- +1
2026.5数学未来研讨会系列——压缩即为建模数学的核心
发言人:迈克尔・弗里德曼(Michael Freedman,菲尔兹奖得主,哈佛大学)

标题:压缩即为建模数学的核心
摘要:本次报告将讲解一篇近期发布于预印本网站 arXiv 的同名论文https://arxiv.org/abs/2603.20396 ,论文合著者为维塔利・阿克塞诺夫(Vitaly Aksenov)、伊夫・博迪纳(Eve Bodnia)与迈克・马利根(Michael Mulligan)。研究思路借鉴物理学思维,借助简易原型模型对看似繁杂的客观存在 —— 数学开展建模研究,依托模型完成精准运算,并将运算结果与实际现象比对。
本次建模依托有限生成幺半群,相关数据取自基于Lean证明器搭建的大型知识库MathLib。数学定义与引理具备层级特性,研究通过为幺半群增设冗余生成元来复刻这一特征,可类比自然数体系中用于位值计数的 10 的幂次。位值计数法能以指数级压缩形式简化数字表述,对数学库的研究表明,这一压缩规律普遍适用于人类整体数学体系。我们期望文中提出的可观测指标,能够助力智能算法探索发掘各类有研究价值的数学问题。
本文中的术语:HM(人类数学)、FM(形式化数学)、DH(有向超图)、DAG(有向无环图)、PA(位(值)记数法)
作者:斯坦福大学FSM数学未来研讨会(Future of Mathematics Symposium)
迈克尔・弗里德曼( Michael Freedman,菲尔兹奖得主,哈佛大学)2026-5-1
译者:zzllrr小乐(数学科普公众号)2026-5-26
求点赞

求分享

求喜欢

主持人:
接下来有请下一位演讲者,迈克・弗里德曼 (Michael Freedman)。他本次演讲主题为压缩即为建模数学的核心。
我最初知晓迈克,是因其拓扑学领域的研究成就。他于1986年凭借四维庞加莱猜想的证明斩获菲尔兹奖。但实际上,迈克的研究涉猎范围极为广博,也是我见过思维最为开阔的学者之一。
他早年深耕拓扑学领域,之后前往微软量子实验室 Station Q 投身量子计算相关研究。如今他的研究又和 Lean 体系产生关联,这段经历着实令人惊叹。目前他任职于哈佛大学数学科学与应用中心(CMSA),同时担任逻辑智能公司(Logical Intelligence)数学首席研究员,近期研究方向转向机器辅助证明,以及数学整体的存在价值。闲话不多说,下面有请迈克・弗里德曼。
