- +1
美国AI芯片公司“赢”大模型?Samba-CoE v0.2超过多个业界知名对手
原创 亲爱的数据 原创:谭婧
2024年第一季度的尾巴,3月29日。
有一张发自厂商的喜报截图,
低调地在微信群之间转发。
或早或晚间,贾扬清在推特转发并点评此事。
细心的人很难不关注:
一家低调的AI芯片公司,
居然做了一个这么好的大语言模型。
那须得边挖边聊了。

喜报来自一家美国AI芯片初创公司:SambaNova。
从名字上看,Nova是新的恒星,
Samba就是“忘情桑巴舞”的那个桑巴。
那种淹没在鼓点和节奏里的舞蹈。
这让SambaNova这个名字听上去就能感受热情洋溢,干劲十足。
现在的AI世界,开源闭源一片欣欣向荣。
谁会是下一颗新星?
无论开源赢,还是闭源赢,都是AI芯片公司赢。
于是,AI芯片公司重金砸万亿参数模型,
一点毛病没有。
按着这个逻辑,回看中国,
同时拥有万亿参数大模型和AI芯片的公司,有哪几家?
这个问题很难回答,
因为万亿参数大模型就算在炼,也是高度保密的状态。
这个问题也不难回答,
玩家极其之少。
AI芯片的门槛很高,万亿参数的门槛也很高。
华为算是玩家之一,
但到底有没有炼出万亿参数大模型还是个未知数。
也许藏而不露,
也许还在奋斗。
不过,从过往信息来看,
华为公司倒是有一篇万亿参数大模型的论文很出名:
《PANGU(盘古)-Σ:基于稀疏异构计算的万亿参数语言模》。
研究归研究,发布归发布,
学术论文和正式推出万亿参数模型是两件事情。
SambaNova这家公司在2024年2月发布Samba-1(桑巴一号)。
开源模型,一万亿参数。
该模型与其 SN40L 芯片集成以提高性能。
SambaNova官网主页最显眼的地方写着:
Samba-1: One Trillion Parameters, One Model, One Platform

芯片公司这样说,翻译过来就一句话:
打法很明确,AI全家桶。
华为在AI战场上也是这个的打法。
看起来确实是竞争对手。
甚且,这家公司挺擅长乘胜追击。
有了Samba-1开源模型,他们并未止步。
成果就是于2024年3月29日,
推出的MoE闭源大模型,
Samba-CoE v0.2。
公司宣称:
“Samba-CoE v0.2模型运行速度惊人,
可达每秒 330 个标记词元(token),
超越了众多业界知名竞争对手的模型,
其中包括刚刚发布的Databricks DBRX、
MistralAI公司的 Mixtral-8x7B,
以及埃隆·马斯克旗下xAI公司的Grok-1 等。”

CoE就是Composition of Experts ,
目前流行的是MoE,Mixture of Experts。
看上去,CoE是MoE这种思路上的一种前进和创新。
对这种方法,还有一种粗暴的总结,
“开源模型的集成与模型合并”。
或者说,将多个小型“专家”模型聚合成一个大型解决方案,
充当单个大型模型。
既然“专家多”那么就可以横跨不同专业领域,
拥有更多更广泛的知识、且有更高精度,
以及让多模态锦上添花。
可以看到,官宣中提到的相比较的三个模型可都是开源模型。
拿闭源比较开源,有人发问了:
“为什么要将闭源模型与开源模型进行比较?”
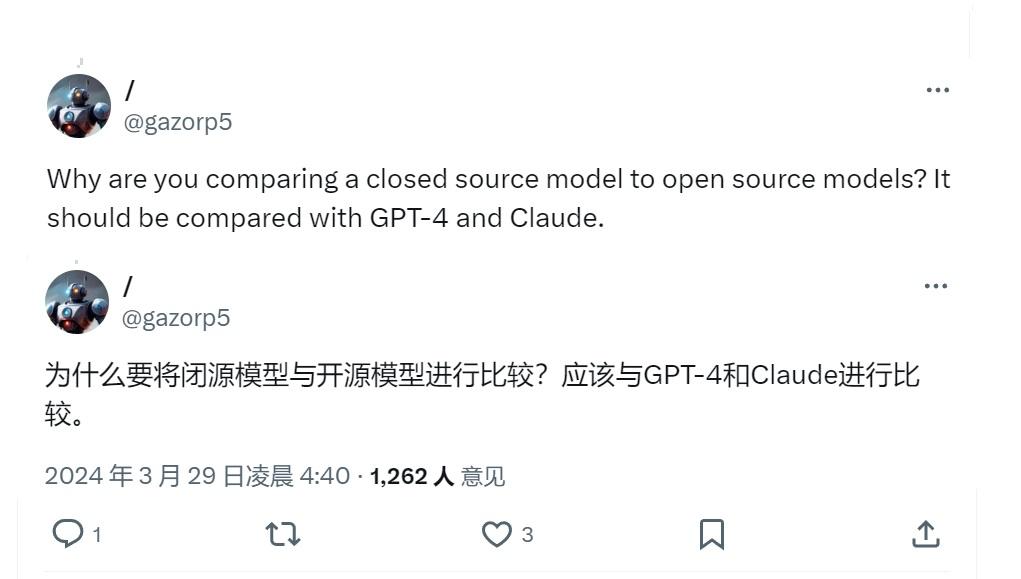
推特上这位网友的疑问,其实反映了目前现状,
即闭源大模型和开源大模型之间竞争不可回避。
闭源模型是背靠充足商业资源的“富二代”,
但大厂主导开源的模型也越来越多。
在谭老师我看来,
以现在大模型知识的深度和广度,简单问些个问题就当做测试的方法,
实在是很难得出什么可靠的结论。
若就是测着玩,那就当我没说。
很高兴看到市面上的开源模型百花齐放,
各有擅长,时不时还领先。
人们很快就能想到,
如果能“博采众长”该多好。
这真是一个好办法,
只是没想到,
这一点竟然被SambaNova实现了。

