- +1
外卖骑手的困局,算法不背这个锅

《人物》杂志发表了《外卖骑手,困在系统里》一文,文中从外卖骑手的视角出发,探究了目前外卖生态中外卖骑手送餐只能越来越快、越来越不顾自身安全的困局,引起大家对于外卖平台以及其所设计出来的算法的批判,并且在引言中发起一个思考:
数字经济的时代,算法究竟应该是一个怎样的存在?[1]
确实,算法是一个怎样的存在呢?
为了研究外卖平台所使用的算法,我们仔细阅读了一篇由阿里本地生活智慧物流团队发布的论文《Order Fulfillment Cycle Time Estimation for On-Demand Food Delivery》(外卖履约时间预估)[2]。该论文首次比较系统地披露了外卖平台(饿了么)目前采用哪些特征如何设计算法来预估从顾客下单到外卖员送餐到顾客手上所使用的时间,被KDD 2020(数据挖掘领域顶级会议)接收为口头报告论文。
且听我解释。
一、关于算法造成骑手困局的逻辑
《外卖骑手,困在系统里》一文中透露出来的逻辑,或者说大家脑海里关于算法造成骑手困局的逻辑是这样的:

首先,算法根据历史数据决定缩短配送时间,骑手为了避免订单超时只好狂飙、逆行、闯红灯,而骑手的这些举动确实把实际送餐时间缩短了,产生了更多的短时长数据,算法根据这些短时长数据决定再缩短配送时间。这样恶性循环让骑手的配送时间越缩越短,算法让骑手越来越陷入困局。
在这期间,算法只根据餐厅到顾客的直线距离决定骑手配送时间,而不管实际路况、天气状况、餐厅出餐时间、骑手等电梯时间。算法总是以尽可能缩短配送时间为目标。