PPT:(中文翻译仅供参考,请以原文英文为准)
压缩即为建模数学的核心





















迈克尔・弗里德曼演讲全文:
感谢贾里德,很荣幸来到现场。听完利奥(Leonardo de Moura)的分享,严谨的研究标准让我颇为感慨。我向来只能梳理出大致思路,文稿里若出现文字疏漏,大家可以现场自行指正。
今天我想探讨的核心观点是,人类认知与钻研的数学体系,建立在定义层层嵌套、内容不断压缩的架构之上,定理与引理均遵循这一规律。这属于数学哲学范畴,同时具备切实落地的应用价值。该理论旨在引导智能体遍历形式化数学空间,空间内所有逻辑推导均可实现,这套理论能规范智能体的探索路径,帮助其发掘具备研究意义的内容。智能体与人类思维本质相差不大,只是运算速度远超人类,海量数值也能瞬间算出。我们和人工智能处于同一探索赛道,需要像引导后辈一般,助力智能体坚守合理的研究方向。
本文所指数学,并非纯粹形式化理论,而是人类实际研究的数学范畴,既包含现有研究成果,也涵盖未来待发掘、具备价值的内容。压缩理论既能阐释现有数学规律,也可为后续研究探索提供指引。
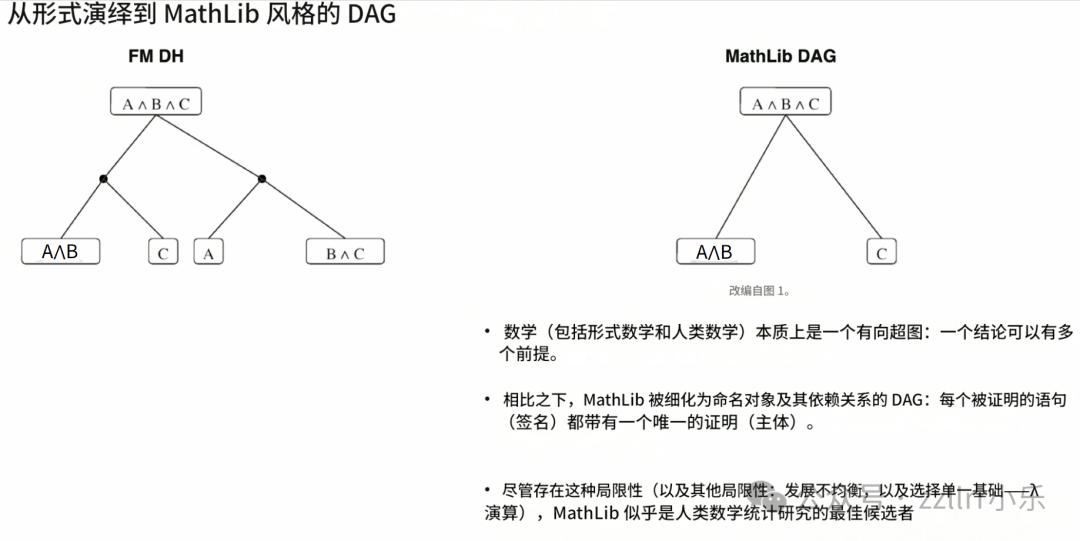
接下来介绍本次演讲的整体脉络。首先谈及数学的形式架构,上一场分享提到,研究体系以集合论逻辑或是依存类型论为起点,细节层面差异显著。从宏观角度来看,数学属于超图结构,同一结论往往能经由多种推导路径得出,假言推理便是典型例子,图中带黑点的线条代表超边。简易示例选取命题逻辑中的命题合取运算。
本次研究核心参考资料 MathLib,其结构被简化为普通有向无环图(DAG)。编撰设定当中,一份证明仅对应单一定理,命题陈述为定理标识,推导过程作为主体内容。这种结构适用于记录最简命题、梳理基础定理推导逻辑。但想要搭建完整学科体系,仅依靠有向无环图远远不够,无法厘清各项结论间的依存关联,超图结构则囊括了更多有效信息。
本次研究借鉴物理学研究思路。现场有不少物理领域从业者,我并非物理专业研究者,但长期和物理学者交流,也习得部分研究方法。物理研究通常选取现实中的某类现象,搭建简洁且逻辑严谨的仿真模型模拟客观规律,一边观测真实现象,一边在模型中运算推演,比对两者结果,调整模型参数,以此预判现象、加深对客观世界的认知。
