- +1
IEEE PacificVis 2024 会议纪要——首日
原创 可视分析 可视分析
2024年4月24日上午,IEEE PacificVis 2024会议在日本东京庆应义塾大学三田校区北馆正式开幕。本次会议大会主席,来自庆应义塾大学的Issei Fujishiro教授主持了开幕式。本次PacificVis会议第一次设置了TVCG Track,131篇投稿中15篇被直接收录进入TVCG,录取率仅为11%,另有15篇被以major revision方式通过TVCG进行修改。此外,会议接收会议长文27篇,短文12篇,海报29篇,故事叙述竞赛入围作品6件。共有来自18个国家和地区的182位学者参会。
主旨报告:数据故事叙述的设计指导和人与人工智能合作
在开幕式后,香港科技大学的屈华民教授作了题为数据故事叙述创作的设计指导和人与人工智能合作(Design Guidelines and Human-AI Collaboration for Data Storytelling)的主旨报告。
在主旨报告中,屈老师首先讲述了数据故事叙述的流行性与普遍性,同时指出数据故事叙述的创作绝非易事,由此引出了两个有关数据故事叙述的研究目标:1)找到有效的数据故事叙述策略,2)帮助人创作有效的故事叙述作品。
屈老师针对两个研究目标分别介绍了一系列工作。对于探索有效的故事叙述策略的研究目标,屈老师首先介绍了针对数据动图开展调研,并从动画帧的帧内设计和帧间切换两个方面并给出了五个维度的设计空间的工作。随后,他介绍了在数据视频的创作上,从电影拍摄技巧受到启发,针对数据视频的情节设计,以及开场与结束的方式进行了不同角度的研究工作。

屈教授介绍数据视频情节的三个阶段。
针对如何助力人创作有效的数据故事,屈老师列出了已经开展的多项工作,包括在提高故事叙述创作效率的数据科学故事创作和体育故事创作,以及在提高故事创作创造力方面的文字动画生成与摄影学等一系列工作。
针对人与人工智能的合作,屈老师介绍了团队的最新工作,全面地分析总结了现有促进人与人工智能之间合作的工具。该工作将合作创作故事叙述的过程抽象为四个阶段,并且将人和AI的在这其中的角色分为了如图所示的四类。该工作还进一步深入分析了在每个阶段的合作模式,并发现了人和AI的合作创作故事叙述从人主导创作,到AI主导创作,再到混合创作的过程。
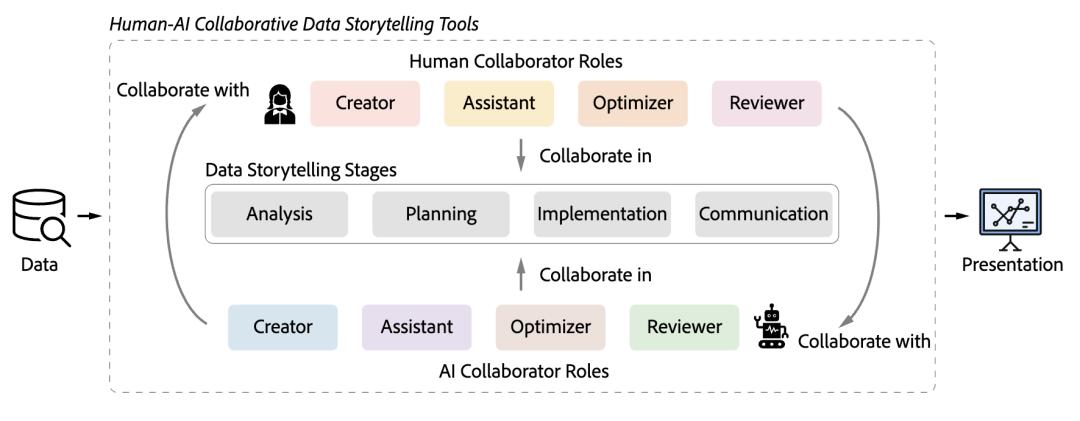
创作故事叙述的过程被分为了四个阶段,人和AI在其中可以担任四种不同的角色。
在主旨报告的结尾,屈老师特别指出,使用计算机帮助人们发挥创造力是一个具有巨大前景的方向。他今年在香港科技大学申请创办了艺术与机器创造力系(Division of Arts and Machine Creativity)。新系的创立基于近年来生成式AI在图片生成与视频生成上十分惊艳的进步,机器参与的艺术创作活动进入了一个新的时代。屈老师对艺术与机器创造力系的期望包含了机器创造力、机器复制的艺术实践、针对机器艺术的批判研究,和在机器艺术时代下的艺术管理等方面。在最后屈老师引用了Clarke第三定律总结了人与AI合作在艺术创作方面的巨大前景“任何足够先进的技术进步都是无异于魔法的”。
论文环节:人工智能与可视分析