SambaNova没有把开源模型照搬(抄)过来,而是用得很巧妙。
另外,公司的“冲刺心路历程”,
也透露出架构设计的一些情况:
“在 Samba-CoE v0.2 中,用了下一个 Samba-1 版本的子集,并迭代了将这些专家组合在一起的不同方式,以实现最高性能。我们在AlpacaEval 排行榜上不断攀升,在通用基准测试中超越了所有最新的开源模型。”
Samba-CoE v0.2 用到了自家的开源模型,
又以专家组合(CoE)的方法打开一个新玩法。
开源模型Samba-1 使用56 个生成式开源 AI 模型的组合,
包括文本转 SQL、数学推理等针对很有难度的任务的特长专家。
这些专家模型均基于大型语言模型 Llama-2 进行构建或微调,
确实展现了 Samba-1 在利用现有模型优势上的巧思。
值得注意的是,这些模型经过单独训练,然后经过优化以协同工作。
SambaNova 联合创始人兼首席执行官
Rodrigo Liang在接受采访时表示:
“模型具有迭代性、可扩展性且易于更新,
为我们的客户提供了在集成新模型时可以进行调整的空间。”

还有描述是:
向 GPT-4这样的大模型提出的请求,只会沿着一个方向流动,
而向 Samba-1 提出的请求则会根据客户指定的规则和策略,
选择在56个方向中的一个方向流动。
56个方向就是Samba-1所包含的 56 个模型中的一个。
我翻看了一些资料,
除了模型结构设计本身,
关键组件路由器(Router)上也有绝活。
目前关于路由器的创新比较多。
简单说来,SambaNova 的处理思路是,
能动态地路由到一个或多个专家,
让它们协同发挥作用,如同单个模型一般工作。
这话就好比有一定规模的团队,队友团结一心,如同一个人在工作。
一位高校博导告诉我:
“在MoE的方法里,路由器是关键技术,
涉及到负载,涉及到模型的泛化能力。
不同的路由器导致模型的能力也不一样。
现在也有很多相关的创新工作在做。”

MoE的调度逻辑和方法非常重要。
这点也在一位百度云的技术高管(匿名)那里得到印证。
他告诉我:
“对于百度来说,肯定比较关注MoE。
比如,MoE从怎么训练和怎么调度这个角度找到一个balance(平衡)。
至于你说GPT-4它到底是不是MoE的这个结构?
虽然推测仅是传闻,但我依然有理由相信GPT4确实很像是MoE的表现。
它的性能和能力达到了一个还不错的状态。
有这样一种判断,未来会是少量几个大模型,
多个行业大模型和一大堆的小模型一起(合作),
这个结构要想把它统一起来的话,
要有一个比较好的调度逻辑。
而现在看来,MoE这个家伙还不错。”
全球进展如此之快,仅仅几个月后,出来一个叫CoE的家伙。
除了调度之外,
我认为还有几件事也很重要:
第一,到底要什么样的专家?
第二,需要人为区分专家吗?
第三,专家数量到底多少为好?
从前阿里巴巴技术副总裁,
leptonAI创始人贾扬清的推特里面能找到一些线索,
他的推特总是信息量很大。
这次对SambaNova的评价给得也很客观,也很认可这种思路:
“理想情况下,每个领域都应该有自己的专家来给出更垂直、更有针对性的答案。这与Mixtral MoE 方法相关但略有不同,在这种情况下,个体专家更具计算性,而不是特定领域。”

从上图中不难发现,
贾扬清的推特被一位名叫安东·麦格内尔(Anton McGonnell)的人转发了,
这位是谁呢?
他是SambaNova公司的软件产品主管,
从芯片到模型平台有很多工作要设计。
他的推特中也可见一些线索,由此也带出了基础软件方面的优势:
只能,只能,只能
重要的词说三遍,
只能在SambaNova的系统上实现。

