- +1
疫情下的数据叙事 | 2020数据创作者大会演讲实录①
 9月17日下午,由澎湃新闻主办的“2020数据创作者大会”在上海成功召开,百余位数据领域实践者齐聚一堂,共同探讨“疫情下的数据表达”这一话题,继2019年首届数据创作者大会后,再次挖掘数据背后的无限可能。
9月17日下午,由澎湃新闻主办的“2020数据创作者大会”在上海成功召开,百余位数据领域实践者齐聚一堂,共同探讨“疫情下的数据表达”这一话题,继2019年首届数据创作者大会后,再次挖掘数据背后的无限可能。大会首次发布《2020疫情数据报道分析报告》,并围绕“疫情数据的传播与叙事”和“疫情之后,数据叙事如何持续发挥影响力”两大话题展开讨论,本文为大会干货的第一篇——疫情数据的传播与叙事。
2020数据创作者大会沿用去年的模式,引入了美国数据新闻年会NICAR大会的王牌环节——Lightening Talk。六位分享者以八分钟迷你演讲,从不同切口探讨数据在抗疫中如何发挥作用。他们,有的是奋战在抗疫一线的流行病学调查专家,有的是机构媒体数据新闻工作者,有的是研究人员,还有仍在校园中的个人创作者,和为媒体提供数据解决方案的专业人士。
 像“破案”一样操作一次流行病学调查
像“破案”一样操作一次流行病学调查 流行病学调查(简称“流调”)有点像公安破案,破案需要技术,流调也需要技术,而我们的技术就是来自由上海市卫健委和上海市疾控中心制定的五个版本的流调方案。疾控中心的人员是参与流调的“主力军”,一线的医生和护士则是“同盟军”,这种医治与防控的融合使流调得以顺利实施。
流行病学调查(简称“流调”)有点像公安破案,破案需要技术,流调也需要技术,而我们的技术就是来自由上海市卫健委和上海市疾控中心制定的五个版本的流调方案。疾控中心的人员是参与流调的“主力军”,一线的医生和护士则是“同盟军”,这种医治与防控的融合使流调得以顺利实施。 流行病学调查包括哪些内容?
活动轨迹表明这个病人是怎么得病的,得了病后是怎么传播的。对流调人员而言,病人活动轨迹的时间单位不仅仅是“天”,甚至精确到了小时和分钟。例如一个人在13:20抵达医院,13:21进入医院大厅,13:23到达急诊室,三分钟里转换了三个场所,遇到不同的人。这些人都有被传染的可能,所以活动轨迹的时间颗粒度必须非常细。
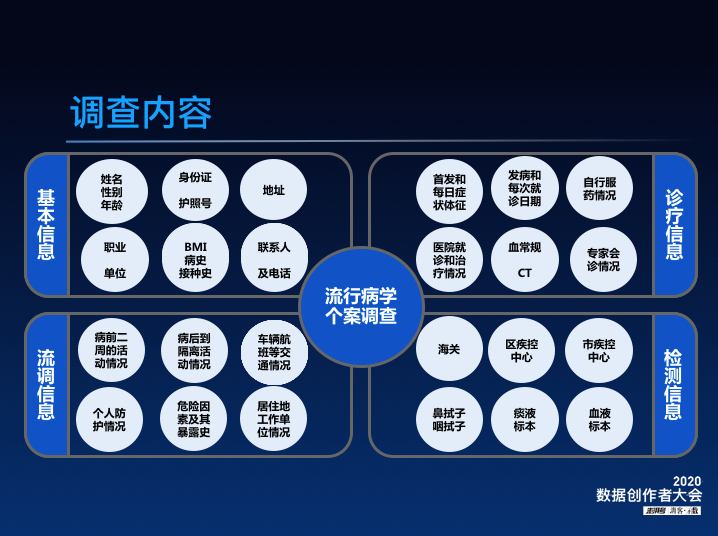 活动轨迹不是流调的全部,流行病学调查还包括“基本信息、诊疗信息、流调信息和检测信息”。病人去过哪些医院,如何接触医生和护士,是防止医护感染的重要依据。而狭义的流调信息,包括如何得病、如何传播、如何切断,对我们防范疾病的传播非常重要。另外有了实验室的检测信息,才能对病毒有更深入的了解。
活动轨迹不是流调的全部,流行病学调查还包括“基本信息、诊疗信息、流调信息和检测信息”。病人去过哪些医院,如何接触医生和护士,是防止医护感染的重要依据。而狭义的流调信息,包括如何得病、如何传播、如何切断,对我们防范疾病的传播非常重要。另外有了实验室的检测信息,才能对病毒有更深入的了解。 流行病学调查的难点
流调也有难点。一是回忆偏倚和陌生人接触,仅靠回忆很难把跨省跨区的密切接触者找出来。如果我随便问一位观众,两周前你坐了什么交通工具,14天前吃了什么东西?我想在座的各位都回答不出来。但我们可以通过排查不同的场所,包括家庭、医院和公共场所等,帮助被调查对象回忆,还可以依靠铁路部门、轨交部门,甚至邻里亲朋的协助。所以推动流行病学调查不仅仅依靠我们一支队伍,而是整体联防联控、互相合作的结果。
二是语言,如果面对一个语言不通的病人,调查也很困难。我们组建了针对英语的流调队伍,配备外语翻译设备,还有多语种的志愿者。实在没有办法的时候,可以请求外事部门协助。
