- +1
昨天一个网站的更新,让外国人集体断网6小时
差友们,昨晚你们网速足够快的话,应该已经见证了一场互联网大戏——
Cloudflare崩了。
这可不是一般的崩,是那种能让半个地球互联网一起陪葬的崩。
刚开始大伙儿还一脸懵逼,有人发现推特登不上了,好不容易登上去了吧,啥也刷不出来。
同样的,ChatGPT也寄了,设计工具Canva也打不开,国外兄弟正在打LOL和瓦罗兰特的排位呢,直接连不上服务器了。。。
更离谱的是,当所有人想去DownDetector查查到底哪个网站崩了的时候,发现DownDetector也崩了。
好好好,想看热闹,结果自己成了热闹。
差评君昨天也亲身经历了这场灾难。
我正在ProductHunt给个App投票呢(因为投了给我打五折),结果死活点不动。后来刷朋友圈吧,又发现之前给大家推荐的网页红警也进不去了。
这一切的始作俑者,就是Cloudflare。
大部分挂掉的网页都出现了Error500,清清楚楚写着Cloudflare炸了。
只能说一家公司打个喷嚏,全世界感冒。
眼看社交媒体不能逛,ChatGPT不能聊,游戏不能打,全球网友开始了集体哀嚎。
有人哭诉:就因为Cloudflare,我的AI女友都联系不上了。。。
——怎么和美国人形容Cloudflare崩了有多严重?
——你们没汉堡吃了(*点餐机崩了)
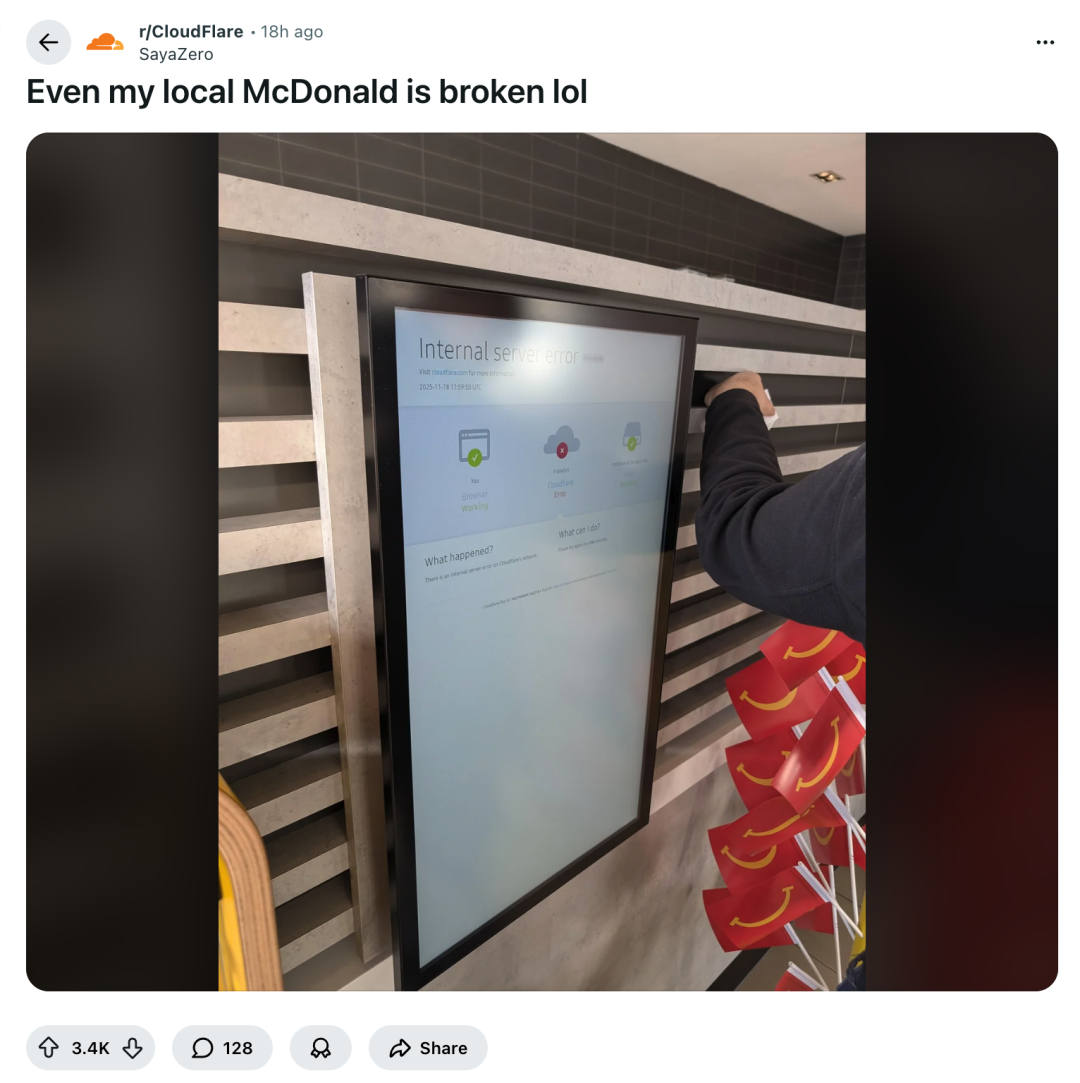
还有人截了一张动图,展示了Cloudflare服务中断后的互联网世界。。。