此次我们将数学视作研究客体,把它当作特殊的客观现象,搭建简易数学模型挖掘内在规律。数学研究的基本形式为内容拼接整合,基础单元组合形成中型结论,中型结论再进一步拓展延伸。引理支撑定理推导,定义之间相互嵌套。
适合实现内容拼接的基础结构以群为代表,群结构支持元素乘法运算,但群还包含逆元属性,超出本次研究所需范畴。幺半群(monoids)去除逆元条件,自然数体系就是典型的幺半群模型,下文会多次引用该案例。若追求更高抽象维度,还可构建双范畴、n 范畴结构,这类结构的组合运算不满足结合律,也可选用球状广群模型。本次主要围绕正整数及其拓展形式展开分析,包含自由交换幺半群,以及运算顺序具备约束条件的自由幺半群。
三千年前诞生的位值记数法(PA),是整数体系中极具代表性的数学突破。该记数法仅用少量字符,就能表述量级跨度极大的整数。对 MathLib 的数据统计分析发现,时至今日,数学研究依旧沿用位值记数法蕴含的压缩逻辑,细微层面也能印证这一规律。
想必多数听众都了解位值记数法,这里借此引入宏指令概念,该术语源自计算机领域。以皮亚诺算术体系为例,体系内仅能通过逐次加一的方式生成新整数。
在基础幺半群中增设冗余生成元,能够加快数值构建效率,这类新增元素即为宏指令。位值记数法依托层级化方式定义宏指令,以数字 1 作为基础元,衍生出十进位基础单位,该单位不属于独立原生元素,属于冗余补充元素,却能大幅提升表达效率。依照此逻辑,依次衍生百、千等计数单位,整套计数体系便由各类宏指令构成。
位值记数法的宏指令具备精简特性,对数密度即可实现数值的指数级拓展。研究发现,人类探索数学依托的核心逻辑,和位值记数法的压缩原理高度契合。
左侧列举两类常用幺半群,多数研究分析适用于正整数范畴。n 维空间整数坐标点构成交换幺半群,自由幺半群则严格区分元素运算顺序。最简自由幺半群由 a、b 两个元素生成,可衍生出二元字符组合序列,元素数量呈指数式增长。
红色标注的宏指令集合,用于简化幺半群内大数元素的表达。位值记数法对应的核心生成元为 10 的幂次。
直观来看,数学推导步骤不满足交换性,整体体系如同树状分支,研究方向多元,这类特征看似契合非交换自由幺半群。但实际数据显示,人类数学的压缩特征和 MathLib 体系一致,整体呈现多项式增长规律,性质更贴近交换幺半群。海森堡幺半群同样具备多项式增长特点,多项式增长也是人类数学体系的典型特征。