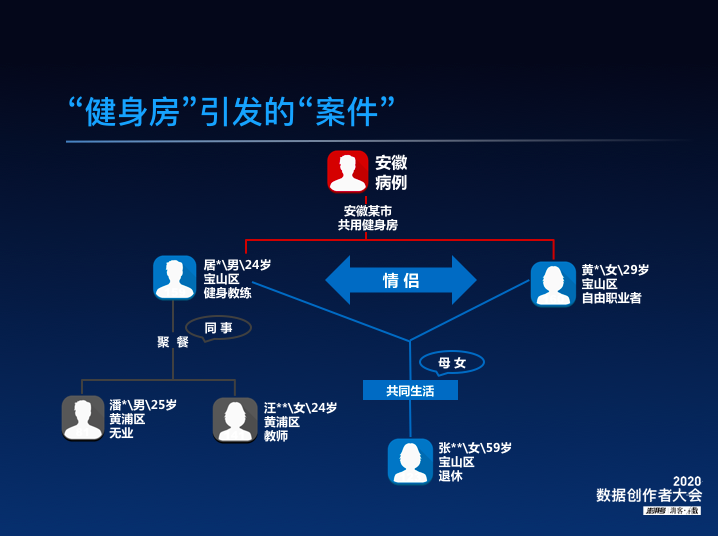 三是复杂案情,复杂的案情最烧脑,最难搞清楚病毒是怎么传播的。上图灰色部分表示黄浦区的疫情,蓝色部分表示宝山区的疫情。某一个深夜的12点,我们进行了大会诊,把这两个根本不相关的疫情联系起来。病人都没有去过武汉,是怎么得病的?我们最后锁定在安徽省,两位病人在安徽省的活动非常复杂,有婚礼、商务活动、大小聚餐,最后我们通过流调锁定到一个健身房,健身房空间密闭,并且所有的器械共用,符合疫情传播的假设。非常巧合的是,第二天安徽的某相关部门,也公布了在这个健身房里发现了5-6个病人,有400多个该健身房暴露人员,印证了我们的假设。这样的案例很多,比它复杂的案例也有不少,时间关系不再多说。
三是复杂案情,复杂的案情最烧脑,最难搞清楚病毒是怎么传播的。上图灰色部分表示黄浦区的疫情,蓝色部分表示宝山区的疫情。某一个深夜的12点,我们进行了大会诊,把这两个根本不相关的疫情联系起来。病人都没有去过武汉,是怎么得病的?我们最后锁定在安徽省,两位病人在安徽省的活动非常复杂,有婚礼、商务活动、大小聚餐,最后我们通过流调锁定到一个健身房,健身房空间密闭,并且所有的器械共用,符合疫情传播的假设。非常巧合的是,第二天安徽的某相关部门,也公布了在这个健身房里发现了5-6个病人,有400多个该健身房暴露人员,印证了我们的假设。这样的案例很多,比它复杂的案例也有不少,时间关系不再多说。流行病学调查为什么如此重要?
流行病学为什么重要?一可以查明原因,避免市民患病;二是有利于切断传播,隔离密接接触者,防止疫情扩散。
“如果将新冠疫情比作洪水,疾控战士则是城市的守坝人”, 接近2000万人口的纽约州有48万新冠确诊病例,而上海市拥有2400万人口,有九百多例新冠确诊病例(包括境外输入病例)。这样的比较一目了然,是流行病学调查让疫情的切断成为可能。
 用美的方式收集思念:建造一座数字纪念馆
用美的方式收集思念:建造一座数字纪念馆
财新数据可视化实验室负责人 韦梦
人们需要一座纪念馆
我要分享的这个项目叫做“用美的方式收集思念”,关于如何建造一座纪念疫情中逝者的数字纪念馆。这个纪念馆不仅仅是为逝者,更是为活着的人有一个地方去寄托思念。项目的两个核心问题—谁值得被纪念,以及谁会去纪念。
谁值得被纪念?
纽约911事件的数字纪念馆没有用国籍、职业或者姓名首字母给逝者排序,而是依据他们当时在飞机上的座位进行排序,这是一个非常平等的呈现方式。
 在寻找哪些人值得被纪念的过程中,我们做了理念层面上的改进,从“someone”(有的人)模式转变到“everyone”(每个人)模式。之前,我们会摘取一些被新闻报道过的人的名字收录到纪念者清单中,但转换成“everyone”模式之后,我们便尝试平等地记录每个逝者。
在寻找哪些人值得被纪念的过程中,我们做了理念层面上的改进,从“someone”(有的人)模式转变到“everyone”(每个人)模式。之前,我们会摘取一些被新闻报道过的人的名字收录到纪念者清单中,但转换成“everyone”模式之后,我们便尝试平等地记录每个逝者。谁会去纪念?
有一个关于阿尔茨海默症的网站叫“I-remember”,呼吁每个网友把记录自己生命中真实时刻的图片和文字上传到这个网站。我希望这个项目也可以实现从编辑收录名单到读者自发提供的过程。即使只有一两个读者自发给我们提供线索,我也觉得非常满足,这就是我想做这个项目的初心。还有一点遗憾,因为内容审核和核实的困难,没有真正做成一个UGC(用户生成内容)的项目。
寻找代表着美、生命与逝去的意象
有了理念上的准备以后,在具体设计这个项目时,我想寻找整体上很美、又可以表达出生命逝去的意象,最终花瓣成为了这个项目的原始素材。
 我们用位置、坐标和旋转角度的参数来控制每一个花瓣的形态,实现在花瓣中穿梭的感受。点击任何一片花瓣,都会有相应逝者的详细信息跳出。最终的主界面就是这样一个花瓣雨。这里面有一个小巧思,如果逝者是一家人,屏幕上会以一朵花的形式来呈现。
我们用位置、坐标和旋转角度的参数来控制每一个花瓣的形态,实现在花瓣中穿梭的感受。点击任何一片花瓣,都会有相应逝者的详细信息跳出。最终的主界面就是这样一个花瓣雨。这里面有一个小巧思,如果逝者是一家人,屏幕上会以一朵花的形式来呈现。我们想让这个作品更有人情味,也希望这个作品能更具有国际视野,所以除了中国的逝者以外,也可以链接到海外,因为海外的死亡人数相应多一点。
 疫情期间,如何找出制造假消息的人?