是这样的吗?
二、算法的目标
首先,我们这里所说的算法,指的是通过历史订单等各种数据,找出影响配送时间的因素及权重,以决定下一次骑手送餐时间长短的方法。
比如说,假如我们只把商家与下订单者之间的距离作为因素,现有3个历史订单数据:1公里内配送时间为15分钟,2公里为30分钟,3公里为45分钟,那么我们根据这些历史订单数据就可以得出一个完美拟合历史数据的算法模型:配送时间 = 距离 * 15。下一个订单如果商家与下订单者之间的距离是1.5公里的话,我们就可以使用这个算法模型预测骑手的配送时间为22分钟30秒。
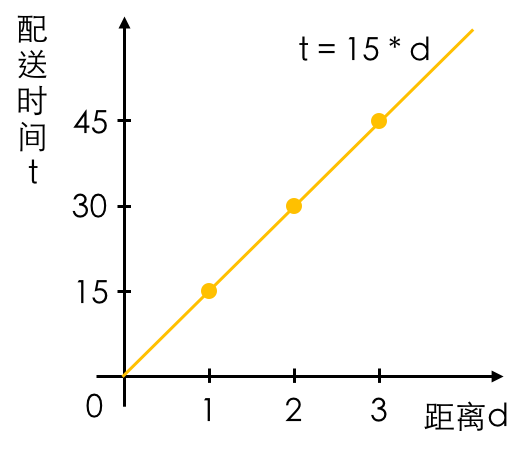
通过《Order Fulfillment Cycle Time Estimation for On-Demand Food Delivery》这篇论文(下称论文)我们知道,饿了么平台是通过设计一个深度神经网络算法来预测订单的配送时间。
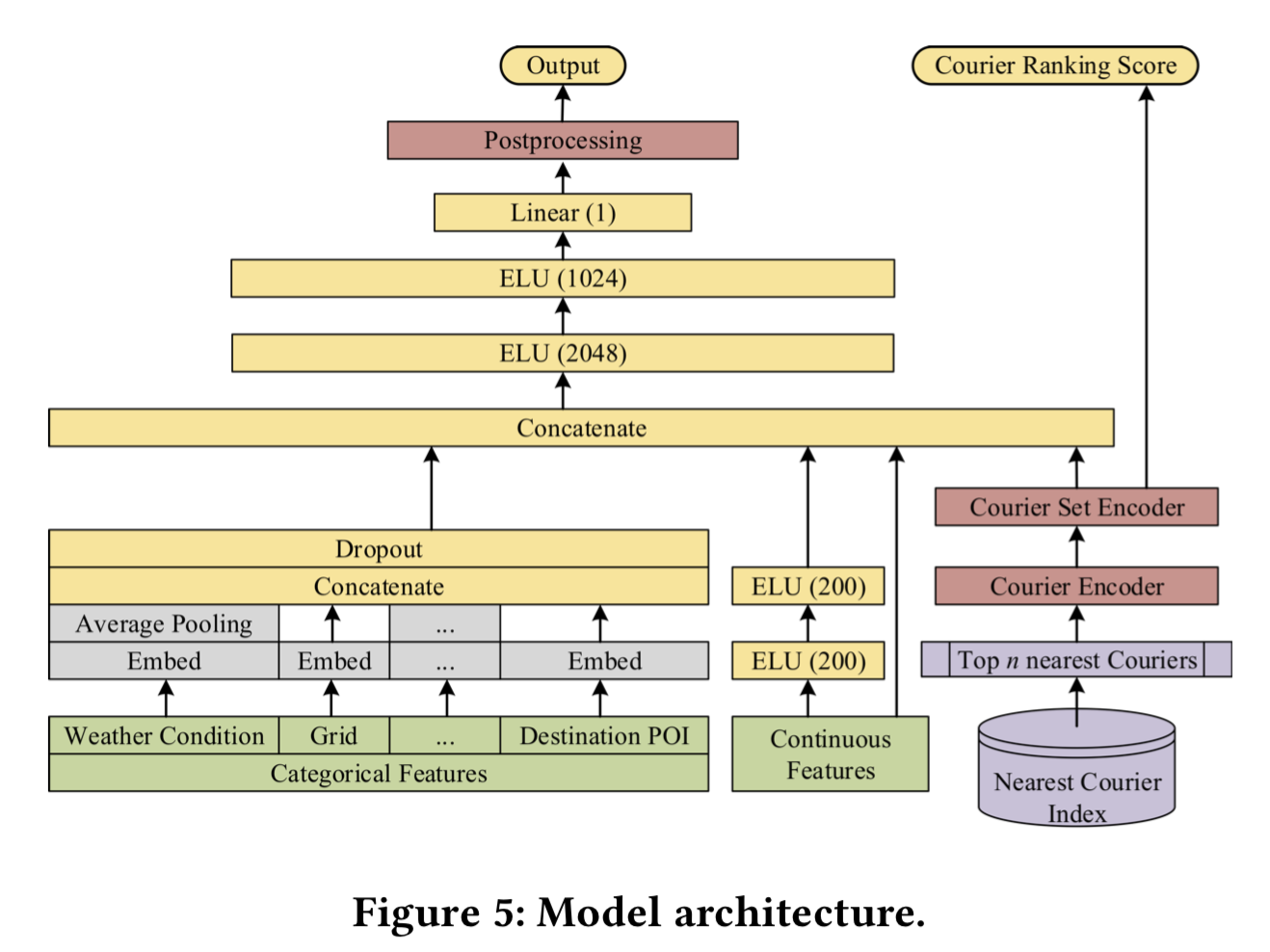
它的做法是选择很多影响配送时间的因素,使用历史数据训练一个深度神经网络,试图找到一组参数让这个深度神经网络算法预测出来的配送时间跟历史订单的配送时间最接近(也就是最小化算法的目标函数),这样算法的预估配送时间就越准确。也就是说,这个算法的目标是如何让算法更加准确地拟合历史数据,而不是尽可能地缩短配送时间。

但是现实中配送时间就是越缩越短呀,这是怎么回事呢?