接下来给出相关定义,依托扩张函数分析压缩特性,函数取值由宏指令集合决定。设定基础生成元集合为 G,加入宏指令后得到拓展生成元集合 G'。压缩函数代表依托宏指令,在指定范围半径内,所能覆盖到的原生符号体系最大范围。位值记数法借助 10 的幂次元素,让扩张函数呈现指数增长态势。
我们将 MathLib 视作人类数学的参照样本,项目初期收录约五十万个命名条目,如今条目数量至少翻倍。库内所有定义、引理与定理均基于 Lean 编写。
本次论文合著团队成员均来自逻辑智能公司,部分人员同时兼任高校职务,我也任职于哈佛大学数学科学与应用中心。团队成员维塔利将 Lean 代码库转化为依存关系有向图,图表内每个条目都标注对应的推导依据,团队针对图表数据开展统计分析。
研究中定义两种文本长度,表层长度为条目编写所用字符总数;深层长度则逐层拆解至 Lean 基础原生元素,统计完整推导字符量,重复调用的引理内容会重复计入统计数值,该数值也称作树形长度。
研究围绕表层长度、深层长度与层级深度三项指标,剖析 MathLib 体系结构。层级深度代表有向图内,从条目溯源至基础元素的最长推导链路。
MathLib库内一条布罗迪克相关定理,表层精简表述仅350多个字符,完全拆解为原生推导结构后,字符总量可达 2¹⁰⁴级别。该案例并非递归函数理论下的虚构命题,而是代数几何研究里的常规推导现象。
这也贴合数学研究的实际体验,研究者能熟练掌握当前层级的抽象理论,面对更高层级概念则容易难以理解。日常研究适配十余层抽象嵌套结构,层级过多便会超出认知范畴。日常推理一般不会拆解底层逻辑,仅在必要时溯源剖析,研究者通常在固定抽象层级开展工作。
本节核心结论:依托表层长度与深层长度的差值,衡量 MathLib 体系的层级架构与内容压缩效果。在幺半群搭配宏指令的仿真模型中精准运算,分析压缩原理与层级规律,对比实测数据与运算结果,以此归纳数学体系的内在特质。
再次梳理核心定义:表层长度为库内实际编写字符数,数值通常在百余至数百区间;深层长度数值跨度极大,可达到巨型量级。层级深度代表有向图中溯源至基础元素的最长路径。
MathLib库内定理包含命题标识与推导主体两部分,团队围绕命题、推导主体分别统计表层与深层长度,四项数据作为参照依据,对比模型运算结果。
研究初期将两类核心指标命名为偏好度与价值度,命名仅为通俗表述,后续调整为抽象度概念。抽象度越高,基础表述篇幅越长,精简表述形式越简洁,对应抽象度核心数值越高。价值度以定理精简表述篇幅、完整证明篇幅的比值判定,费马大定理表述简短,证明过程却极为繁复,就具备极高研究价值。