甚至有人发现了新大陆,Cloudflare崩了之后我的生活全是蓝天白云。

就在这一片哀嚎声中,有个叫MrShibolet的用户发的推特,突然火了:
Cloudflare入职第一天,推送了点更新,下午准备休息咯✌️
配图里的他站在Cloudflare前台前,摆着不太聪明的姿势,双手扶着衣边,倔强的嘴角微微上扬。
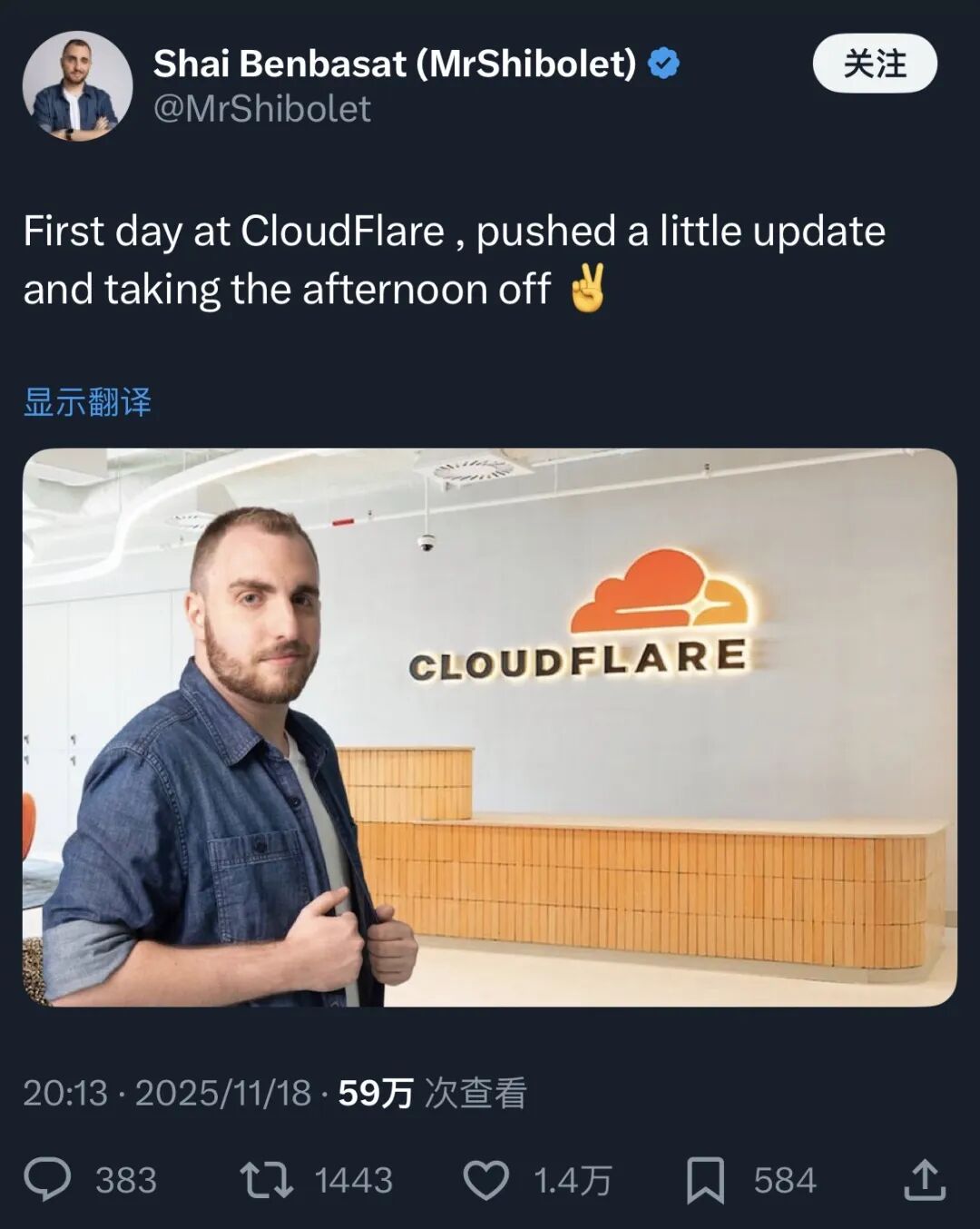
这条推特一下传开了,60万次阅读,所有人都在说:兄弟第一天上班就是最后一天。。。
但其实,这哥们是整活的。
上个月AWS崩的时候,他也发过一模一样的推文,这次无非是把名字换成了Cloudflare。
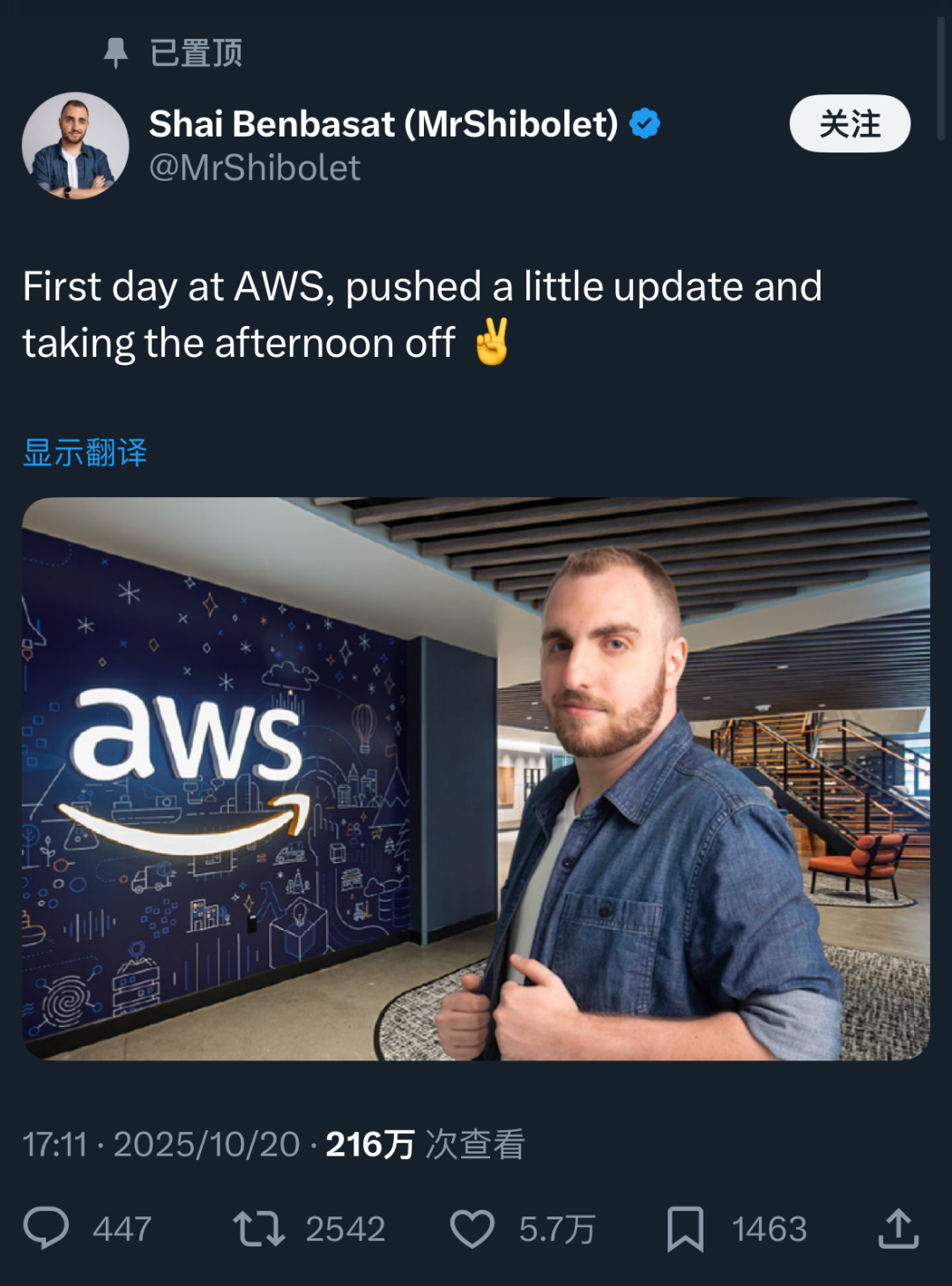