三、算法是受历史数据影响的
上面说了,算法的目标是更加准确地拟合历史数据,以准确地预测配送所需的时间,所以毋庸置疑,算法是受历史数据影响的。历史数据的结构性变动会影响算法的参数。
回到上面简单的例子,假如现在平台上有两名骑手,自愿或者被动地加快了送餐速度,其中一名骑手送2公里的餐食只用了20分钟,一名骑手送3公里的餐食只用了25分钟,那么对于算法来说,继续使用【配送时间 = 距离 * 15】这个算法模型来预估送餐时间就已经不准确了,它可能会自动学习并调整为【配送时间 = 10 + 距离 * 5】,以更好地拟合新的数据。
这样的话,看下图可知大于1公里的距离,新算法模型的预测配送时间都缩短了。这就是骑手掉入困局的原因。
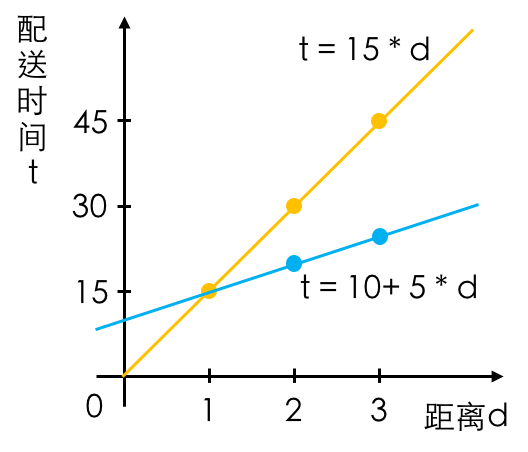
但是这是算法的责任吗?不是的。假如骑手集体延长配送的时间,算法也会更改自身的参数去拟合新的数据,这样新算法模型的预测配送时间都会延长(当然这在实际中几乎不可能发生)。
所以说,这并不是算法的责任,因为它天生的目的就是通过最小化目标函数来拟合历史数据。只是算法的这个特性非常适合被人利用,然后替利用它的人背锅。
四、算法预估配送时间采用的因素
想要准确地根据历史数据来预测配送时间,就必须考虑到各种影响配送时间的因素,然后通过计算机来学习训练出这些因素影响配送时间的权重。因此,饿了么在设计算法时,从历史数据中提取出了很多的因素,这些因素分为以下几类:
1. 订单信息:包括订单的空间因素(用户、餐厅的坐标,城市、配送区块的ID等)、订单的时间因素(小时时刻、是否工作日等)、订单大小(菜品数量和价格等);
2. 聚合因素:包括通过骑手手机的GPS轨迹等计算出来的聚合因素;
3. 菜品因素:比如说拉面、披萨、火锅等不同菜品的种类等;
4. 餐厅备餐时间;