标注下标 0 代表基础统计维度,后续还会引入网页排名PageRank算法,梳理命题间的依存推导关系,各指标也会同步迭代优化。
顺带介绍团队自研自动证明系统 ATP Alpha prover,论文内六七条定理均通过该系统核验,依托 Lean 校验证书证实结论无误,每条定理旁均标注核验标识。我个人撰写的推导内容,或多或少都存在瑕疵。
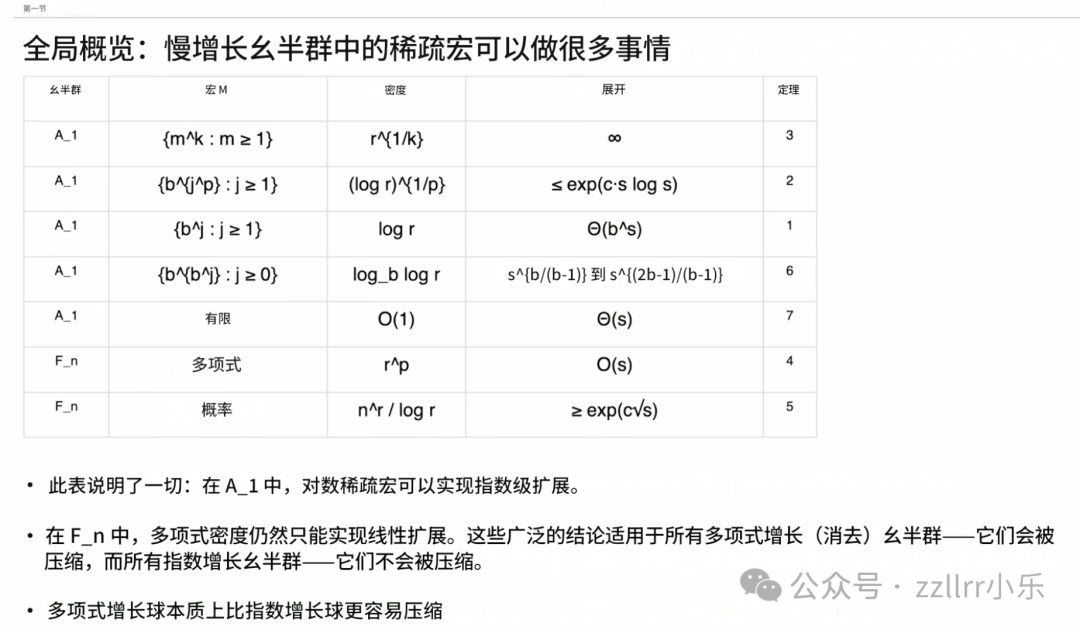
下表汇总模型测算结果,所有多项式增长类幺半群的运算规律相近。

最右侧单列代表单一生成元构成的正整数幺半群,其余列为自由幺半群数据,变量参数为宏指令集合规模。表格第三行对应位值记数法模型,10 的幂次元素在整数体系内呈对数密度分布,内容压缩幅度为恒定区间内的指数级变化。
表格首行相关规律,关联数论中的拉格朗日四平方和定理与华林定理,数论领域存在加法秩(additive rank)概念,陶哲轩在此方向产出大量研究成果并编撰相关著作。【子集S⊆ℕ的加法秩,指能使其和集(sumset)覆盖全体自然数的最少子集复用次数,译者注】
数论领域的研究命题为:确定数集最少组合数量,使其求和结果可以覆盖全部正整数。拉格朗日证实任意整数均可拆解为四个平方数之和。若将平方数作为宏指令,体系拓展无上限,四个平方数即可组合出所有整数。该规律并未违背信息理论,平方数本身字符书写体量偏大。三次方数也具备同类特性,九个三次方数可组合得到全部整数,任意整数幂次元素均可满足组合全覆盖条件。
前文提及的扩张函数,是数论百年加法秩研究的延伸拓展。传统研究统计全覆盖所需元素组合数量,我们研究不断叠加 S 组元素时,体系覆盖半径 R 范围的扩张速率。
表格里无需逐行详解,整体规律为宏指令集合密度越低,扩张速度越缓慢。当宏指令仅为有限集合时,扩张速率仅常数波动,始终维持线性增长,对应表格末行。
这份表格核心结论在非交换自由幺半群体系中截然相反。由多组无交换、无消去特性的元素生成自由幺半群,引入多项式密度宏指令,体系依旧呈指数式增长;仅添加同等密度宏指令则毫无效果,扩张速率不会改变。只有近乎将全部元素纳入宏指令范畴,才能产生明显作用。
表格末行采用概率构造方式,人工智能为此提供辅助支撑,构造思路借鉴遍历式随机建模。该宏指令集合密度趋近满集,满集条件下体系会呈现 Nᴿ级指数增长,此集合密度略低于满集,但差距不大,最终形成拉伸指数级增长速率。