疫情期间,如何找出制造假消息的人?
澎湃新闻数据记者 陈良贤
疫情期间,谣言满天飞
今年三月,澎湃新闻美数课栏目做了一篇聚焦海外疫情谣言的新闻,以微观视角看批量造假的信息。接下来我给大家分享怎样以“切片”的方式抓住谣言制造者。
疫情中产生的谣言非常多,例如“喝白酒、吃大蒜可以预防感染病毒”,“吃海鲜容易感染新冠病毒”,“谈恋爱可以预防新冠病毒”等等。有的谣言大家一笑而过,不会当真,但有些不实信息却造成了很恶劣的影响。
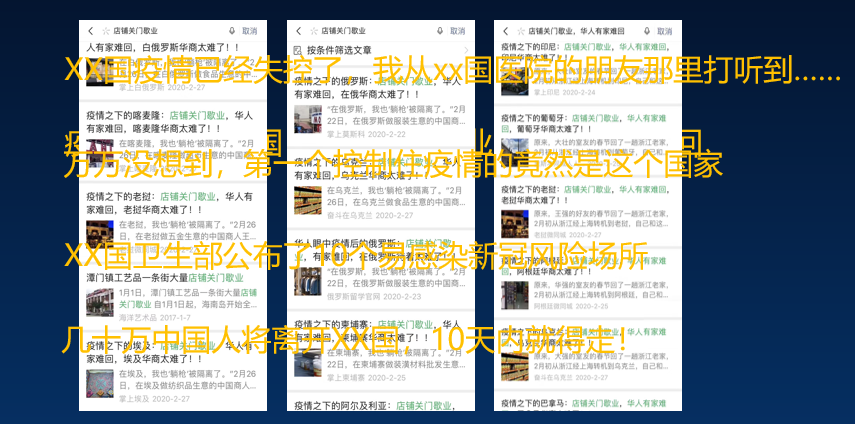 海外疫情暴发之后,关于国外的谣言也变多了,比如“某某国的疫情已经失控了”,“我从某某国医院的朋友那里听到了”,说得头头是道,其实都是谣言。
海外疫情暴发之后,关于国外的谣言也变多了,比如“某某国的疫情已经失控了”,“我从某某国医院的朋友那里听到了”,说得头头是道,其实都是谣言。 给疫情谣言做切片:聚焦一则谣言
 我们想通过梳理谣言的出处还原它到底是怎么来的。一番查找后,发现许多发布消息的微信公众帐号都有相似的名字,查证后发现这一系列公众号背后都是一家福清系的公司,一样的运作模式,只是把名字、人名和国名替换,从而达到了批量生产的效果。
我们想通过梳理谣言的出处还原它到底是怎么来的。一番查找后,发现许多发布消息的微信公众帐号都有相似的名字,查证后发现这一系列公众号背后都是一家福清系的公司,一样的运作模式,只是把名字、人名和国名替换,从而达到了批量生产的效果。谣言制造机们是如何批量生产文章的?
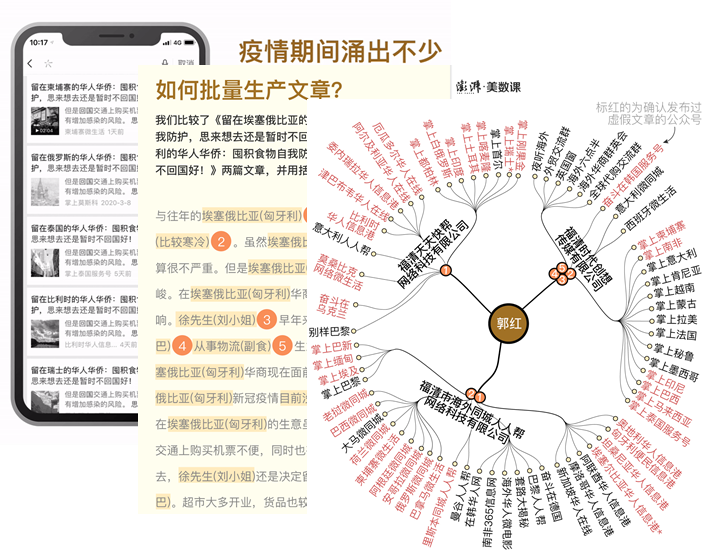 图中呈现的是以郭红为圆心形成的一个庞大矩阵,仅凭一个人炮制朋友圈所有的“世界失控”。
图中呈现的是以郭红为圆心形成的一个庞大矩阵,仅凭一个人炮制朋友圈所有的“世界失控”。 跑在事实前面的假消息,它们的批量生产还在继续
这些批量造假的谣言,是疫情之后才有的吗?在调查这一系列公众号的时候,我们发现在疫情出现以前,造谣者也在通过批量造假的方式发布文章。疫情起了催化剂的作用,使谣言制造加速,变得更加夸张和耸人听闻。假消息的批量生产还在继续,有些甚至引发了外交风波。
“新闻的首要目标是向人们提供能自由、自我决策的信息。”数据报道对于调查、核实、辟谣和科普方面做了贡献,及时提供准确的信息对于避免民众恐慌、做出正确的防疫举措具有非常重要的意义。
 政府如何发布、开放和利用新冠疫情数据?
