- +1
谷歌大脑新研究:单一任务的强化学习遇瓶颈?
原创 关注前沿科技 量子位
鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
雅达利游戏,又被推上了强化学习基础问题研究的舞台。
来自谷歌大脑的最新研究提出,强化学习虽好,效率却很低下,这是为啥呢?
——因为AI遭遇了「灾难性遗忘」!
所谓灾难性遗忘,是机器学习中一种常见的现象。在深度神经网络学习不同任务的时候,相关权重的快速变化会损害先前任务的表现。
而现在,这项图灵奖得主Bengio参与的研究证明,在街机学习环境(ALE)的单个任务中,AI也遇到了灾难性遗忘的问题。
研究人员还发现,在他们提出的Memento observation中,在原始智能体遭遇瓶颈的时候,换上一只相同架构的智能体接着训练,就能取得新的突破。
单一游戏中的「灾难性干扰」
在街机学习环境(Arcade Learning Environment,ALE)中,多任务研究通常基于一个假设:一项任务对应一个游戏,多任务学习对应多个游戏或不同的游戏模式。
研究人员对这一假设产生了质疑。
单一游戏中,是否存在复合的学习目标?也就是说,是否存在这样一种干扰,让AI觉得它既要蹲着又要往前跑?
来自谷歌大脑的研究团队挑选了「蒙特祖玛的复仇」作为研究场景。
「蒙特祖玛的复仇」被认为是雅达利游戏中最难的游戏之一,奖励稀疏,目标结构复杂。
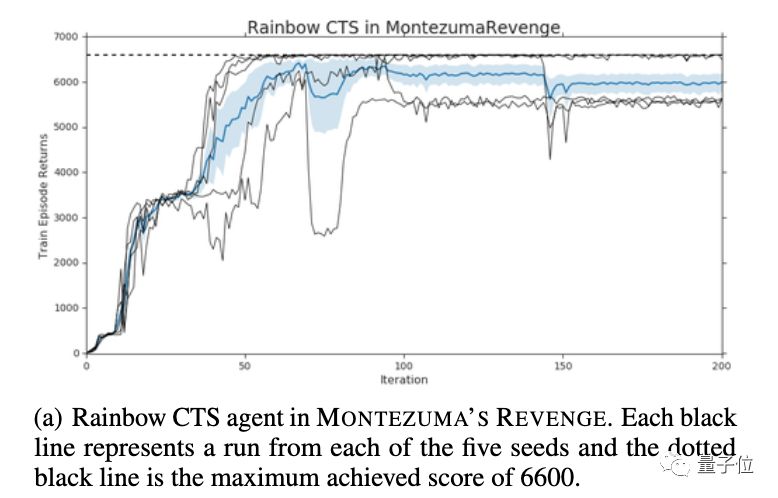
如此再重置一次,AI的最高分就来到了14500分。
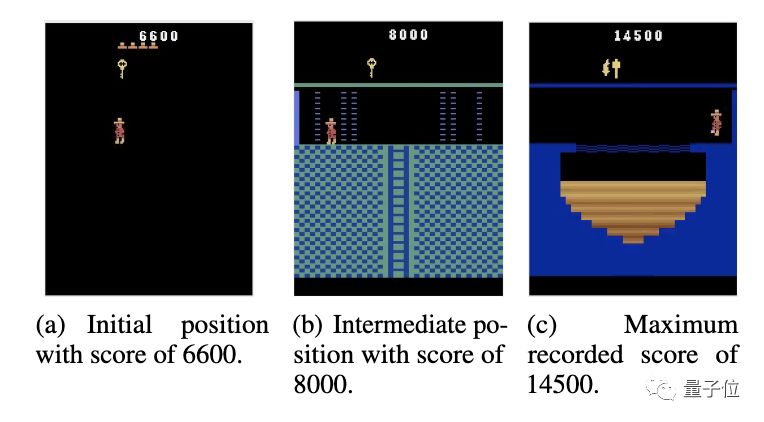
研究人员给这种现象起了一个名字,叫Memento observation。
