- +1
PRL:量子水池中的涟漪,如何在“混沌边缘”触发最强算力

导语
向平静的水池投入石子,涟漪在水面交织,将扩散出复杂的信息波纹。这种朴素的物理直觉,正在推进机器学习的前沿:量子储层计算。与动辄消耗巨量算力的深度学习不同,量子储层计算巧妙利用量子系统的自然演化,将复杂任务简化为“读出涟漪”的过程。其中,性能的最优解并不在于单纯的有序或彻底的混乱,而在于那道微妙的“混沌边缘”。本文将介绍储层计算的物理内涵 ,看科学家如何利用量子系统的信息弥散及高维态空间特性,在“记忆”与“处理”的博弈中,找到通往最强算力的混沌边缘“甜点位”。
关键词:量子储层计算,量子混沌,SYK模型,时间序列
李文韬丨作者
赵思怡丨审校

论文题目:Edge of Quantum Chaos in Quantum Reservoir Computing 论文地址:https://doi.org/10.1103/j2qj-vwcl
发表时间:2026年1月28日
发表期刊:Physical Review Letters
储层计算(Quantum Reservoir Computing)是适用于时间序列问题的一种机器学习框架,特点在于训练和运行成本低。其原理是将输入信号通过非线性映射,嵌入到高维空间中,最后再对高维空间中的矢量做一个线性变换,作为读出层。在机器学习的意义下,这个单层的线性变换是唯一需要训练的权重层。研究团队提出:相比于经典比特,量子比特可以在指数维度增长的Hilbert空间中编码信息,从而提供更高维的特征表示能力。此外,量子多体系统中存在叠加与纠缠等现象,使得输入信息在系统演化过程中产生复杂的高阶相关结构,并通过测量过程体现为非线性的输出响应。进一步地,量子系统中的信息弥散(scrambling)过程能够将局域输入快速扩展到全系统,从而同时引入非线性特征与时间相关性。
基于这些性质,一个关键问题是:如何调控量子动力学过程,使系统既能够充分利用高维与复杂相关性来增强信息处理能力,又不会因信息过快随机化而丧失对输入历史的记忆,从而提升储层计算的整体性能?
1. 背景:储层计算的特点
除明确标明之处以外,以下的简要介绍部分为作者所写,并非论文原文的内容,而只是起到补充作用。
通常的神经网络是由多层神经元组成,每层神经元相当于一个巨大的矩阵,神经元对应矩阵的元素。在训练神经网络的过程中,每个神经元都需要根据损失函数的梯度下降进行修正,训练成本因而随着神经网络的规模增加而剧烈增加。另外,在梯度下降算法的具体实现中,有可能遇到局部极值问题,因此训练过程的收敛性不能很好地得到保证。
储层计算是一种新型的机器学习架构。所谓的储层(reservoir)指的是一个高度非线性的函数,该函数将输入信号映射至高维空间中的某个矢量。给定一个非线性函数,在训练神经网络的过程中,该函数并不受到修正,唯一受到优化的是最后的“读出层”。由于训练过程只是优化最后一层神经网络,训练问题可以被转化为一个凸优化问题,也就是说训练过程的收敛性更可靠、代价更低。“储层”指的就是把输入信号“映射”、从而“存储”到某个高维空间(“层”)的这一结构。