5. 供需关系因素:一是骑手的供需关系(骑手手上的订单越多,送餐越慢)、二是餐厅的供需关系(餐厅手上的订单越多,备餐越慢);
6. 骑手因素:包括骑手到餐厅的距离、骑手目前手上未完成订单数量、订单送达剩余时间等;
7. 多维度相似订单的配送段ETA:配送段预计到达时间即骑手到达用户目的地下车后,把餐食送到用户手中所用的时间,比如说包括骑手等电梯的时间;这部分时间的预估采用K近邻算法找出与之维度相似的若干历史订单,计算加权平均时间;
8. 气象因素:包括气温、空气质量指数、风速、天气状况等;
因此从上面所列的因素看,算法工程师在设计算法的时候,并非没有考虑天气状况、餐厅出餐时间、骑手等电梯的时间。基本上影响外卖履约时间的因素,算法都考虑进去了。
那为什么最后算法给出的预测时间,好像是没有考虑这些因素呢?我们来看看论文中通过历史数据提取这些因素进行训练得出的每组因素的重要程度:
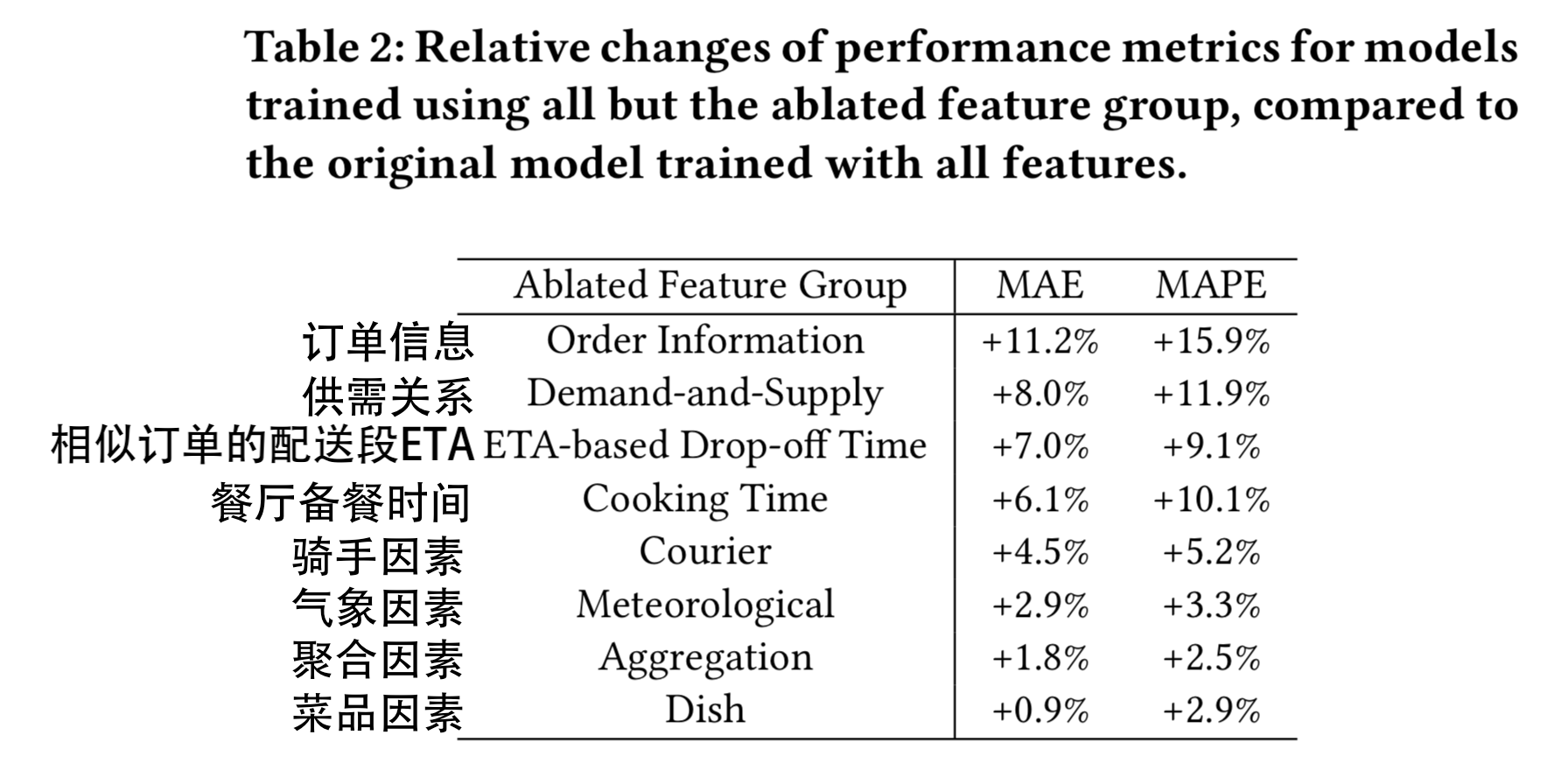
【注:这里每组因素重要程度使用去除掉这组因素导致整个模型的平均绝对误差(MAE)上升百分比来比较,如果一组因素去掉后模型的误差上升越高,说明这组因素对于决定外卖履约时间越重要】
由表可知,订单信息、供需关系两组因素是影响外卖履约时间最重要的因素,而气象因素、聚合因素、菜品因素是通过历史数据学习到的、影响外卖履约时间最不重要的因素。
什么意思呢?意思就是说:算法在设计的时候是考虑了气象、骑手骑行轨迹等因素的,但是骑手通过实际的历史订单数据告诉算法,这些因素对于配送时间并没有太大的影响。
但是怎么会没有影响呢?高温天气、暴雨天气,骑手们的送餐时间跟平常没什么区别,原因是什么呢?就是骑手们为了避免超时,风里来雨里去嘛。
对于这个问题,难道掌握了海量数据的外卖平台不知道吗?既然知道,为什么没有采取措施调整对应的因素权重,而是变本加厉地利用算法去压缩时间呢?