表格总结规律:若幺半群自身几何规模仅呈多项式增长,交换幺半群、幂零幺半群均属此类,少量宏指令就能大幅拓宽覆盖范围,压缩效率极高。若幺半群本身已是指数级增长,只有纳入绝大部分元素作为宏指令才能起效,无法实现精简高效的压缩模式。
后续幻灯片会逐条对应表格规律展开阐释,受时长限制不再逐一细说。首类模型对应位值记数体系;表格第三行体现整数域多项式增长集合可快速覆盖全体整数;自由幺半群中多项式规模宏指令无法提升覆盖能力;概率模型下,宏指令集合覆盖度接近全部元素时,压缩效果才得以显现。
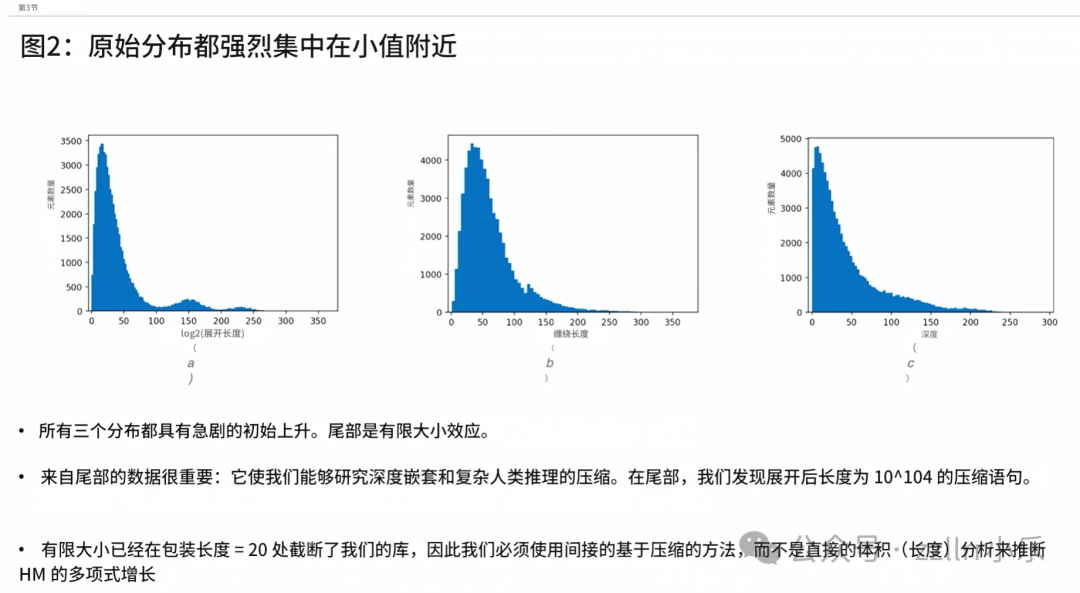
接下来分析 MathLib 统计特征。有限规模局限导致无法依靠直观数据判定整体增速,图像曲线在横坐标数值 20 以内呈现高阶多项式甚至指数增长趋势,后续走势趋于平缓。目前知识库体量仍在快速扩张,五年后规模将大幅提升,届时拟合曲线才能精准判定增长速率,现阶段该测算方式并不适用。
研究转换思路,不从增速切入,转而剖析压缩机制,参照 MathLib 实际压缩规律,反向匹配契合特征的幺半群与宏指令参数。多项式增长型幺半群可贴合实测数据,指数增长型幺半群无论调整宏指令参数,都无法复刻库内呈现的压缩特点。
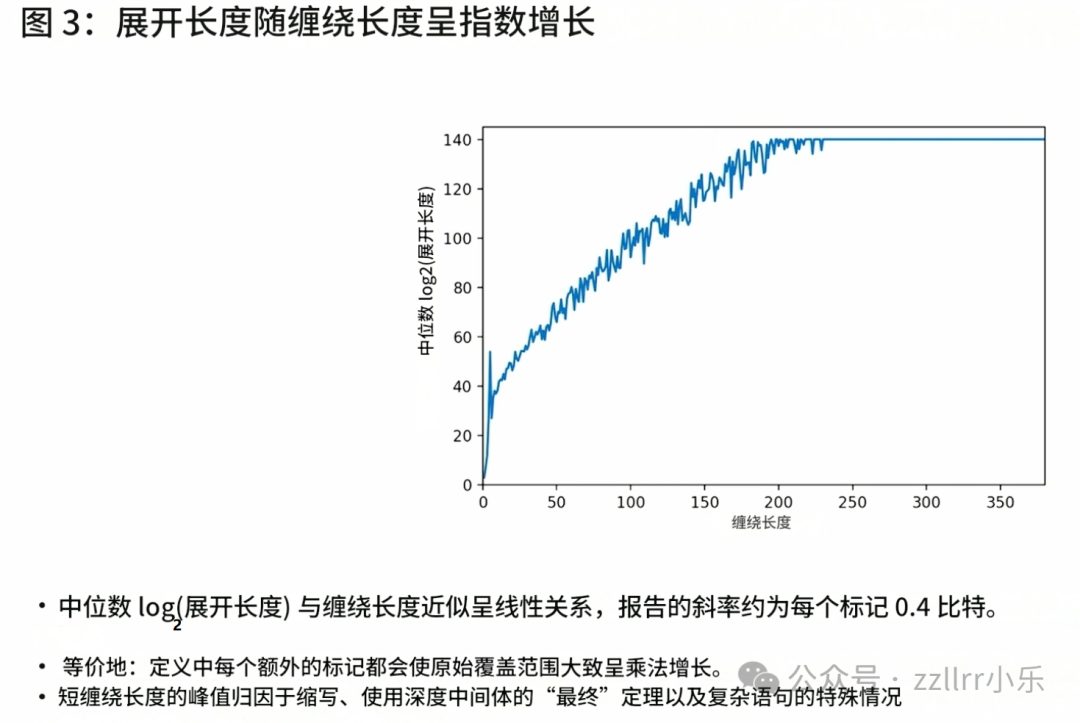
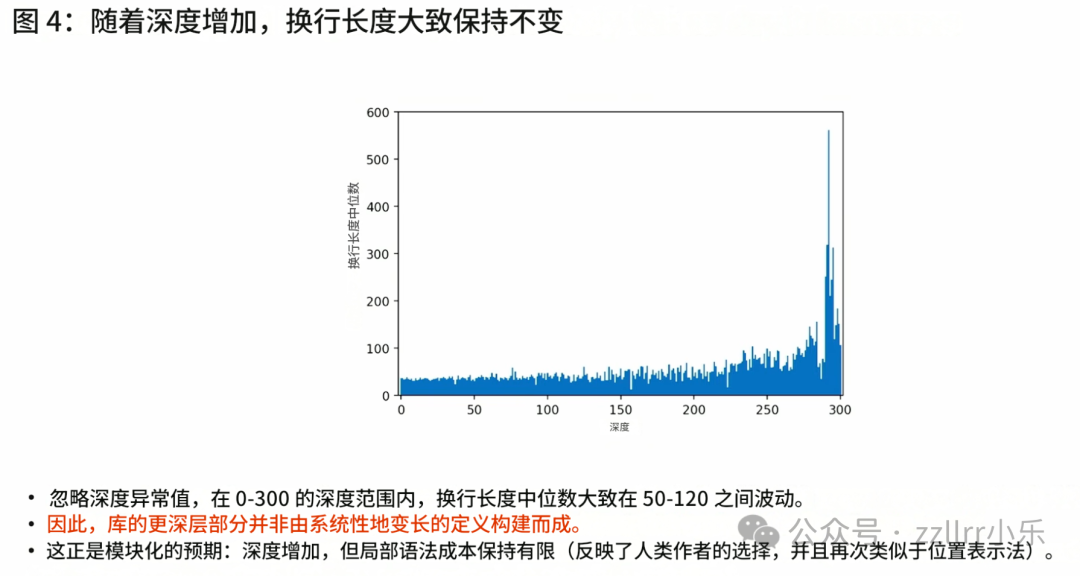
抛开初期小幅波动与极少高表层长度异常样本,深层长度常用对数值和表层长度之间呈现近似线性关联。例如格罗滕迪克相关定理表层字符数约三百,以 2 为底取对数后数值约350。
该规律和十进制计数逻辑相通。整数统计中,人们固定以十为单位逐级进位分组,不会随意变更跨度。映射到知识库中,即便溯源至基础概念链路极长的深层命题,其表层精简篇幅也始终维持合理区间。这契合人类认知特点,篇幅冗长的内容难以理解,研究过程中不断抽象归纳,以此把控内容表达体量。
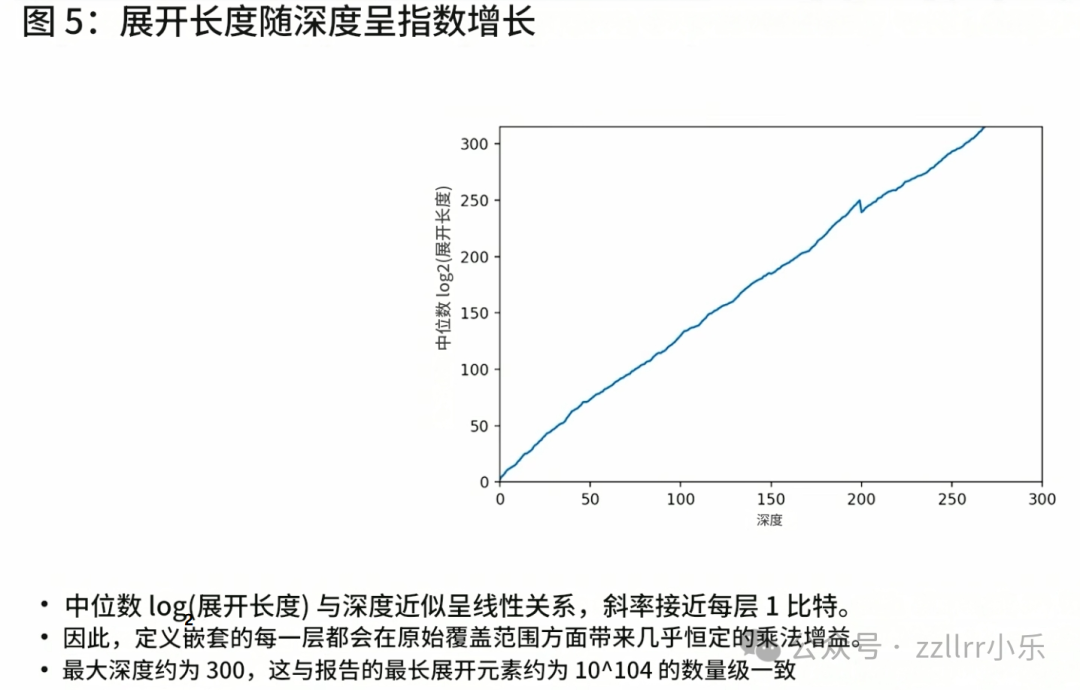
最具说服力的数据特征为层级抽象度与深层长度对数一一对应,深层长度呈指数变化,其对数值基本等同于抽象层级数量。横纵轴数值上限同为三百仅为巧合,斜率并未出现倍数偏差。
