer(去噪扩散型Transformer)
Condition Encoder(条件编码器)
这和Sora技术报告的内容基本差不多。
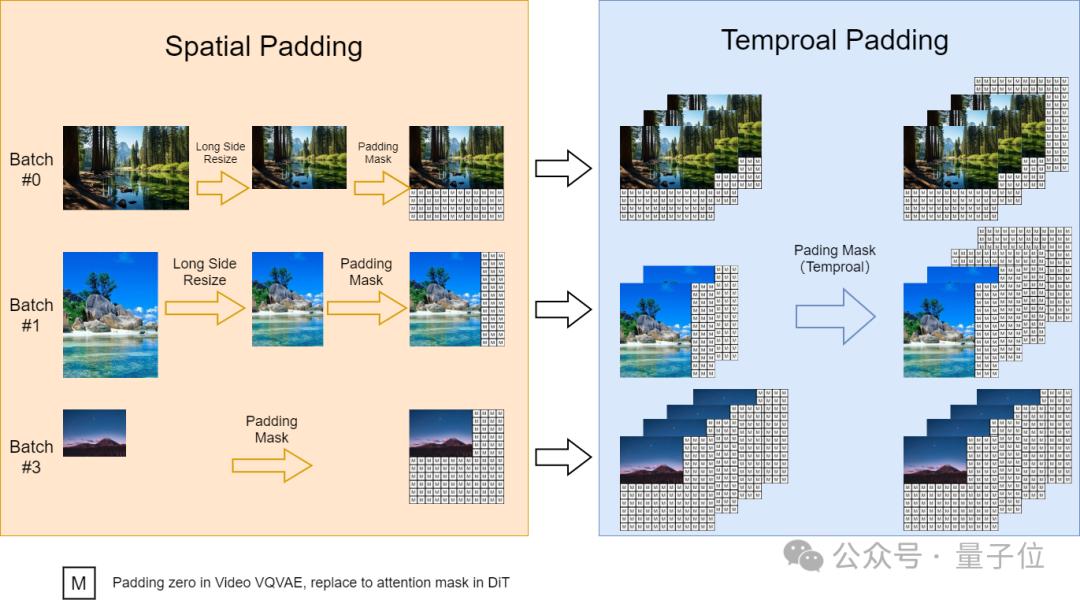
对于Sora视频的可变长宽比,团队通过参考上海AI Lab刚刚提出的FiT(Flexible Vision Transformer for Diffusion Model,即“升级版DiT”)实施一种动态掩码策略,从而在并行批量训练的同时保持灵活的长宽比。

具体来说, 我们将高分辨率视频在保持长宽比的同时下采样至最长边为256像素, 然后在右侧和底部用零填充至一致的256x256分辨率。这样便于videovae以批量编码视频, 以及便于扩散模型使用注意力掩码对批量潜变量进行去噪。
对于可变分辨率,团队则表示在推理过程中,尽管在固定的256x256分辨率上进行训练,,但使用位置插值来实现可变分辨率采样。
具体而言:
我们将可变分辨率噪声潜变量的位置索引从[0, seq_length-1]下调到[0, 255],以使其与预训练范围对齐。这种调整使得基于注意力的扩散模型能够处理更高分辨率的序列。对于可变时长,则使用VideoGPT中的Video VQ-VAE,,将视频压缩至潜在空间,支持这一功能。
同时,还要在扩展空间位置插值至时空维度,实现对可变时长视频的处理。
在此,主页也先给了两个demo,分别是10s视频重建和18s重建,分辨率分别为256x256和196x196:

这三个功能都已经初步实现。
相关的训练代码也已经在对应的仓库上上线:
成员介绍,目前的训练是在8个A100-80G上进行的(明显还远远不够),输入大小为8帧 128 128,大概需要1周时间才能生成类似ucf(一个视频数据集)的效果。
而从目前已经列出的9项to do事项来看,除了可变长宽比、可变分辨率和可变时长,动态掩码输入、在embeddings上添加类条件这两个任务也已完成。
未来要做的包括:
采样脚本
添加位置插值
在更高分辨率上微调Video-VQVAE
合并SiT
纳入更多条件
以及最重要的:使用更多数据和更多GPU进行训练

袁粒、田永鸿领衔
严格来说,Open Sora计划是北大-兔展AIGC联合实验室联合发起的。
领衔者之一袁粒,为北大信息工程学院助理教授、博导,去年获得福布斯30岁以下亚洲杰出人物榜单。

他分别在中国科学技术大学和新加坡国立大学获得本科和博士学位。
研究方向为深度视觉神经网络设计和多模态机器学习,代表性一作论文之一T2T-ViT被引次数1000+。
领衔者之二田永鸿,北京大学博雅特聘教授,博士生导师,IEEE、ACM等fellow,兼任鹏城实验室(深圳)人工智能研究中心副主任,曾任中科院计算所助理研究员、美国明尼苏达大学访问教授。

从目前公布的团队名单来看,其余成员大部分为硕士生。
包括袁粒课题组的林彬,他曾多次以一作或共同一作身份参与了“北大版多模态MoE模型”MoE-LLaVA、Video-LLaVA和多模态对齐框架LanguageBind(入选ICLR 2024)等工作。
兔展这边,参与者包括兔展智能创始人、董事长兼CEO董少灵(他也是北大校友)。
完整名单:

谁能率先发布中文版Sora?
相比ChatGPT,引爆文生视频赛道的Sora研发难度显然更大。
谁能夺得Sora中文版的首发权,目前留给公众的是一个大大的问号。
在这之中,传闻最大的是字节。
今年2月初,张楠辞去抖音集团CEO一职,转而负责剪映,就引发了外界猜测。
很快,一款叫做“Boximator”的视频生成模型浮出水面。
它基于PixelDance和ModelScope两个之前的成果上完成训练。
不过,很快字节就辟谣这不是“字节版sora”:
它的效果离Sora还有很大差距,暂时不具备落地条件,并且至少还需2-3个月才能上线demo给大家测试。
但,风声并未就此平息。
去年11月,字节剪映悄悄上线了一个AI绘画工具“Dreamina”,大家的评价还不错。
现在,又有消息称:
Dreamina即将上线类似sora的视频生成功能(目前在内测)。

不知道,这一次是不是字节亮出的大招呢?
Open Sora项目主页:
https://pku-yuangroup.github.io/Open-Sora-Plan/blog_cn.html
https://github.com/PKU-YuanGroup/Open-Sora-Plan
— 完 —
科技前沿进展日日相见 ~
原标题:《北大发起复现Sora,框架已搭!袁粒田永鸿领衔,AnimateDiff大神响应》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