政府如何发布、开放和利用新冠疫情数据? 
复旦大学数字与移动治理实验室研究员 吕文增
从公共管理视角看疫情数据
疫情数据发布后,我们站在管理角度,以公共视角研究新冠疫情数据的发布、开放和利用。政府的开放数据如果不涉及到国家安全、个人隐私和商业机密,应该以无条件或者有条件的方式开放。那在疫情暴发之后,政府如何披露疫情相关的数据?
 今年三月份,我们发布了《我国省级地方政府新冠疫情数据发布研究报告》,从疫情通报的专栏采集了疫情通报类的信息,同时在地方政府的公众号上进行了批量采集。
今年三月份,我们发布了《我国省级地方政府新冠疫情数据发布研究报告》,从疫情通报的专栏采集了疫情通报类的信息,同时在地方政府的公众号上进行了批量采集。数据的时效性、全面性、持续性
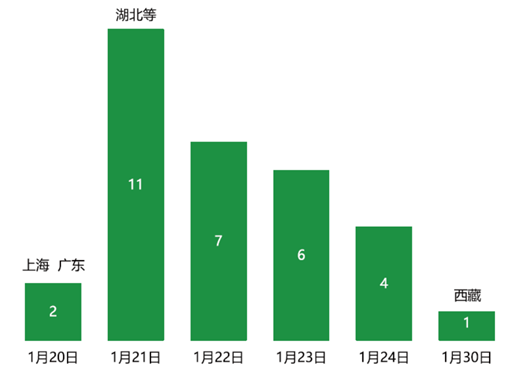 疫情统计数据的时效性指的是各个地方省级政府对疫情反应时间的长短,比如什么时候开始在卫健委官网上发布疫情数据。最早披露数据的是广东和上海,甚至比武汉还要早一天。西藏最晚,1月30号才开始披露疫情数据。
疫情统计数据的时效性指的是各个地方省级政府对疫情反应时间的长短,比如什么时候开始在卫健委官网上发布疫情数据。最早披露数据的是广东和上海,甚至比武汉还要早一天。西藏最晚,1月30号才开始披露疫情数据。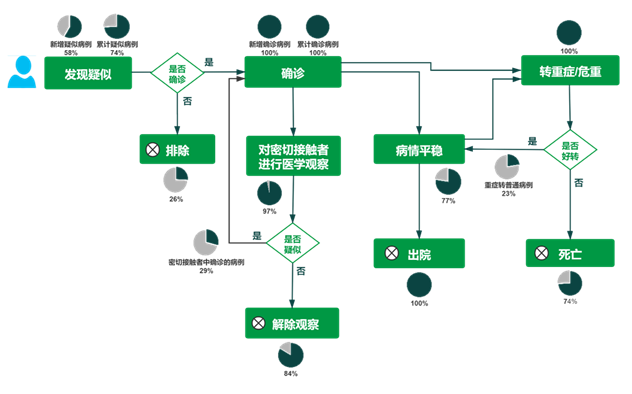 疫情统计数据的全面性体现在疫情发展周期中的数据披露情况。从发现疑似病例到确诊、进行流调,研究密切接触者,直到确诊病人病情发展情况。
疫情统计数据的全面性体现在疫情发展周期中的数据披露情况。从发现疑似病例到确诊、进行流调,研究密切接触者,直到确诊病人病情发展情况。 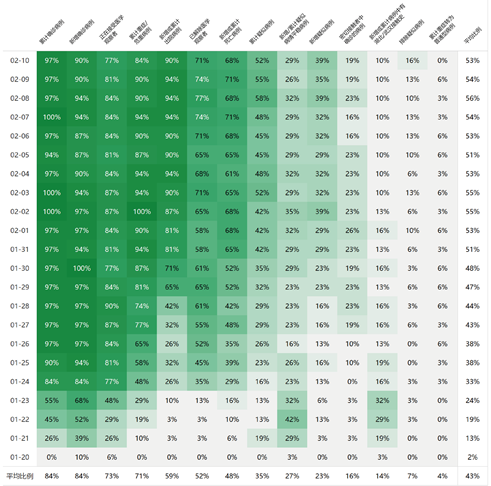
 疫情统计数据的持续性指全国31个省级政府中,每天有多少地方政府披露了相应的指标。我们做了这样一张热力图,从1月20号到2月10号,发布数据比例最高的在前面。基本大多数地方政府都发布了确诊病例、疑似病例,以及这些病例和武汉的病例有没有接触等信息。越往后发布的比例越少,颜色越深,说明地方政府发布数据的比例越高。
疫情统计数据的持续性指全国31个省级政府中,每天有多少地方政府披露了相应的指标。我们做了这样一张热力图,从1月20号到2月10号,发布数据比例最高的在前面。基本大多数地方政府都发布了确诊病例、疑似病例,以及这些病例和武汉的病例有没有接触等信息。越往后发布的比例越少,颜色越深,说明地方政府发布数据的比例越高。 在疫情初期,很多地方政府也在摸索,从一开始只披露确诊、疑似等等这些简单的数据,到发布关于病人病情、排除密切观察者等数据。3月10号之后,由于疫情的严重程度已经降低,披露的数据也有所减少。
公开率与精细度
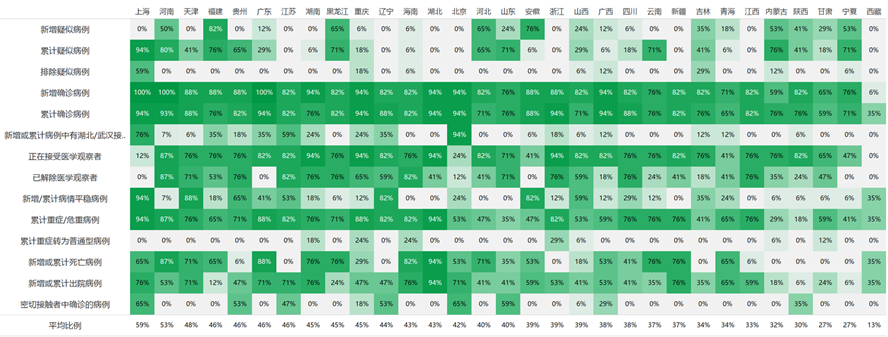