而安东·麦格内尔的话语中透露出,
软硬一体化的设计,
更有利于他家这种“复杂路由器”发挥出作用。
毕竟,软硬件的融合协同威力巨大。
这也就聊到了SambaNova的基础软件。
SambaNova 全自研和AI芯片配套的基础软件。
比如,SambaNova Suite,
让用户自定义和部署模型,并且方便模型在云上使用。
再比如,DataScale 系统
和英伟达的 DGX 平台是对标竞品。
当然,华为昇腾也有大模型整体解决的方案。
最后,再聊聊AI芯片。
一般来说,模型由Pytorch,TensorFlow等上层AI框架表达实现,
AI算法工程师也只会和这个层面打交道,
绝大部分的人并不关心底层如何工作。
我补充一些,国内专家平时给我讲的情况:
第一,Transformer算子化。
算子对AI芯片来说,非常重要,
高效算子的实现AI芯片的一个重要挑战。
各种不同的AI芯片都有自己的硬件架构和特性,
需要有针对性的优化。
针对特定芯片架构对算子进行优化,以提高性能和降低功耗。
所以,能看到AI芯片的公司需要请很多工程师手写算子。
芯片是硬件,算子是软件,
算子定义了芯片可执行的操作。
特定算子,有特定操作。
比如,加法、减法、乘法和除法都是算子。
AI常用操作还包括,卷积和矩阵乘法等,
那么倒不如请芯片公司的工程师为卷积和矩阵乘法操作编写专门的算子,
以提高性能和降低功耗。
Transformer已是主流模型,
就好像乐高积木里的“房顶子”,
玩任何建筑类的乐高搭建都难免要用“房顶子”,
不如整体设计,只要盖房子就拿过来用,
Transformer算子化也是这个道理。
第二,超大内存。
这个超大,看要达到什么程度。
反正AI 模型越来越大,对内存的需求也更贪婪。
大模型训练需要将大量数据加载到内存中进行处理。
大模型推理也需要将模型参数和中间结果加载到内存中进行计算。
例如,SambaNova的DataScale 系统提供高达 1.5TB 的内存容量。
第三,数据流处理器编译器
这个神器是专门针对数据流处理器(dataflow processor)的编译器。
可以将数据流图(dataflow graph)直接映射到硬件上,
从而提高并行性和效率。
想做到好,得下功夫。
但这一块的技术深度甚深,我也难窥见其貌,
如果有这方面的专家老师欢迎联系我,
还望不吝赐教。
一个AI芯片的性能到底行不,那要有团队在上面试一下性能才有发言权。
那这个团队就是贾扬清为创始人的团队,LeptonAI。
合作的消息由SambaNova官网释放:

“接下来,我们将通过合作伙伴 Lepton.ai ,
提供功能更强大的新型通用聊天
LLM - Samba CoE v0.3 的试用版本。
我们将在下个月发布的下一个 Samba-1 版本中集成 Samba CoE v0.3。
每秒处理 330 个标记词元(Token)仅仅是开始,我们将继续突破极限,
提高准确性、广度和速度,证明‘组合专家 (CoE)’架构是企业 AI 的未来……
模型很能打,芯片也给力。
SambaNova是从AI芯片出发雄心勃勃的玩家。
战场上,从小胜变大胜,从量变到质变。
SambaNova成立于 2017 年,
早期就算是芯片初创企业中的佼佼者。
更是四年后创下美国半导体初创公司
有史以来规模最大的一轮融资记录,6.76 亿美元,
这个融资金额是几乎是其他美国半导体初创公司的3-4 倍。
SambaNova公司客户神秘了很多年,
直到23年的时候才爆出,
看看超算客户名单,也能理解藏而不露的原因了。
2023年3月,SambaNova被日本RIKEN科学研究所选中,
为富岳超级计算机提供DataScale系统,用于研究。
2023 年 5 月,被劳伦斯利弗莫尔国家实验室 (LLNL)
集成到实验室的超级计算设施中,以提高其认知模拟能力。
目前的模型训练的范式非常强地以来高性能计算的硬件,
如此好的客户,不能不说公司对AI计算的理解很深。
2023 年 6 月,咨询巨头埃森哲也在数据中心部署其计算平台产品。
还有一句来自背书者的评论,透露了客户的需求趋势:
“ 客户正在寻找包括支持 1T 参数模型的全栈解决方案。
SambaNova 创新芯片的集成意味着企业可以在只有一个机架上运行,
并比其他类似规模的模型提高效率。”
2023年9月的时候,
SambaNova的AI芯片SN40L 可以服务 5 万亿个参数模型,
单个系统节点上的序列长度可能超过 256k+。
2024年3月29日,Samba-CoE v0.2模型亮出成绩单。
从最初的关键词:专注于定制的AI芯片,
到现在的关键词:万亿参数AI模型领航人,AI芯片厂商,AI全家桶玩家。
创业公司,险境求生,
芯片对芯片,它的竞争对手还包括Groq。
而且最终还要和英伟达这个庞然大物正面竞争。
好消息是SambaNova的打法很能给客户省钱。
虽然公司已经烧了很多钱,目前融资也超过了 11 亿美元。
不过,我还是由衷感慨,这又是一个硅谷美元堆上的好故事。
(完)
《我看见了风暴:人工智能基建革命》,
作者:谭婧

原标题:《美国AI芯片公司“赢”大模型?Samba-CoE v0.2超过多个业界知名对手》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