研究者指出,储层中所使用的非线性映射,并不一定需要在计算机中实现,而是可以利用各种各样物理上便于实现的非线性系统来构造,只要最后可以读出一个矢量值即可。因此,集成光子学系统或者其他物理系统可以针对储层映射来优化性能,从而节能并且加速训练。
储层类似于一个水池,如果池中投入石子,将会产生一些水波;如果只观测池中某个特定水分子的运动,那么只能得到一个热运动夹杂着机械运动的信号,但是如果拍摄水池的俯视图,就可以看到水波是如何随着时间向外传播的。连续投入多个不同重量、下落速度、下落方向的石子,激发的水波也不一样。
这个例子中,水池的俯视图是一个高维空间,而单个水分子的运动轨迹是低维的。从这个直观例子可以发现,将信号“涟漪般散开”到一个高维空间有助于记忆和处理时间序列信息。
处理时间序列问题,为什么需要一个非线性映射?我们考虑一个由“0”、“1”组成的信号序列,如果我们用一个线性映射来“记住”这个序列,那么最简单的映射就是复制,将这个“01001110...”的字符串直接存储到“储层”中。 这类似于轻轻地向水池投入石子,激发的水波遵循线性方程,互相之间可以相互叠加和干涉,但不会相互作用。
这个储层可以执行最简单的时间序列任务,例如“记忆”问题,也就是“回答出之前某个时刻的信号是什么”,但是无法执行任何非线性的运算,例如“上一个和上上个信号的AND运算”。AND 运算是非线性的,因为它不满足叠加律。我们用 (x,y) 表示两个字符串 x 和 y,逗号左边和右边的字符串将会被取 AND。考虑 (1,1) 和 (1,0) 这两对字符串。作为二进制字符串的和为 (0,1),再取AND 为 0,但 AND(1,1)=1, AND(1,0)=0, 相加为1。
这种非线性相互作用就类似水波之间的非线性相互作用:如果投入石子时非常用力,那么或许不仅会激发水波,还会溅起各种形状的水花,而水花落到其他石子的水波上又导致其形状改变,等等。考虑极端情况,如果落入的不是石子而是一块巨大的、高速坠落的陨石,那么它激起的水花可能会过于剧烈,导致之前投入的石子所激发的波纹变得混乱而不可辨识。
因此,直观上可以理解:储层映射的非线性映射功能与记忆功能之间,存在矛盾。信息之间的相互作用,不一定是可逆的:从非线性相互作用的结果出发,不一定能可靠地反推出参与相互作用的信息原来是什么样。例如 AND 运算就是不可逆的,满足 AND(x, y) = 0 的 (x, y) 有 3 种可能性,从 AND 运算结果无法可靠地知道原先的 (x, y) 是什么。