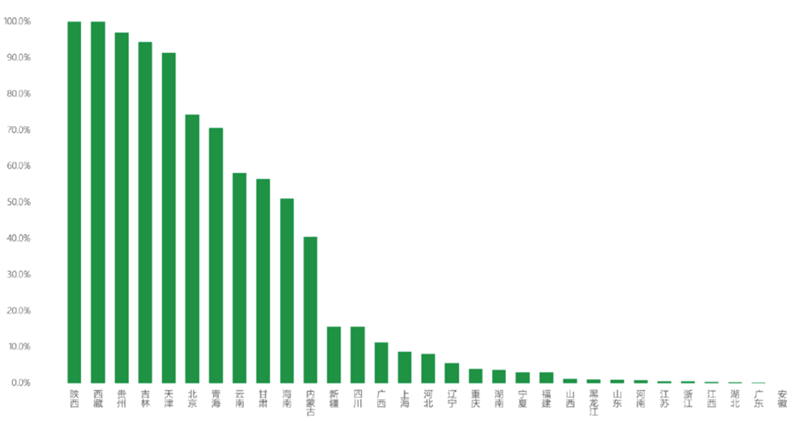 疫情数据的公开率建立在对病例个案数据的研究之上。比如今天新增10个确诊病例,这10个个案的情况有没有披露出来?他们的住址区域有没有公布?总体来看,陕西、贵州、吉林、天津等地在官网上披露的个案数据比例更高,湖北披露的比例反而比较低。
疫情数据的公开率建立在对病例个案数据的研究之上。比如今天新增10个确诊病例,这10个个案的情况有没有披露出来?他们的住址区域有没有公布?总体来看,陕西、贵州、吉林、天津等地在官网上披露的个案数据比例更高,湖北披露的比例反而比较低。 在精细度方面,我们基于定性研究建立了一个框架,研究地方政府披露信息的丰富程度。
在精细度方面,我们基于定性研究建立了一个框架,研究地方政府披露信息的丰富程度。形成数据开放利用的良性生态系统
 大多数公众对数据是不了解的。擅长利用数据的人去依靠政府的开放数据,开发一些有趣好玩的APP,如果这些APP对社会公众有益,那数据就产生了增值,他们会要求政府开放更多的数据,从而形成一个动态的循环。在疫情数据领域,我们希望形成一个数据从快速利用,到对社会有帮助,再到开放更多数据的良性生态系统。
大多数公众对数据是不了解的。擅长利用数据的人去依靠政府的开放数据,开发一些有趣好玩的APP,如果这些APP对社会公众有益,那数据就产生了增值,他们会要求政府开放更多的数据,从而形成一个动态的循环。在疫情数据领域,我们希望形成一个数据从快速利用,到对社会有帮助,再到开放更多数据的良性生态系统。  一个人像一支队伍:个人创作者如何参与疫情报道
一个人像一支队伍:个人创作者如何参与疫情报道
北京大学汇丰商学院研究生 赵鹿鸣
疫情期间,我创作的三篇作品
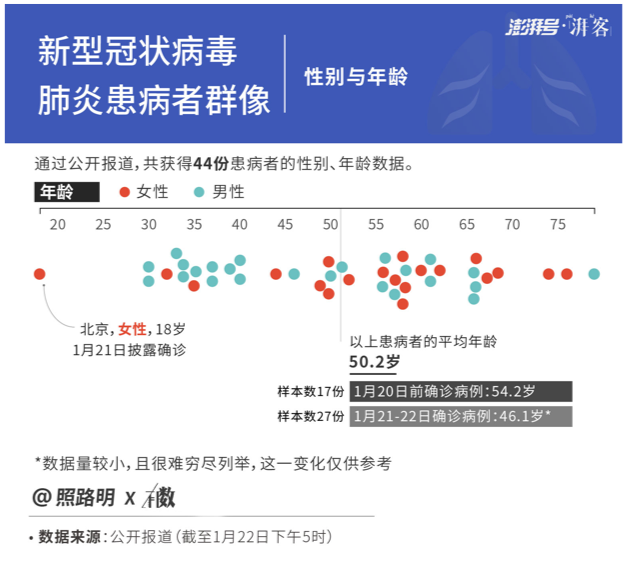
我是赵鹿鸣,来自北京大学汇丰商学院。个人创造者和团队创作者有何相同与不同之处?接下来我会具体分析。1月到2月期间,我在澎湃新闻湃客·有数栏目上发表了三篇作品,第一篇是《新型冠状病毒肺炎病例群像:何时发病,多大年龄,在哪分布?》,发布于1月23号。在当时,这些病例描述是非常可贵的数据集,所以我尝试对它进行编码处理,以获得一些基本结论。
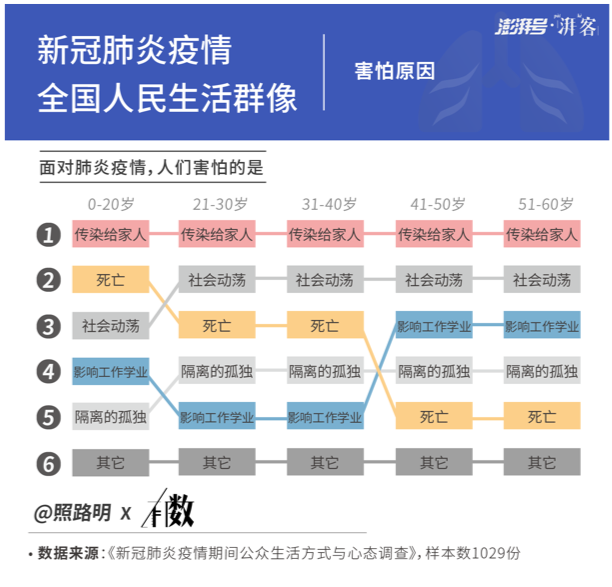
第二个作品是《被新冠肺炎困在家中的中国人,这几天都在干什么?》,于1月29号发布。1月份的时候,大家在家里宅了差不多一个星期,我们想讨论中国人在家里做什么,会有怎样的情绪状态。比较让人感动的一点是,不同年龄段人最大的担忧都在于害怕传染给家人。

第三个作品是在2月10号发布的《后疫情时代:我们如何被新冠肺炎改变了生活?》,当时疫情已经持续了快一个月,我们想了解它给普通人带来什么影响。在策划这篇作品时,我想让武汉市民讲讲自己的故事。但这会面临非常多的数据伦理问题,所以最后我还是把文章重点放在了经济影响方面。
一个人做意味着什么?