开展模型匹配验证,对照不同密度参数下的幺半群与宏指令组合,比对深层长度对数和层级深度的线性关系、表层长度平稳变化趋势,以及内容压缩比例。十进制模型具备标准线性特征,库内实测数据也呈现近似走势。
自由幺半群无论如何调整引理、定理、定义构成的宏指令体系,均不能匹配实测结果。由此判定人类数学体系具备多项式增长属性。
标题核心关键词为压缩,结合偏好度与价值度两项指标,压缩分为两类。归约式压缩依托嵌套定义与引理复用,逐层精简内容篇幅;演绎式压缩以命题完整证明篇幅和精简表述篇幅的比值衡量。
归约式压缩区别于科尔莫戈罗夫复杂度,仅支持局部信息整合,仿照数学定义与引理的归纳模式,识别重复语句并封装为精简宏指令,不会跨片段统筹重组内容。探寻两类压缩方式之间的折中形式,有望打造效率更高的数学架构体系。
目前暂时无法在知识库内划定明确的宏指令集合。团队最初计划筛选关键引理与定义作为核心宏指令,但难以界定评判标准。
物理建模领域也普遍存在这类现象,模型中的抽象概念无法在现实载体中直观对应。量子力学希尔伯特空间、电磁学势场均无法直接观测,只能依托实验佐证存在。若能找出数学体系里类似十进制基数的核心宏指令集合,等同于摸清数学运行底层逻辑,有望推动学科体系重构优化。
本研究并非否定数学推导步骤存在先后次序,核心区分点在于整体增长模式。直观认知里,具备研究价值的内容增速平缓,单纯降低指数参数无法解释体系差异。指数型幺半群只有近乎全覆盖宏指令才能实现压缩,和人类数学特征不符。
随机生成的可证布尔逻辑命题,仅判定算式有无解,缺少抽象推演过程,不属于人类常规数学研究范畴。
偏好度与价值度属于基础评判标准,进一步梳理命题间依存关联,筛选支撑学科发展的关键结论,借助马尔可夫链稳态分布判定内容权重。
依存关系有向图的箭头均指向基础原始元素,直接测算稳态分布意义有限。引入偏好度与价值度的线性组合参数,结合佩龙 - 弗罗贝尼乌斯定理获取唯一稳态权重,原理等同于网页排序算法,以此迭代优化价值评判标准,帮助智能体自主甄别研究重点。
本研究存在两处局限:
MathLib 基于特定底层逻辑搭建,统计结论无法完全代表全部数学样貌;人类数学没有清晰边界,更适合视作渐变范畴,而非割裂的独立集合。
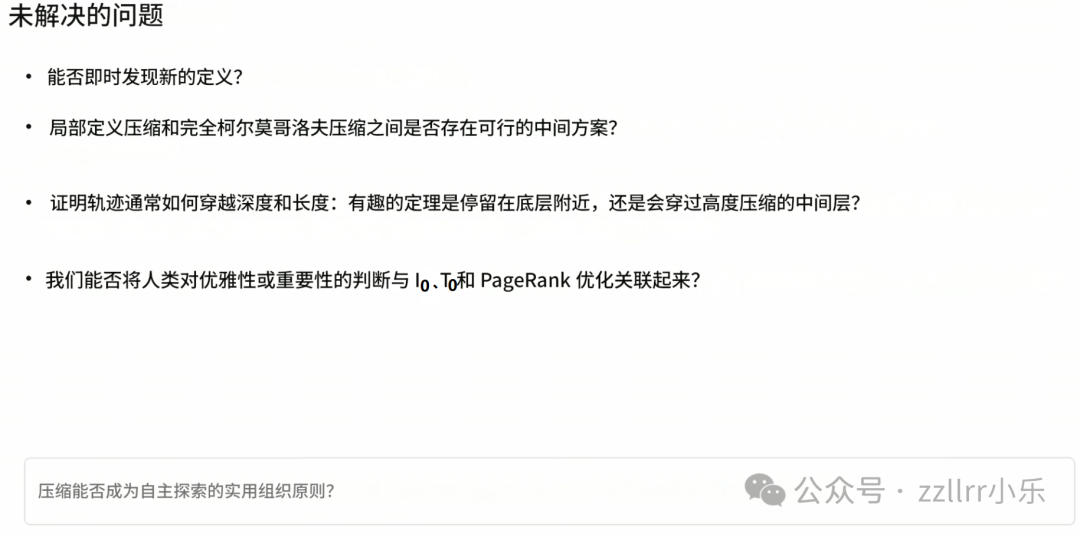
后续研究方向仍待探索:
智能体能否实时归纳全新核心定义;能否打造局部压缩与科尔莫戈罗夫压缩的融合模式;剖析数学整体架构形态;依托体系特征,让智能体自主判断推演方向,规避低效路径。