行了,现在你应该知道昨晚的互联网有多热闹了。。。
到这肯定有人好奇,Cloudflare到底是个啥?凭啥它崩了,这么多网站都得跟着炸?
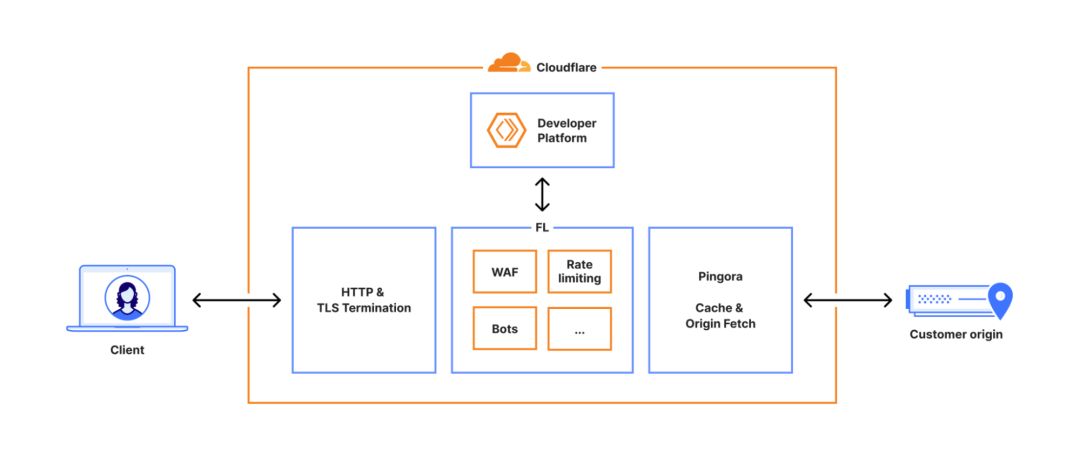
简单说,Cloudflare就像是互联网的物业公司,负责网站的安全、加速、流量管理。
主要业务包括CDN(内容分发网络)、DDoS防护、Web应用防火墙、DNS服务等等。
正常情况下,你访问一个网站,就是你的浏览器直接连到网站服务器。但如果网站用了Cloudflare,流程就变成了:
你的浏览器→Cloudflare→网站服务器→Cloudflare→返回给你。
你说绕这么大圈子图个啥呢?
图的是:又快又稳。
Cloudflare在全球铺了330多个数据中心,当你访问用了Cloudflare的网站时,它会自动把你导向离你最近的那个数据中心,这样访问速度会快很多。
这就好比你网购,商家从本地仓发货,当然比外地的总仓要快很多。
除了快,Cloudflare还给网站当保镖,防DDoS攻击、管理机器人爬虫、缓存内容减轻源服务器压力。
说白了,网站用了Cloudflare,就相当于小区请了一个五星级物业。
有外人来了,他先站在门口验个身份,填个来访记录,把可疑的人拦在外面,确认是正经访客了再给他们套个五速鞋,加速访问。
但问题也来了——
一旦这个物业系统崩了,保安集体脑子宕机,那所有人都进不了小区——
想访问网站的人,全被Cloudflare拦在了门外。
按理说,一个搞互联网基础设施的公司,不应该轻易崩掉。
可一旦它崩了,那就是真正的牵一发动全身,崩一屁臭整屋。