一个人创作的时候,会面临很多问题,例如我该怎么做,写作流程怎么安排,作品的规范性在哪里等等。当然也有很多好的方面,比如快速决策,面临重大公共危机时,时效性非常关键。
 第二个好处就是全方位的业务锻炼。第三个优势是创作起来很“爽”。我除了做数据新闻,其他时间都在工作和写论文,相比之下,数据新闻你只要认真做了,总会带给你一些好的反馈。如果是时效性不强的作品,我就给自己定一个目标,比如说三五天完成,创作这件事情对我来说是一种解压的方式。
第二个好处就是全方位的业务锻炼。第三个优势是创作起来很“爽”。我除了做数据新闻,其他时间都在工作和写论文,相比之下,数据新闻你只要认真做了,总会带给你一些好的反馈。如果是时效性不强的作品,我就给自己定一个目标,比如说三五天完成,创作这件事情对我来说是一种解压的方式。 个人创作也有坏的方面,一是需要自行承担决策后果,包括可视化效果,图怎么做,都需要自己做决定。我的方法是做好一张图后询问长辈是否看得懂。考虑到它的内容语境是新闻,你也能从看不懂的人中得到一些意见,进而得到一个趋势,这个趋势会告诉我数据新闻在更广泛的民间乡野中理解度如何,辅助我接下来图形和可视化的创作。第二个弊端是长期的个人创作,容易陷入瓶颈和窠臼,因此和同行交流尤其重要。
个人创作也有坏的方面,一是需要自行承担决策后果,包括可视化效果,图怎么做,都需要自己做决定。我的方法是做好一张图后询问长辈是否看得懂。考虑到它的内容语境是新闻,你也能从看不懂的人中得到一些意见,进而得到一个趋势,这个趋势会告诉我数据新闻在更广泛的民间乡野中理解度如何,辅助我接下来图形和可视化的创作。第二个弊端是长期的个人创作,容易陷入瓶颈和窠臼,因此和同行交流尤其重要。经验与工具箱
 接下来和大家分享一些经验与工具箱。作为内容创作者,看到一个干净的、结构化的数据库会很开心,但不是所有数据都是最理想的。1月22号开始我就找了各地新闻报道里有没有可以编码的“数据”,类似于传播学当中的内容分析。如果没找到数据,再尝试基于高质量样本库的问卷投放,例如全国或整个省的样本库,而不是基于朋友圈的转发。缺乏数据的时候,可以换一种方式去理解数据——人的身体就是信息。我尝试过将舞蹈进行一个动作检测,再进行绘制。
接下来和大家分享一些经验与工具箱。作为内容创作者,看到一个干净的、结构化的数据库会很开心,但不是所有数据都是最理想的。1月22号开始我就找了各地新闻报道里有没有可以编码的“数据”,类似于传播学当中的内容分析。如果没找到数据,再尝试基于高质量样本库的问卷投放,例如全国或整个省的样本库,而不是基于朋友圈的转发。缺乏数据的时候,可以换一种方式去理解数据——人的身体就是信息。我尝试过将舞蹈进行一个动作检测,再进行绘制。 还有一些流程化的东西,你可以做一些预先设计好的版式,干净的数据集版式会让人心情很好,也帮助梳理逻辑,减少错误。
还有一些流程化的东西,你可以做一些预先设计好的版式,干净的数据集版式会让人心情很好,也帮助梳理逻辑,减少错误。 最后一个工具箱是可视化的方向。可视化也有版式,包括标题、主标题、数据来源,时间紧任务重时,不要求进行多么复杂炫美的操作,有了版式可就以快速成形。