既然非线性与记忆之间存在矛盾,为什么最终的读出层仍然只需要一层矩阵运算,即可经过训练而完成多种多样的任务?这是因为,读出层的有效性并不取决于任务本身的线性与否,而是取决于储层空间是否足够高维,以至于信号中复杂的特征能够充分地在高维空间分离。例如桌面上摆放着黑白两种颜色的玻璃球,在桌面上画一条线分开它们或许很难,但是如果这些球是悬浮在三维空间中,那么通过巧妙地选取一个二维平面,或许就可以很好地分开两种球。这个例子中只有“颜色”一个特征需要分辨,但我们完全可以想象,也许时间序列的每个信号还有另一种与颜色无关的特征,那么储层空间还需要为这个特征再分配几个维度。为了处理复杂信号,储层空间的维度应该增加,这样即可减轻读出层的负担。
既然储层映射需要引入一定的非线性,那么具体来说,怎样的非线性映射最为合适?考虑一个连续的非线性映射,例如非线性微分方程的演化过程:初值被非线性地映射到轨迹上的某一点,那么轨迹的特点就决定了该映射的特点。从不动点、轨道和吸引子的角度来看 (Strogatz 2024),信号在储层映射下的像最好不要都局限在某个吸引子、甚至是轨道附近(这将导致非线性映射的行为类似于线性映射,缺乏相互作用),但也不要完全混乱地遍历全空间(这将导致储层计算读出层的负担太重,信号的特征几乎被混沌抹去了)。
以下内容均来自论文原文及分析。
当储层映射是经典的,相应的储层计算框架称为经典储层计算;对于量子的储层映射(即,借助量子系统的时间演化实现映射),相应框架称为 量子储层计算 (Quantum Reservoir Computing, QRC) 。已有文献指出,最适合经典储层计算的映射是那些处于混沌边缘(edge of chaos)的映射(见原文参考文献48-55)。研究团队类比经典情况,针对量子储层计算提出如下猜想:对于量子的储层映射,最适合储层计算的也是那些在时间演化过程中,处于量子混沌边缘的系统。
针对非线性方程和经典动力系统,已经有较为普适的可观测量用于刻画“混沌”,例如李雅普诺夫指数 (Lyapunov exponent) (Strogatz 2024),当演化时间大于 Lyapunov 指数,系统将呈现剧烈的初值敏感性质,即经典混沌的定义。对于量子系统,没有“轨道”、“Lyapunov指数”等概念,甚至连更一般的“量子混沌”具体如何普适定义也还没有定论。因此,研究人员选择了一个具体的严格可解模型作为研究的出发点,这就是 SYK (Sachdev-Ye-Kitaev) 模型 (参见原文参考文献62-65)。这是一个既能够刻画信息弥散,又具备良好可调性的模型体系,利于系统地研究。
2. 方法:用严格可解模型作为例子
SYK 模型由格点上的哈密顿量定义,其具体形式为
其中 N 是系统总格点数,
是费米型产生、湮灭算符,
都是从 高斯型随机矩阵 (Gaussian random matrices) 中采样的元素,J 是相互作用强度,κ 是无相互作用项。也就是说,研究人员采用的储层映射是
, 其中第一个格点的量子态初值由时间序列信号设定(参见原文公式 2 及相关介绍)。