研究核心结论:
归约式、演绎式两类压缩特征,印证人类数学呈多项式增长态势,库内多数统计规律,和三千年前诞生的位值记数底层逻辑高度相通。
Q&A问答环节
主持人:本场问答环节正式开始,请提问者移步麦克风处发言。
问:格罗滕迪克提出学海演进式数学理念,主张依托概念推演推进研究,他并不认可借助技巧完成证明的方式。定义本身自带压缩属性,未必会体现在证明篇幅上,篇幅悬殊的两份证明或许内核一致。如何界定定义自带的内在压缩特性?
答:嵌套定义是数学研究的必备基础,所有人都无法直接依托原始底层逻辑思考。研究者可以自主搭建概念层级框架,研究方向会影响定义选取,但无法脱离抽象结构开展探索。本次统计中格罗滕迪克相关定理压缩程度极高,理论理念和实际成果并不冲突,定义重构数学体系是普遍客观现象。
问:物理学定理繁多却极少定义,从压缩角度来看,物理学科的压缩机制具备哪些特点?
答:二者压缩逻辑大体相近,均存在多层级抽象压缩结构。物理体系底层精度存在局限,研究难度更高。物理学重整化流程对应数学抽象升级,数学可稳固底层基础,物理微观高能领域的基础规律至今尚未探明。
问:数学研究中存在大量同命题多套证明思路,Lean 证明工具中的推演策略,能否看作直觉与逻辑的压缩形式?如何界定证明过程内部的压缩行为?
答:单一证明思路存在局限性,不同推导方向适配不同拓展场景。知识库目前仅留存单一证明版本,后续需要收录多类证法,搭建完整领域体系库。
问:论文库、学术期刊、数学谱系等不同载体,各自用于数学结构分析的优劣分别是什么?
答:MathLib 优势在于形式化规范,逻辑依存关系清晰。非正规文献需要大量预处理才能开展统计分析。层级架构适配代数、数论领域,泛函分析、偏微分方程很难搭建规整的引理层级体系,部分领域至今未形成适配的标准表述范式,人工智能有望助力体系完善。
问:定理发挥的作用等同于宏指令,为何无法划定明确的宏指令集合?
答:十进制体系拥有统一固定的宏指令标准,数学领域暂无公认界定准则。精简筛选宏指令会出现多种划分方案,不存在唯一标准答案。搭建合理的核心骨架体系,依旧是极具价值的待解课题。
参考资料
https://www.youtube.com/watch?v=4nM82nZzIxU
https://arxiv.org/abs/2603.20396
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

