- +1
Photoshop打包实现AI图像论文,英伟达在实时视频上PS之路上越走越远
选自TechTalks
作者:Ben Dickson
机器之心编译
编辑:Panda
修图靠 Photoshop,修视频靠英伟达。
前段时间,Adobe 推出了一个工具包,将 AI 论文中常见的上色、换表情、改年龄、超分辨率等效果统统打包,集成到了 Photoshop 中,让用户动动鼠标就能用上这些功能。当时就有人问:「视频能 p 吗?」
作为一款主打图像处理的软件,Photoshop 或许没有办法很好地回答这一问题。但同样深耕于计算机视觉、计算机图形学的英伟达用行动告诉我们,他们似乎正在向这一方向努力。
今年 10 月初,英伟达推出了一项 AI 视频会议服务 Maxine,这是一套 GPU 加速的 AI 视频会议软件。该公司将 Maxine 描述为一种「云原生」解决方案,使用了 AI 来提升分辨率、降低背景噪声、压缩视频、对齐人脸以及执行实时翻译和转录。



据了解,开发者、软件合作伙伴和服务提供商已可申请 Maxine 的早期使用权。
本文将解读 Maxine 的多项功能的工作机制以及它们与英伟达 AI 研究的关联。本文也会谈到英伟达的 AI 驱动型视频会议平台中仍待解决的问题和可能的商业模式。
使用神经网络实现超分辨率
在展示 Maxine 时,英伟达介绍的第一个功能是「超分辨率」,英伟达说这「能实时地将低分辨率视频转换为高分辨率视频」。超分辨率技术能让视频会议参与者发送低分辨率视频流,而服务器能让它们变得更加清晰。这能降低视频会议应用的带宽需求,能让它们在网络连接不稳定的地区也能获得更稳定的表现。
提升视觉数据分辨率的一大挑战是如何填充缺失的信息。打个比方,你有一张由一定数量像素构成的图像,你想要将其扩大为包含更多像素的图像。你该如何确定这些新像素的颜色?

机器学习的一大优势是能在经过调节之后用于非常特定的具体任务。举个例子,基于视频会议流数据,深度神经网络可使用缩小后的视频帧及其对应的高分辨率原图像进行训练。只要样本充足,该神经网络就能根据在视频会议视觉数据(大多是人脸)中找到的一般特征调节其参数,从而能在低到高分辨率转换任务上取得比通用型放大算法更优的表现。一般来说,领域范围越狭窄,神经网络就越有可能收敛到非常高的准确度。
使用人工神经网络来放大视觉数据已经有了坚实的研究基础,其中包括英伟达 2017 年的一篇论文,其中讨论了使用深度神经网络的通用型超分辨率技术。
由于视频会议是一种非常特定的具体案例,因此经过良好训练的神经网络在该任务上的表现肯定会优于更一般化的任务。除了视频会议之外,超分辨率技术还有其它应用场景,比如电影行业可以使用深度学习来重制老电影,使其质量更高。
使用神经网络实现视频压缩
在 Maxine 展示中,AI 视频压缩是一个更有趣的部分。英伟达发在 YouTube 上的视频展示了使用神经网络来压缩视频流可将带宽从约 97 KB / 帧降至约 0.12 KB / 帧。不过有 Reddit 用户指出,这实在有点夸张。英伟达网站表示开发者可将带宽用量「降至 H.264 视频压缩标准所需带宽的十分之一」,这听起来要合理多了,但仍旧是一个惊人的数字。
英伟达的 AI 何以实现了如此惊人的压缩率?该公司一篇博客文章更详细地解释了这项技术的工作细节:https://blogs.nvidia.com/blog/2020/10/05/gan-video-conferencing-maxine/
神经网络可以提取和编码每帧中用户的关键人脸特征的位置,这比压缩像素和颜色数据要有效得多。之后,已编码的数据和一开始获取的参照视频帧会被传输给一个生成对抗网络。而这个 GAN 的训练目标是通过将人脸特征投影到参照帧上来重建新图像。
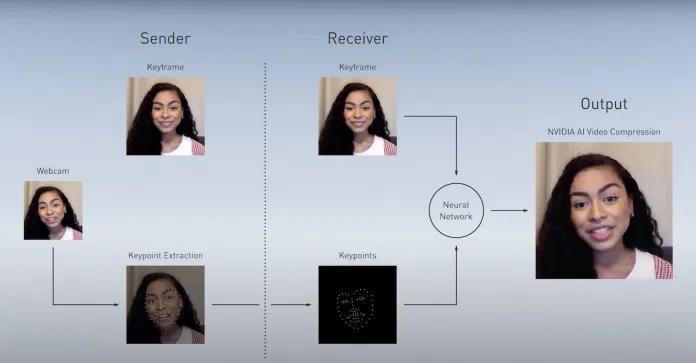
AI 视频压缩再次表明:当领域狭窄时,深度学习算法能取得格外出色的表现。
使用深度学习的人脸对齐
人脸对齐是指通过调整用户人脸的角度,使之看起来就像是正对摄像头一样。人脸没对齐是视频会议中的常见问题,因为人们往往会看着屏幕上其他人的脸,而不是盯着摄像头。
尽管英伟达没有透露太多细节,但他们的博客提到过他们在使用 GAN。不难想见,这个功能可以与 AI 压缩 / 解压技术绑定到一起。英伟达已经在人脸特征点检测和编码方面进行了广泛的研究,其中包括提取人脸的特征和不同角度的注视方向。这些编码可以输送给同一个可将人脸特征投射到参照图像的 GAN,然后让其完成剩下的所有工作。
Maxine 的深度学习模型是如何运行的?