最后一个工具箱是可视化的方向。可视化也有版式,包括标题、主标题、数据来源,时间紧任务重时,不要求进行多么复杂炫美的操作,有了版式可就以快速成形。个人还是团队:前提是找到共识
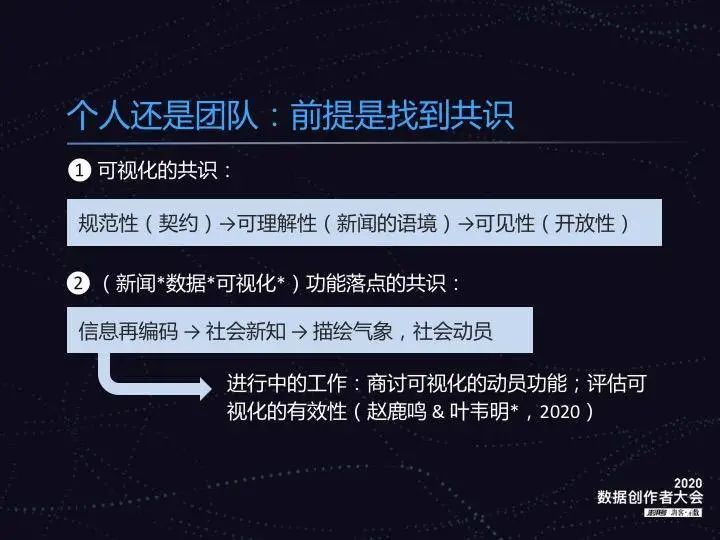 聊到个人创作或团队创作的时候,有一个前提是找到共识。第一是可视化的共识,一方面是它的规范性,相当于一个契约,建立于喜爱数据可视化的同行和读者之上,保证你的图片具有较好的可理解性。比如健康码本身就是一个可视化,卫生间的男女标志也是可视化,所以无论是个人还是团队,都该有对个人功能落点的共识。
聊到个人创作或团队创作的时候,有一个前提是找到共识。第一是可视化的共识,一方面是它的规范性,相当于一个契约,建立于喜爱数据可视化的同行和读者之上,保证你的图片具有较好的可理解性。比如健康码本身就是一个可视化,卫生间的男女标志也是可视化,所以无论是个人还是团队,都该有对个人功能落点的共识。 在功能落点的共识中,第一个阶段是我对文字化信息再编码,吸引大家去看,第二个阶段时是提供一些社会新知,第三个是描绘气象,进行社会动员。当你在疫情期间打开轨迹地图,周围有新的新增病例出现,你和可视化的结果是紧密相连的。这种探讨可以引申到可视化的动员功能,以及什么叫做可视化的有效性。
个人和团队,仅是工作方式与叙事方式的不同
选择个人还是团队要依据选题展开,你想讲的故事一个人可以做下来就没问题,但如果涉及到更多的公共利益,选择合作更好。但所有的导向都基于你的数据内容创作是不是新的,是不是可以被理解的。所以,我接下来的工作会跟几个朋友一起完成,进行一次比较好的数据新闻创作的探索,期待重返“癌症村”作品和大家见面的那天。
 数据工具如何助力选题“出圈”
数据工具如何助力选题“出圈”
天眼查媒体生态事业部总经理 崔梦玲
疫情之下,公开数据的洞察
在2020这样特殊的一年里,天眼查参与了许多与疫情相关的话题报道。今年1月,口罩成为非常重要的抗疫物资。DT财经和天眼查合作,整理口罩产业的数据情况,发现浙江、山东、河北三个省份的口罩企业数量占全国口罩企业的52%,第一时间洞察物资相关的产业布局。
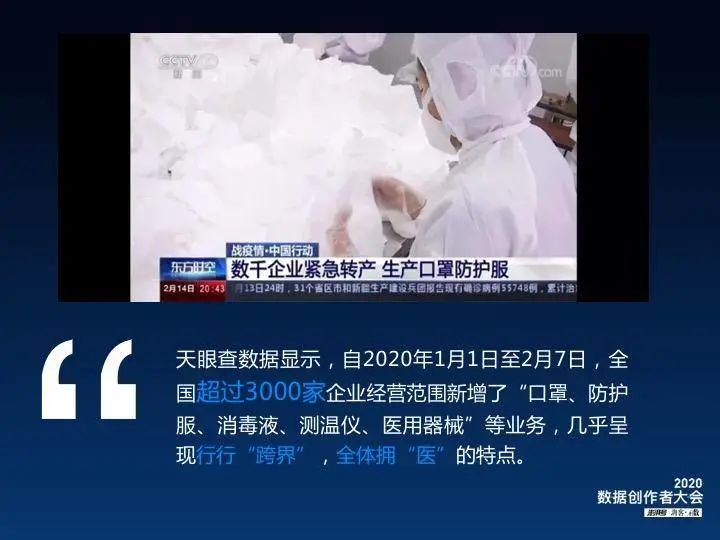
到了2月,疫情进入攻坚阶段,举国上下众志成城,我们发现很多企业都紧急调整生产方向,例如富士康生新增从事医用口罩的生产,比亚迪援产口罩和消毒液,中石化宣布开始生产口罩等。天眼查数据显示,在1个多月的时间里,全国有超过3000家企业进行了经营范围信息变更,跨界生产抗疫物资,呈现出行行“跨界”,全体拥“医”的特点。
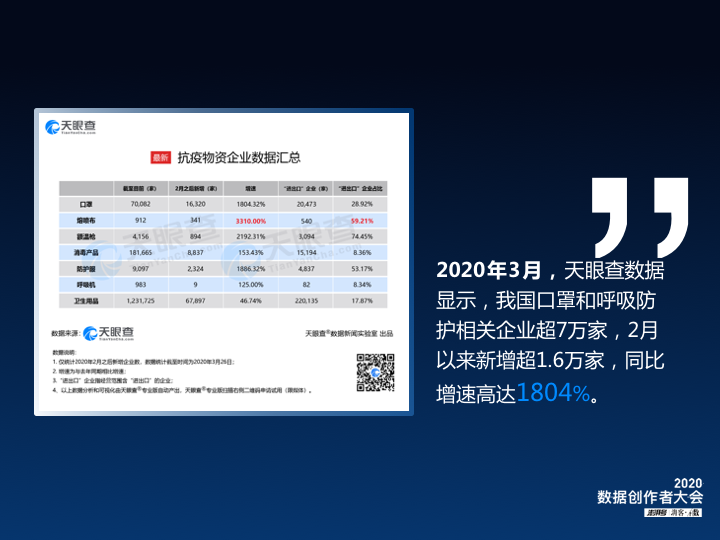 三月份,国内疫情相对缓和,但海外疫情快速蔓延,国内物资重点已从自产转向对外输出。天眼查数据显示,截至3月底,国内生产口罩和呼吸防护相关产品的企业超七万家,比二月份增加了1.6万家,同比增速1804%。
三月份,国内疫情相对缓和,但海外疫情快速蔓延,国内物资重点已从自产转向对外输出。天眼查数据显示,截至3月底,国内生产口罩和呼吸防护相关产品的企业超七万家,比二月份增加了1.6万家,同比增速1804%。通过这三个偏产业相关的数据,可以观察到全行业“跨界拥医”在不同时期的步骤和表现。
为什么数据新闻需要“出圈”?