下午的第一个论文报告环节包含5篇TVCG期刊轨论文和4篇会议轨论文。实验室李金城同学报告了TVCG期刊轨论文“PM-Vis: A Visual Analytics System for Tracing and Analyzing the Evolution of Pottery Motifs”。该工作为考古学家完成彩陶花纹演变追踪与分析提供可视分析方案。通过分解传统工作步骤,开展花纹外观、空间和时间关系联合分析以及原位注释等策略有效实现具有演变联系的花纹选择、演变序列识别以及发现与见解记录。该工作也受到不少考古领域的关注。

李金城同学介绍彩陶花纹演变分析工作PM-Vis。
随着量子计算的不断发展,量子神经网络(QNN)在过去几年取得了长足的进步。不过,与传统神经网络类似,专家们需要去了解模型中发生了什么,并对模型结果进行解释。来自新加坡管理大学的同学分享了他们的可视分析系统 VIOLET,通过新颖的可视化设计,解释了从输入数据转为量子状态,以及量子状态间的变化。来自布尔诺理工大学的研究者采用强化学习的方法为地图上的地点标签进行布局。传统上,这些标签的布局严重依赖手工,耗时耗力。同时,作为一个 NP-Hard 问题也难以找到传统算法解决。因此,研究者们采用多智能体的强化学习来解决这个问题。通过设定约束,如标签不能与边框重叠,也不能相互重叠等约束条件,算法能够很快得出最后的布局结果。来自加州大学戴维斯分校的研究者们通过图像文本对齐预训练模型,为大规模图像集自动设置标注文本。结合自动标注中的关键词,他们进一步为大规模图像浏览提供了聚类查找等功能。考虑到模型并不能完整地总结所有图像中可能涉及的特征,他们进一步结合了图像分割技术,强化修改图像的标注文本。为了应对人工智能系统可能导致的公平性问题,来自犹他大学的研究者设计了六个可视化组件以帮助对缺乏相关技术背景知识的群体针对人工智能的偏见性的理解。他们在商业公平性课程上进行了用户试验。针对缺少人工智能背景的商科学生研究相应的技术方法能否帮助用户理解。来自复旦大学的研究者采用图神经网络来理解用户在于可视分析系统进行交互时的意图。通过用户交互的历史记录,分析用户操作,并总结用户的探索故事。来自埃默里大学的研究者总结了不同的智能模型可视化的设计对于读者信任度的影响。研究者们最终总结了9中关于信任校准的常见形式,并给出了人工智能系统设计的建议。最后,来自加州大学戴维斯分校的研究者们报告了在异构框架中数据在不同硬件中转移的可视分析系统设计。考虑到数据转移在现代软件中是制约性能的重要部分,针对数据转移行为的分析能够帮助专家们更好地发现并优化工作流程中可能存在的性能问题。
论文环节:科学可视化与地理可视化
第二个论文报告环节共有1篇TVCG期刊轨论文和8篇会议轨论文。TVCG期刊轨论文来自波尔多大学,该工作使用动画在地图上展示预定路线所需的时间不确定性,以帮助用户了解由于道路上各类可能发生的意外情况,如路口的减速等。通过用户实验,研究者们证明了该方法能够帮助用户完成信息提取和简单推断问题。来自复旦大学的研究者针对自动驾驶的情景设计了针对性的可视分析工具。一方面,研究者通过场景图对自动驾驶实际情景进行建模,并提供多层次可视化视图,帮助专家全面理解、复现场景。另一方面,研究者们通过发掘极端情况下先进智能系统的缺陷,帮助专家打开系统决策的黑盒。通过可视分析系统,专家能够更好地理解智能系统决策行为,产生重要的见解。来自上海交通大学的研究者将情感融入历史研究,通过量化作品的情感,并与实际地图相结合,展现特定地点情感变化情况。从情感地理的角度揭示了城市的演变,这为研究城市历史和文学的人文研究者以及对历史遗迹知识感兴趣的公众提供高效的探索途径。