五、责任在谁?
现在我们从算法角度来总结一下:算法的目的是准确预估配送时间,它受历史数据的影响,也考虑了多种因素来预估配送时间。所以说,数字经济时代,算法是没有错的。
那么到底是谁造成了骑手们的困局呢?这就得回到这个循环,从是谁缩短了骑手的配送时间说起。在这里,主要的参与者有外卖平台、骑手和用户三者,我们明白,三者都是逐利的(这无可厚非)。
其中外卖平台是逐利的,因此它会人为地缩短骑手的预计配送时间,利用算法的特性把这个无限循环恶化的游戏玩起来;
骑手也是逐利的,大家都想接更多的单赚更多的钱,所以一开始的时候就有一部分骑手不遵守交通规则开始逆行、闯红灯以缩短配送时间,这迫使算法预估配送时间变短、越来越多的骑手不得不开始逆行、闯红灯,殊不知就这样劣币驱逐良币,开始陷入恶性循环;
用户也是逐利的,大家都想要在更短的时间内拿到外卖,于是对外平台和骑手的配送时间提出了要求。
所以说,对于骑手的困局,外卖平台、部分骑手、用户三者都是有责任的(当然最大的责任方在外卖平台)。而算法只是任人打扮利用、专门背锅的小姑娘。
六、如何破解困局?
那么如何破解目前的这个困局呢?有人说骑手团结起来建立一个工会就能解决,有人说要让外卖平台跟骑手签订劳动合同,这些从不同领域的角度出发的方法或许会有效果,可以留给专业人员去讨论,我们不讨论。
然而甚至有人说要加强程序员的培训和价值导向?试想一群程序员参加完价值导向培训之后回到办公室,加班到凌晨2点,第二天9点之前又通过钉钉打卡来上班,领导批评说模型产生的实际效益还不够好,再把骑手的预估时间缩短几分钟吧,不然你们这个月的绩效就别指望了。这多魔幻现实主义呀。
那么到底如何破解困局呢?在我看来,这还得看这场游戏中到底谁在获利谁在亏损。
外卖平台通过这个游戏提高效率,肯定是获利的;部分骑手一开始是获利的,但是大家都为了时间不顾生命危险拼命赶单时,便是亏损的;用户享受到了非常便捷快速的外卖服务,也是获利的。
还有谁呢?还有就是社会大众。骑手为了省时逆行闯红灯,社会大众徒增了很多道路交通安全上面的危险,是亏损的。涉及到社会大众的问题,使用属于大众的公权力来解决是一个合理的选择。
面对外卖平台,需要有监督和惩罚机制,当惩罚也被列入考虑因素的时候,便能迫使平台去规范自身的行为;
面对骑手,上海推行的电子马甲骑手扣分制,便是一个思路:每个骑手必须穿上印有编号的电子马甲,一个季度内扣完36分不允许再上路。
面对用户,平台应该给予骑手对于用户给差评的申诉机制,以及骑手和用户之间的双向评分机制,避免用户无理要求以及随意给差评。
至于算法,不管是不是数字经济时代,关键的都不是算法,而是资本和人。
引用:
[1] 人物.外卖骑手,困在系统里[EB/OL].https://mp.weixin.qq.com/s/Mes1RqIOdp48CMw4pXTwXw,2020-09-08.
[2] Lin Zhu, Wei Yu, Kairong Zhou, Xing Wang, Wenxing Feng, Pengyu Wang, Ning Chen, and Pei Lee. 2020. Order Fulfillment Cycle Time Estimation for On-Demand Food Delivery. In Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining USB Stick (KDD ’20), August 23–27, 2020, Virtual Event, USA. ACM, New York, NY, USA, 10 pages. https://doi.org/10.1145/3394486.3403307
本文首发于微信公众号“Alfred数据室”,转载请联系原作者!
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