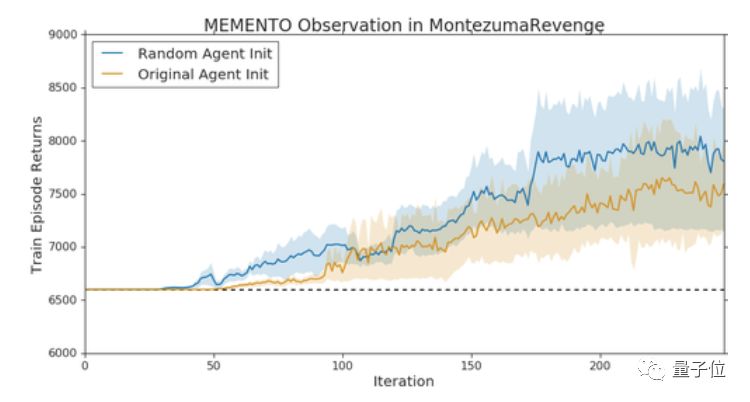
原因是,智能体无法在不降低第一阶段游戏性能的情况下,集成新阶段游戏的信息,和在新区域中学习值函数。
也就是说,在稀疏奖励信号环境中,通过新的奖励集成的知识,可能会干扰到过去掌握的策略。
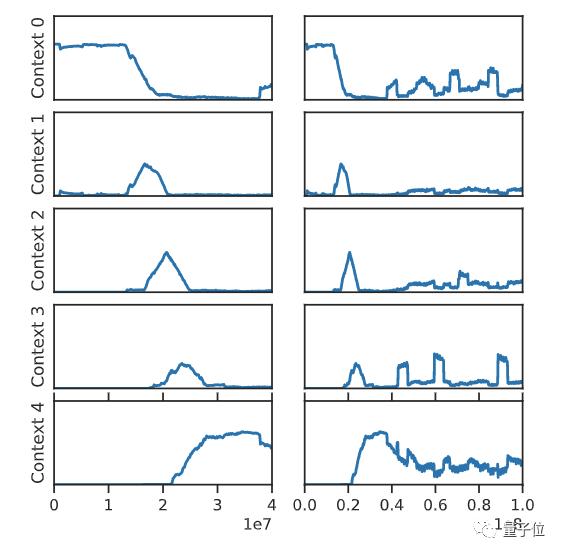
在训练早期(左列),因为尚未发现之后的环节,智能体总是在第一阶段进行独立训练。到了训练中期,智能体的训练开始结合上下文,这就可能会导致干扰。而到了后期,就只会在最后一个阶段对智能体进行训练,这就会导致灾难性遗忘。
并且,这种现象广泛适用。
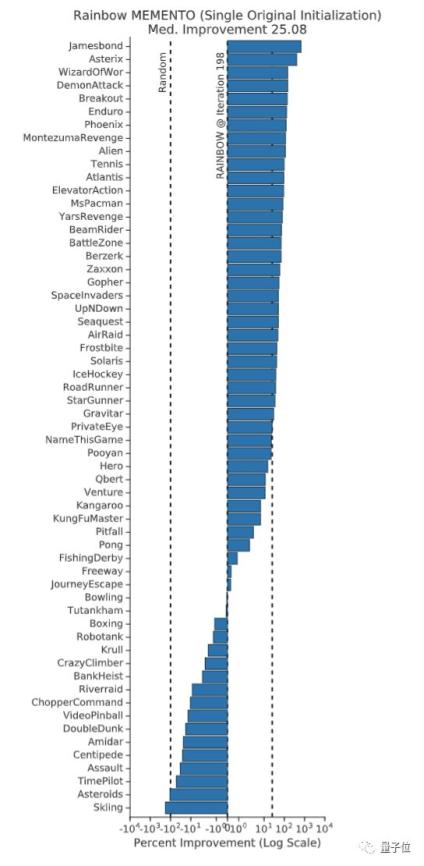
在整个ALE中,Rainbow Memento智能体在75%的游戏中表现有所提升,其中性能提升的中位数是25%。
这项研究证明,在深度强化学习中,单个游戏中的AI无法持续学习,是因为存在「灾难性干扰」。
并且,这一发现还表明,先前对于「任务」构成的理解可能是存在误导的。研究人员认为,理清这些问题,将对强化学习的许多基础问题产生深远影响。
传送门
论文地址:
https://arxiv.org/abs/2002.12499
GitHub:
https://github.com/google-research/google-research/tree/master/memento
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
原标题:《谷歌大脑新研究:单一任务的强化学习遇瓶颈?是「灾难性遗忘」的锅!图灵奖得主Bengio参与》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