SYK 模型的特点是:在时间维度上,存在类似于 Lyapunov 指数的 Thouless time,系统演化时间超过 Thouless time 以后,就呈现出混沌的特点。在参数维度上,可以调节相互作用强度来调节信息弥散(即混沌)程度,即 J/κ 越大,系统的混沌特点越强,当 J=0, 系统完全不具有混沌。
针对这一模型,用来判断混沌与否的可观测量是 能量本征态间隔分布 (eigen-energy spacing distribution) 和 谱结构因子(spectral form factor, SFF),可用于确定是否处于混沌状态,以及混沌-非混沌的转变点。其中,SFF适用于时间维度,能量本征态间隔分布适用于处理参数维度。
研究人员使用两种时间序列任务测试量子储层计算在不同条件下的性能: 短时记忆(Short-term Memory, STM) 和 非线性自回归平均问题(Nonlinear Auto-regression Moving Average, NARMA),前者考验短期记忆,要求储层计算模型记住 d 步之前的输入信号,另一个考验记忆和信息处理(即非线性计算)能力,要求储层计算模型输出前序信号的一次型平均值与二次型平均值的加权和(具体见原文第3页)。由于表达式中出现了二次型,NARMA任务显然无法用线性的储层映射完成。
具体而言,研究人员将储层映射设定为 8 个格点上的 SYK 模型时间演化,针对不同的演化时间和混沌参数(时间和参数都可以调节混沌与否,因此共 2×2=4 种情况),分别执行两种任务,考察表现,因此共有 8 种情况。
3. 发现:量子混沌的边缘利于储层计算
研究人员进行的8次数值实验,可以根据任务类型(共2种)和实验条件(调节时间和参数分别是否混沌)来分类,如图所示。上半部分对应的是固定哈密顿量参数、调节演化时间,也就是跨越了量子混沌的 temporal edge。类似地,下半部分对应的是固定演化时间、调节哈密顿量参数,也就是跨越了量子混沌的 parameter edge。
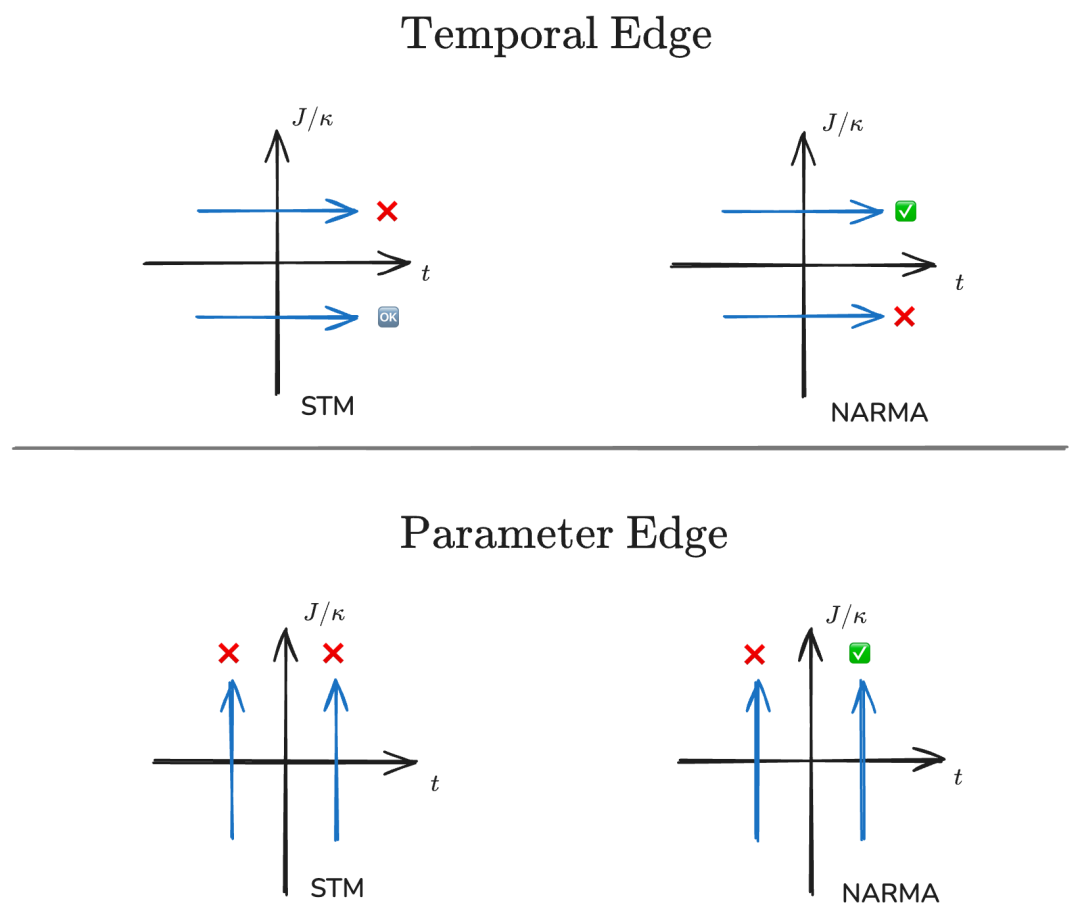
图为作者所画的文章思路示意图。每个黑色坐标轴的正向都代表混沌,负方向代表非混沌,坐标原点对应混沌与非混沌的临界值。每个蓝色的箭头代表调节系统性质、观察储层计算性能的一次实验。箭头方向代表系统性质向某个方向进行调节,箭头附近的符号代表实验测得的储层计算性能,从差到好依次是❌、?、✅。其中,?代表性能相对好但是没有峰值、无法优化,✅代表性能相对好且存在确定的峰值位置。
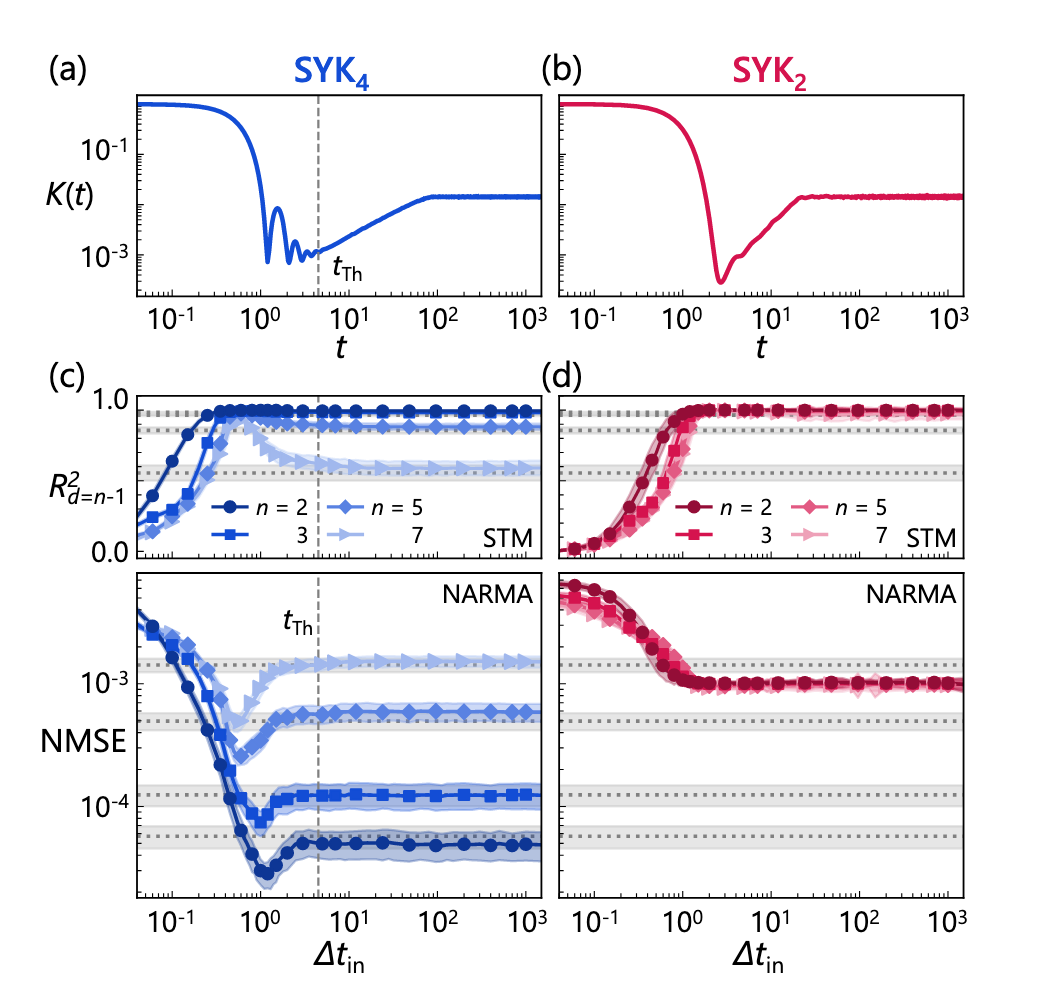
图1:(a), (b):SYK4, SYK2 模型分别对应的谱结构因子,每条曲线表示20000次实验的平均值。(c), (d):量子储层计算的性能作为 Δ tin 的函数,分别对 SYK4, SYK2 模型进行计算。上半部分的图中标明了记忆任务性能