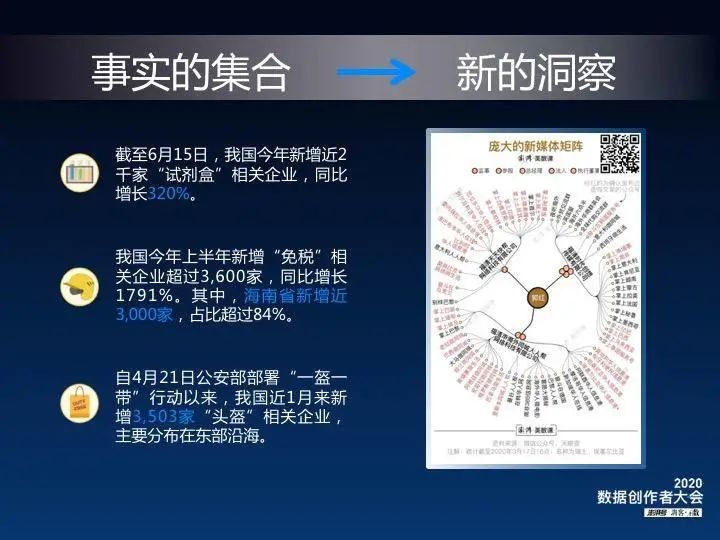 数据新闻为什么需要出圈?因为数据既是事实的集合,又可以收获新的洞察。从数据角度能看到很多事实,比如短短半年内,我国新增3600家“免税”相关企业,超8成位于海南省;数据中又有新的洞察,例如前面澎湃朋友提到的《全球华人“店铺关门有家难回”?假消息是如何批量生产的》报道,就是从数据出发,切片出新的关于谣言制造的洞察。观察是感性的,数据是理性的,我们可以通过数据发现观察背后蕴含的变化、乃至真相。
数据新闻为什么需要出圈?因为数据既是事实的集合,又可以收获新的洞察。从数据角度能看到很多事实,比如短短半年内,我国新增3600家“免税”相关企业,超8成位于海南省;数据中又有新的洞察,例如前面澎湃朋友提到的《全球华人“店铺关门有家难回”?假消息是如何批量生产的》报道,就是从数据出发,切片出新的关于谣言制造的洞察。观察是感性的,数据是理性的,我们可以通过数据发现观察背后蕴含的变化、乃至真相。 数据新闻如何“出圈”
数据新闻怎么做才能“出圈”?一个新闻作品好比一道菜,搬上餐桌前有这么几个过程:种菜、摘菜、洗菜、切菜、炒菜、摆盘、上桌。换算到数据新闻的角度,也对应这样一个过程:将散落在全世界各处的数据收集起来、清洗好,再分析、产品化、可视化等等。
天眼查就是各位数据新闻“厨子”前期操作的好帮手。天眼查专业版,支持从整个宏观数据角度以多种方式组合搜集,区域、行业及时间的不同特征,都可以组合在一起比较。 除了关于公司、各种公开的商业关系之外,我们还可以协助操作宏大的数据选题,洞察宏观经济的发展与变革。例如改革开放40周年时,我们与媒体合作的改革开放40年来企业的发展变迁;我们还与媒体合作了多个区域经济发展相关的选题,例如川渝经济往来情况、两地所有企业的投融资流向等。
 近些年来,天眼查深耕公开的商业数据,目前收录了2.2亿家社会实体,300多种数据维度。
近些年来,天眼查深耕公开的商业数据,目前收录了2.2亿家社会实体,300多种数据维度。 我们的专业化版本也打磨得越来越精细,把以前需要两三天的数据挖掘工作量,做成动两三秒时间就能显示出数据的可视化的专业版,还有多个产业大屏功能,例如经济发展大屏,知识产权大屏,投融资大屏,新基建大屏等等。
我们的专业化版本也打磨得越来越精细,把以前需要两三天的数据挖掘工作量,做成动两三秒时间就能显示出数据的可视化的专业版,还有多个产业大屏功能,例如经济发展大屏,知识产权大屏,投融资大屏,新基建大屏等等。 疫情,让数据从小众走向了大众,背后离不开一个个常年深耕数据报道的专业团队。后续组委会将奉上演讲精华实录第二篇:回看新冠疫情数据报道,听听专业数据新闻团队负责人都是怎么看的。
敬请期待!
*注:演讲内容有所删减。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