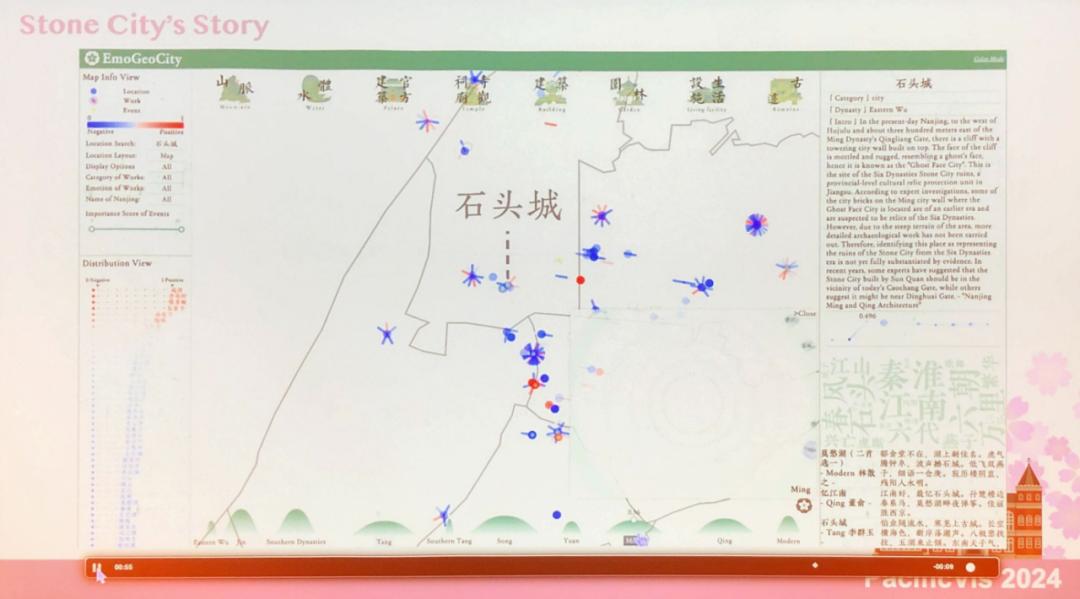
南京城在历史文献中情感变化的系统演示
来自斯图加特大学的研究者通过对酒店评论的语义分析,设计了ViSCitR分析系统,以帮助用户更加方便地进行对不同酒店进行比较,筛选出最适合的。科学可视化方面,来自海德堡大学的研究者与研究辛空间的数学家合作,完成了用于商空间和S3中基于光线投射方法的流场可视化交互系统。来自美国科学计算与成像研究所的研究者对基于 DNN 的拉格朗日流场可视化方法进行综合评估以及拓展。与原方法进行比较后发现,新的方法在计算速度与内存消耗上均有优势。来自阿卜杜拉国王科技大学提出了一种新的显微镜模拟系统,能够模拟复杂病毒的电子显微镜结果。基于模拟结果与真实结果的相似性,该方法能够被用于实际数据的降噪工作中。通过拉普拉斯金字塔进行自适应的信号拟合,来自圣母大学的研究者在不同尺度上利用多个小模型进行局部拟合,并优化了其中的数据传输和任务分配策略,设计了新颖的ECNR时变体数据高效压缩神经表示方法。通过与当前已有的算法进行比较,研究者们认为该方法具备很大的潜力。
可视化遇见人工智能研讨会
人工智能是本次会议的一大关注热点,会议前一日下午举行了可视化遇见人工智能研讨会 (Visualizaiton Meets AI Workshop)包含AI4VIS和VIS4AI两个部分。每个部分均包括一个受邀演讲和两个论文报告。
在AI4VIS部分,来自美国圣母大学的Chaoli Wang教授作了《关于科学可视化的生成式人工智能(Generative AI for Scientific Visualization)》的受邀演讲。他首先介绍了一个基于编码器-解码器的多层感知机框架CoordNet,可以统一地处理时间与空间超分辨率等数据生成任务和视角合成与环境光遮蔽预测等可视化生成任务。该方法利用SIREN激活函数,相比于ReLU,训练更加稳定,收敛更迅速。CoordNet在评估的绝大部分指标上优于传统方法和其他深度学习方法。其中,在视角合成任务上,CoordNet方法解决了其他方法恢复结果模糊的问题。CoordNet的结果能达到更高的分辨率,且支持参数空间的探索,但是需要更长的时间训练。随后Wang教授介绍了基于NeRF和TensorNeRF的方法,ViSNeRF,支持对时间、等值面、传递函数和模拟参数的参数空间探索。该模型以渲染参数为输入,使用了因式分解技术来实现快速的训练和更好的图像合成效果。该方法还使用了由稀疏到精密的特征网格等方法来改进优化速度。在不同数据集下,针对不同视角体数据渲染结果预测、等值面插值、传递函数插值、不同模拟参数插值等任务,ViSNeRF达到了最好的预测质量,且训练时间最少,模型最小。最后,Wang教授还分享了关于SORA等新技术对于科学可视化的影响和对其的思考见解。

Chaoli Wang教授介绍VisNeRF方法。