(值越高代表性能越好),下半部分的图中标明了归一化均方误差在NARMA任务下的值(值越低代表性能越好)。不同图形符号代表不同的任务阶数 n=2,3,5,7。水平的虚线是Haar量子储层计算的性能,作为定标的依据,与本文实现的储层计算模型作对比。所有的性能值都是在500次计算后取平均所得,曲线周围的阴影部分代表实验样本的标准差。图中的竖直虚线代表 Thouless time,记作 tTh。
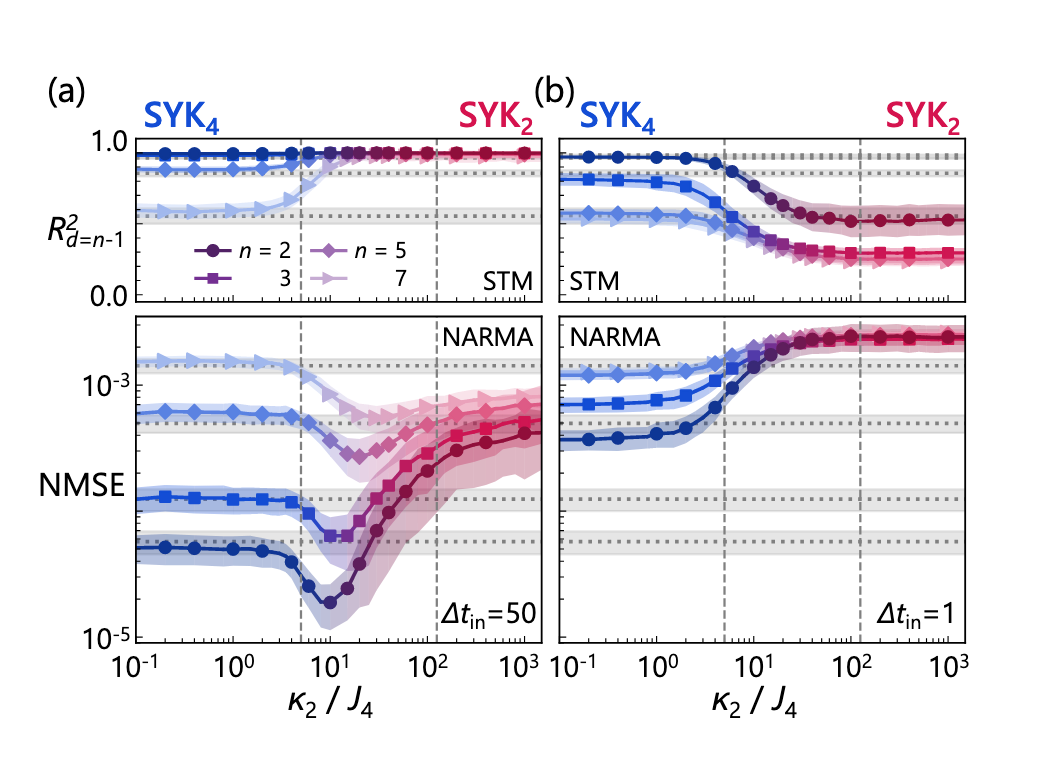
图2:(a), (b):量子储层计算的性能作为 κ2/J4 的函数,分别在输入间隔 Δ tin 为50 和1 下测得,类似图1的(c)和(d)。图形符号代表不同的阶数,颜色代表能量本征值间距分布的性质,蓝色代表混沌,红色代表非混沌。虚线代表能量本征值间距分布的实验测得值与理论值的差距小于10-2的临界点。
3.1. STM任务
在STM任务中,储层计算只需执行一个线性的“复制粘贴”即可。因此,在这个任务中,SYK模型越混沌,表现就越差。从图1 可以看出,系统达到 Thouless time 以后,针对该任务,J/κ 较大时,储层计算的表现较差;从图2(a) 中也可以看出,系统哈密顿量的参数越偏向混沌,表现就越差。总而言之,该任务并没有展现出“混沌边缘”的特点,而只是单纯地不适合混沌系统,在系统跨越混沌边缘时,也没有呈现出性能峰值,而只是单调变化。这都是由该任务的线性性质导致的。
3.2. NARMA 任务
在 NARMA 任务中,储层计算既需要执行线性的加权平均,又需要计算二次型的表达式,因此这个任务需要储层计算模型在记忆和非线性处理之间取得平衡。
从图1可以看到,对于参数较为混沌的系统,随着储层映射的演化时间增加,储层计算性能在演化时间略小于 Thouless time 处取到峰值,且任务越简单,性能越好;对于参数并不混沌的系统,随着储层映射演化时间增加,储层计算性能只是单调上升并饱和,且性能与任务的复杂度无关(任务即使简单,性能也一样差)。
从图2 可以看到,如果只允许储层映射进行哈密顿量的短时演化,以至于无法到达混沌时间,那么即使在参数维度跨越混沌边缘,也没有意义,无法提升储层计算性能(这是因为足够的时间也是达到混沌的充分条件之一);如果给予储层映射足够的演化时间,那么,在参数 J/κ 跨越混沌边缘时,NARMA 任务的性能将取到峰值。
特别地,针对“跨越参数边缘(temporal edge)”且演化时间足够长的情况,研究人员调节了 NRAMA 任务的阶数(原文称作 "order", 由字母 n 表示,具体见原文第3页)。从 NARMA 任务的定义可以看出:n 越大,代表储层计算系统需要记住越“久远”的信号。由于非线性映射不利于记忆,直观上不难猜想:n 越大时,最优的参数应该越远离混沌边缘、偏向非混沌区域。而原文中的图 4(a) 恰恰也反映了这一点,针对越大的 n,性能峰值对应的 κ2/J4 参数位置越大,即越偏向非混沌。