所以,什么情况下会崩?
Cloudflare自己发了个事故报告,我看完了只有一个感觉:这也能崩?
咱简单聊一下。
Cloudflare有个功能叫BotManagement(机器人管理),它不光能识别出恶意机器人bot,还能给每个访问者打分。

网站管理员可以自己定规矩:你这访客素质得到多少分,才配来我家玩。
比如电商网站可能设置70分以上才能下单,防止抢购机器人;新闻网站估计30分就行,毕竟得让搜索引擎爬虫进来。

这个打分系统需要一个特征文件,里面记录了各种判断标准,一般有60种。
访问速度异常快?浏览器信息很奇怪?扣分!
IP地址很可疑?行为模式像爬虫?扣分!
那这个文件是怎么生成的呢?
其实很简单,系统每隔5分钟就会向后台数据库喊一嗓子:“喂,把最新的Bot特征清单发我一份!”
这样频繁的更新,可以确保应对最新的威胁。
本来这套一问一答的流程跑得稳稳当当。
但在11月18号上午11点(UTC时间,下同),工程师对数据库搞了一波权限微调,直接把数据库搞精神分裂了。
首先,咱们要理解一下Cloudflare那个名叫ClickHouse的数据库架构,它是专门处理海量数据的。
另外Cloudflare的数据量是非常大,一台服务器根本塞不下。所以,他们被迫搞了个分店模式(学名叫分片存储)。

你可以把Cloudflare的数据库想象成一家连锁书店,在北上广都有仓库。
前台总管(代号Default):它坐在总部办公室,手里只拿一张索引目录。它不存真书,只负责告诉你书在哪儿。平时系统来查数,都是直接问它。
各地分仓库(代号r0):这些是分布在北京、上海、广州等地的仓库,真正的书(数据)都在这儿堆着。
原本的流程非常丝滑。
系统喊一嗓子:“给我一份Bot特征清单!”前台总管(Default)微微一笑,递出一张单子:“给,一共60个特征。”
特征1:访问速度
特征2:IP地址
特征3:浏览器类型
。。。
系统接单,一切正常。
但在18号一波权限调整后,把原本指向前台总管的单线电话,改成了一个连接全公司的大喇叭。
这时候,系统再喊那句老话:“给我一份Bot特征清单!”,问题就出现了。
因为没指名道姓,对面彻底乱套,所有人都在抢答:
前台总管:“给,这是60个特征!”
北京分仓库(r0-分片1):“俺也一样!这是60个特征!”
上海分仓库(r0-分片2):“巧了!我也有一份60个特征!”
广州分仓库(r0-分片3):“俺也一样!”