加泰罗尼亚科技大学的Pere Pau Vázquez讲解了他们的工作《Are LLMs ready for Visualization?》。该工作关心现有的大语言模型是否能精确生成可视化且针对不同情况都能稳定。他们选取了24种代表性可视化,在不同大语言模型上进行测试。测试条件包括使用简单提示词、使用可视化库的提示词,和使用修改指定可视化编码的提示词三类。结果显示GPT-4生成可视化图表的准确率高于预期,接近80%,但是在修改可视化参数,如改变散点图的图元形状时容易出错。
来自首尔国立大学的Jinhwa Jang介绍了帮助市场分析师探索网络上用户评论的可视分析工作,其通过计算用户评论的词向量、主题、情感和文字总结,使用投影图、词云、对比柱状图等图表帮助专家快速分析用户评论的分布。

Vázquez介绍大语言模型生成可视化实验的设计
第二部分的受邀报告讲者是来自复旦大学的陈思明教授。他首先介绍了关于自动驾驶的可视评估方法,通过提供时间和空间的背景信息以及失败场景下的分类和特征,帮助用户理解模型在不同驾驶场景下的感知、思考和行动的表现。随后,他介绍了对于自动驾驶模型的深度分析方法,通过提取模型参数,帮助用户从对象层级和图像层级探索模型感知到的车辆自身状态、其他交通参与者状态等内容,从而发现模型检测错误的部分,深入细节进行分析。通过Transformer架构进行自然语言问答的算法逐渐普及,如何提升人工智能研究者和公众对于Transformer模型的理解至关重要。对于人工智能研究者,陈教授介绍了针对BERT模型的可视分析方法VEQA,提取重要的单词和网络层,并生成语义树。他提出使用流图展示模型的提取者部分和读者部分的排序差异,并使用树视图来展示词语在不同层的关系。同时,他还介绍了帮助Transformer教学的可视化方法TransforLearn。对于人工智能如何支持可视化,他分别介绍了基于LSTM和基于大语言模型对可视分析过程进行推荐的工作。针对在公众用户在博物馆使用可视分析系统探索数据的情景,他介绍了如何基于其他用户的使用记录,向新用户推荐他们可能需要的交互操作。而为了基于交互语义提供更准确的交互推荐,他提出使用大语言模型增强可视分析的方法LEVA,并介绍了相应的代码工具。通过在代码中定义特定结构的对象,告知大语言模型系统的视图和交互信息,LEVA可以生成针对可视分析系统的用户教程,并通过聊天界面和系统标注向用户推荐数据洞见。LEVA还能自动生成数据分析的报告对探索过程进行总结。
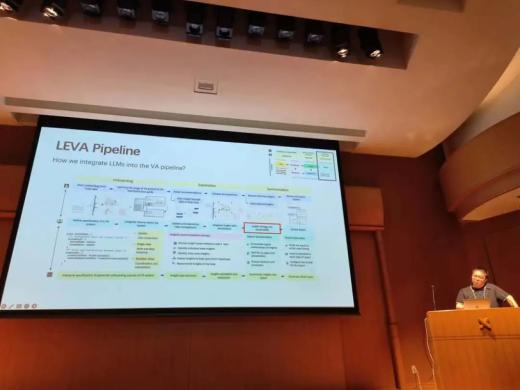
陈思明教授介绍LEVA框架图。
在论文报告环节,来自首尔国立大学的同学介绍了持续学习分类器在不同任务转换时可能因类别定义变化出现准确率下降的问题,他们设计了不同任务的转换效率热力图、任务对与分类标签对的准确率图元以及训练数据项层级的预测结果变化三个层级帮助专家分析任务转换如何影响分类器性能。另一个工作来自中国科学院计算机网络信息中心,基于智能体在环境中不同位置的决策概率,设计了分布散点图和位置变化流图,支持专家对深度强化学习训练产生的序列数据进行可视分析,该方法支持专家交互选择环境位置并定义子任务,从而将人的知识应用于强化学习的训练过程。
原标题:《IEEE PacificVis 2024 会议纪要 - 首日》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