4. 总结与展望
汇总所有的数值结果,研究人员发现:在 8 种情况中,STM 任务对应的 4 种情况较为平凡,无法显示出混沌边缘效应,储层计算性能完全由哈密顿量参数决定;而 NARMA 任务对应的 4 种情况显著地表现出了混沌边缘效应,即,在“时间”和“参数”两个维度中,如果其中一个已经满足混沌,另一个从“非混沌”变为“混沌”,那么系统将在这个过程中展现出量子储层计算的峰值性能。并且研究人员进一步发现,峰值对应的位置,取决于机器学习任务本身在“非线性与记忆的矛盾”中偏向哪一方。
本文从一个自然的经典-量子类比出发,提出了量子储层计算与量子混沌边缘有关,并数值上研究了这种关系具体如何,以及,这种关系如何受到储层计算任务的影响。研究团队认为,他们的结果虽然是从具体的 SYK 模型得到,但是谱结构因子和能量本征态间隔分布都是不依赖于模型的可观测量,并且并不仅仅对 SYK 模型有效,因此他们的思路和方法可以拓展到其他模型中。
原文研究的模型是随机矩阵模型,但量子混沌还有其他模型,例如 局域化相变 (Ergodic-Localization transition) (Abanin et al. 2019)。使用其他量子混沌模型的量子储层计算性能究竟如何、与随机矩阵理论又有什么联系、随机矩阵理论在多大程度上能普适地刻画量子混沌与量子储层计算的关系,仍有待研究。
对机器学习系统的全面评估,本身就是复杂的;研究团队也提到,由于量子储层计算是结合了经典机器学习与量子演化的机器学习框架,如何判定系统的某个特点究竟来自量子部分还是经典部分,本身就具有挑战性。这也是一个需要结合机器学习的工程实践与量子混沌的物理直觉的开放问题。
参考文献
Strogatz, Steven H. 2024. Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering. 3rd ed. Chapman and Hall/CRC. https://doi.org/10.1201/9780429398490.
Abanin, Dmitry A., Ehud Altman, Immanuel Bloch, and Maksym Serbyn. 2019. “Many-Body Localization, Thermalization, and Entanglement.” Preprint, February 13. https://doi.org/10.1103/RevModPhys.91.021001.
原标题:《PRL:量子水池中的涟漪,如何在“混沌边缘”触发最强算力》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