Maxine 还有许多其它实用的功能,包括整合了英伟达的会话 AI 平台 JARVIS。但这里就不再详述了。
不过,该软件仍有一些技术问题尚未得到解决。举个例子,我们还不清楚 Maxine 中有多少功能运行在英伟达的服务器上,又有多少运行在用户设备上。英伟达一位发言人在回答 TechTalks 的提问时说:「英伟达 Maxine 的设计目标是在云端执行 AI 功能,这样无论用户使用怎样的设备,每个用户都能使用它们。」
对超分辨率、虚拟背景、自动对齐和降噪等功能而言,这种做法是合理的。但另一些功能放在云端就毫无意义了。AI 视频压缩就是显而易见的例子。理想情况下,执行人脸表情编码的神经网络必须运行在发送端设备上,而重建视频帧的 GAN 又必须运行在接收端设备上。如果所有这些功能都交给服务器执行,那么就无法节省带宽,因为用户发送和接收的都将是完整的视频帧,而不是更轻量的人脸表情编码。
理想情况下,英伟达应该提供某种配置机制,让用户可以自己根据自己的网络和计算设备选择本地和云端 AI 推理的适当平衡。举个例子,如果某用户有一个带有强大 GPU 的工作站,那么他可能就希望完全在自己的计算机上运行所有深度学习模型,以便降低带宽用量并降低成本。另一方面,如果用户使用计算能力有限的移动设备加入会议,则他可以选择放弃本地 AI 压缩,并将虚拟背景和降噪任务交给 Maxine 服务器执行。
Maxine 的商业模式
我们也有理由相信 Maxine 能在其它产品失败之处取得成功。首先,英伟达在深度学习方面有着可靠的研究历史,尤其是在计算机视觉和更近期的自然语言处理领域。该公司也具有足够的基础设施和资金来继续推进 AI 模型的研发并将其提供给客户。当用户基数增大时,英伟达的 GPU 服务器及其云供应商合作伙伴也有能力扩大规模。另外,英伟达近期对 ARM 的收购也让其有机会将这些 AI 能力部署到边缘设备上。(也许未来会有 Maxine 驱动的视频会议摄像头产品?)
最后,Maxine 是善用专用 AI 的绝佳范例。不同于试图解决广泛问题的计算机视觉应用,Maxine 的所有功能都是针对特定场景设计的:一个人对着一个摄像头说话。很多实验已经表明,当问题的领域范围扩大时,即使最先进的深度学习算法也会损失准确度和稳定性。反过来,当问题的领域范围缩小时,神经网络更有可能接近真实的数据分布。
不过我们也知道,有效的技术与成功的商业模式之间存在巨大的差异。
Maxine 目前正处于早期访问模式,所以未来还可能会有巨大的变化。目前来看,英伟达计划提供 SDK 以及托管在其服务器上的一套 API,让开发者可以将其整合进自己的视频会议应用中。企业视频会议行业已经有两大玩家了:Teams 和 Zoom。Teams 已经有大量 AI 驱动型功能了,微软也不难继续添加 Maxine 提供的功能。
Maxine 最终将采用怎样的定价模式?带宽节省的效益足够弥补其成本吗?Zoom 和微软 Teams 等大型玩家是否有与英伟达合作的动力,还是说他们更愿意自己开发同样的功能?英伟达会继续当前的 SDK/API 模式还是会开发自己的独立视频会议平台?在开发者探索这个新的 AI 驱动型视频会议平台时,英伟达必须解答这些问题以及其它许多问题。
原文链接:https://bdtechtalks.com/2020/10/19/nvidia-maxine-ai-video-conferencing/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com喜欢此内容的人还喜欢
原标题:《Photoshop打包实现AI图像论文,英伟达在实时视频上PS之路上越走越远》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