一堆分仓库冲上来对着你的耳朵疯狂复读,原本只有60行的特征清单,瞬间被复制成了几百行。
尴尬的是,Cloudflare在设计系统时,为了性能考虑,给特征文件设了个上限:最多200个特征。
他们想着平时也就60多个,撑死100个,200怎么着也够用了。
谁能想到这帮哥们一复读,数据量原地起飞,瞬间冲破200大关。
系统一看到这清单,当场两眼一黑,崩溃不干了。

这还没完,更骚的来了。
这个崩溃它不是一直崩,而是仰卧起坐的崩。
因为Cloudflare数据库集群的更新,是分批进行的。有些节点数据库更新了,有的还是老版本。

所以系统每5分钟进来抓一个数据库问话,都相当于一次开盲盒。
运气好→碰到老版本→总管答复→60条特征数据→网站恢复了。
运气背→碰到新版本→一群人答复→几百条重复数据→网站又崩了。。。
这就是为啥一开始在用户眼里,这些网站时好时坏。
上一秒还在骂娘,下一秒突然刷出来了;刚想上推特学习,看到一半又卡了。
这张GIF更传神了
Cloudflare的工程师一开始也蒙圈,看着流量忽高忽低、网站时好时坏,第一反应是:完了,是不是又被DDoS攻击了?

毕竟前段时间才刚挡下一个7.3Tbps的超级攻击,这种症状太像攻击流量的波动了。
更巧的是,连他们自己的状态页也崩了(后来发现纯属巧合),搞得工程师们一度怀疑:这是有人连我们的状态页一起攻击啊!
在尝试了限流、切换路由等各种操作后,他们终于发现了是自己人在背刺。
于是14:24,他们赶紧停止自动生成新配置文件,手动翻出一个之前能正常工作的旧版本,测试确认没问题,然后推送到全球所有服务器,大部分服务开始恢复。
最终17:06,所有下游服务逐步重启完成,清理掉之前的错误状态,宕机正式结束。
整个过程持续了将近6个小时。。。

Cloudflare在官方事故报告里承认了自己的错误,并承诺会加强配置文件检查、审查所有模块的容错能力,具体细节差评君就不展开了。
这些措施听起来都挺合理,但每次大厂宕机后都会发类似的保证书。
上个月AWS崩了,这个月Cloudflare崩了,过段时间说不定又轮到谁。
对于大多数普通用户来说,昨天这场宕机可能就是“网站打不开了,等等就好”。但对于那些严重依赖在线服务的企业来说,这是真金白银的损失。
上个月AWS的宕机影响了60个国家1700多万用户,导致3500多家公司业务中断,经济损失每小时超过7500万美元。
这次Cloudflare宕机6小时,损失恐怕也少不了。

用户们可能什么都做不了,开发者可以考虑多云部署、备用方案,但成本和复杂度都会大大增加,小公司根本玩不起。
咱们就只能期待这些基础设施公司真的能从每次事故中吸取教训。
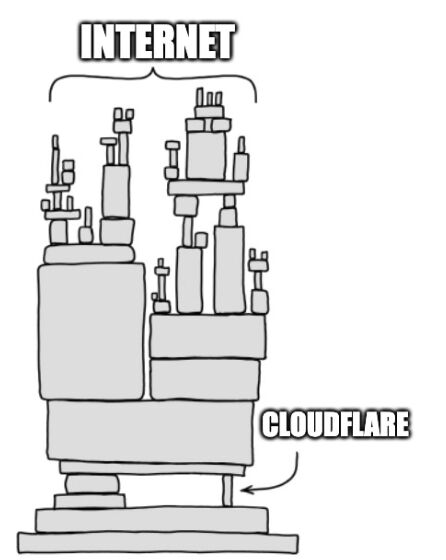
毕竟整个互联网就是建立在极少数基础设施公司之上,它就像一座空中楼阁,看起来宏伟无比,但地基只有那么几根柱子。
哪根柱子晃一晃,整座楼都得跟着颤。
撰文:刺猬
编辑:面线莽山烙铁头
美编:焕妍
图片、资料来源:
CloudflareoutageonNovember18,2025
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

